 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet the Agent Steer: Closed-Loop Ranking Optimization via Influence Exchange
Mar 31, 2026Recommendation ranking is fundamentally an influence allocation problem: a sorting formula distributes ranking influence among competing factors, and the business outcome depends on finding the optimal "exchange rates" among them. However, offline proxy metrics systematically misjudge how influence reallocation translates to online impact, with asymmetric bias across metrics that a single calibration factor cannot correct. We present Sortify, the first fully autonomous LLM-driven ranking optimization agent deployed in a large-scale production recommendation system. The agent reframes ranking optimization as continuous influence exchange, closing the full loop from diagnosis to parameter deployment without human intervention. It addresses structural problems through three mechanisms: (1) a dual-channel framework grounded in Savage's Subjective Expected Utility (SEU) that decouples offline-online transfer correction (Belief channel) from constraint penalty adjustment (Preference channel); (2) an LLM meta-controller operating on framework-level parameters rather than low-level search variables; (3) a persistent Memory DB with 7 relational tables for cross-round learning. Its core metric, Influence Share, provides a decomposable measure where all factor contributions sum to exactly 100%. Sortify has been deployed across two markets. In Country A, the agent pushed GMV from -3.6% to +9.2% within 7 rounds with peak orders reaching +12.5%. In Country B, a cold-start deployment achieved +4.15% GMV/UU and +3.58% Ads Revenue in a 7-day A/B test, leading to full production rollout.
Unleashing the Potential of Sparse Attention on Long-term Behaviors for CTR Prediction
Jan 25, 2026In recent years, the success of large language models (LLMs) has driven the exploration of scaling laws in recommender systems. However, models that demonstrate scaling laws are actually challenging to deploy in industrial settings for modeling long sequences of user behaviors, due to the high computational complexity of the standard self-attention mechanism. Despite various sparse self-attention mechanisms proposed in other fields, they are not fully suited for recommendation scenarios. This is because user behaviors exhibit personalization and temporal characteristics: different users have distinct behavior patterns, and these patterns change over time, with data from these users differing significantly from data in other fields in terms of distribution. To address these challenges, we propose SparseCTR, an efficient and effective model specifically designed for long-term behaviors of users. To be precise, we first segment behavior sequences into chunks in a personalized manner to avoid separating continuous behaviors and enable parallel processing of sequences. Based on these chunks, we propose a three-branch sparse self-attention mechanism to jointly identify users' global interests, interest transitions, and short-term interests. Furthermore, we design a composite relative temporal encoding via learnable, head-specific bias coefficients, better capturing sequential and periodic relationships among user behaviors. Extensive experimental results show that SparseCTR not only improves efficiency but also outperforms state-of-the-art methods. More importantly, it exhibits an obvious scaling law phenomenon, maintaining performance improvements across three orders of magnitude in FLOPs. In online A/B testing, SparseCTR increased CTR by 1.72\% and CPM by 1.41\%. Our source code is available at https://github.com/laiweijiang/SparseCTR.
Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory
May 21, 2025



The evaluation of large language models (LLMs) via benchmarks is widespread, yet inconsistencies between different leaderboards and poor separability among top models raise concerns about their ability to accurately reflect authentic model capabilities. This paper provides a critical analysis of benchmark effectiveness, examining main-stream prominent LLM benchmarks using results from diverse models. We first propose a new framework for accurate and reliable estimations of item characteristics and model abilities. Specifically, we propose Pseudo-Siamese Network for Item Response Theory (PSN-IRT), an enhanced Item Response Theory framework that incorporates a rich set of item parameters within an IRT-grounded architecture. Based on PSN-IRT, we conduct extensive analysis which reveals significant and varied shortcomings in the measurement quality of current benchmarks. Furthermore, we demonstrate that leveraging PSN-IRT is able to construct smaller benchmarks while maintaining stronger alignment with human preference.
Enhancing, Refining, and Fusing: Towards Robust Multi-Scale and Dense Ship Detection
Jan 10, 2025



Synthetic aperture radar (SAR) imaging, celebrated for its high resolution, all-weather capability, and day-night operability, is indispensable for maritime applications. However, ship detection in SAR imagery faces significant challenges, including complex backgrounds, densely arranged targets, and large scale variations. To address these issues, we propose a novel framework, Center-Aware SAR Ship Detector (CASS-Det), designed for robust multi-scale and densely packed ship detection. CASS-Det integrates three key innovations: (1) a center enhancement module (CEM) that employs rotational convolution to emphasize ship centers, improving localization while suppressing background interference; (2) a neighbor attention module (NAM) that leverages cross-layer dependencies to refine ship boundaries in densely populated scenes; and (3) a cross-connected feature pyramid network (CC-FPN) that enhances multi-scale feature fusion by integrating shallow and deep features. Extensive experiments on the SSDD, HRSID, and LS-SSDD-v1.0 datasets demonstrate the state-of-the-art performance of CASS-Det, excelling at detecting multi-scale and densely arranged ships.
TBIN: Modeling Long Textual Behavior Data for CTR Prediction
Aug 09, 2023



Click-through rate (CTR) prediction plays a pivotal role in the success of recommendations. Inspired by the recent thriving of language models (LMs), a surge of works improve prediction by organizing user behavior data in a \textbf{textual} format and using LMs to understand user interest at a semantic level. While promising, these works have to truncate the textual data to reduce the quadratic computational overhead of self-attention in LMs. However, it has been studied that long user behavior data can significantly benefit CTR prediction. In addition, these works typically condense user diverse interests into a single feature vector, which hinders the expressive capability of the model. In this paper, we propose a \textbf{T}extual \textbf{B}ehavior-based \textbf{I}nterest Chunking \textbf{N}etwork (TBIN), which tackles the above limitations by combining an efficient locality-sensitive hashing algorithm and a shifted chunk-based self-attention. The resulting user diverse interests are dynamically activated, producing user interest representation towards the target item. Finally, the results of both offline and online experiments on real-world food recommendation platform demonstrate the effectiveness of TBIN.
Cross-Element Combinatorial Selection for Multi-Element Creative in Display Advertising
Jul 04, 2023



The effectiveness of ad creatives is greatly influenced by their visual appearance. Advertising platforms can generate ad creatives with different appearances by combining creative elements provided by advertisers. However, with the increasing number of ad creative elements, it becomes challenging to select a suitable combination from the countless possibilities. The industry's mainstream approach is to select individual creative elements independently, which often overlooks the importance of interaction between creative elements during the modeling process. In response, this paper proposes a Cross-Element Combinatorial Selection framework for multiple creative elements, termed CECS. In the encoder process, a cross-element interaction is adopted to dynamically adjust the expression of a single creative element based on the current candidate creatives. In the decoder process, the creative combination problem is transformed into a cascade selection problem of multiple creative elements. A pointer mechanism with a cascade design is used to model the associations among candidates. Comprehensive experiments on real-world datasets show that CECS achieved the SOTA score on offline metrics. Moreover, the CECS algorithm has been deployed in our industrial application, resulting in a significant 6.02% CTR and 10.37% GMV lift, which is beneficial to the business.
Knowledge Soft Integration for Multimodal Recommendation
May 12, 2023

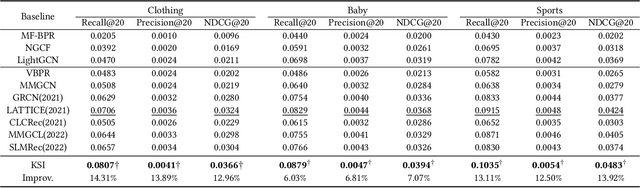

One of the main challenges in modern recommendation systems is how to effectively utilize multimodal content to achieve more personalized recommendations. Despite various proposed solutions, most of them overlook the mismatch between the knowledge gained from independent feature extraction processes and downstream recommendation tasks. Specifically, multimodal feature extraction processes do not incorporate prior knowledge relevant to recommendation tasks, while recommendation tasks often directly use these multimodal features as side information. This mismatch can lead to model fitting biases and performance degradation, which this paper refers to as the \textit{curse of knowledge} problem. To address this issue, we propose using knowledge soft integration to balance the utilization of multimodal features and the curse of knowledge problem it brings about. To achieve this, we put forward a Knowledge Soft Integration framework for the multimodal recommendation, abbreviated as KSI, which is composed of the Structure Efficiently Injection (SEI) module and the Semantic Soft Integration (SSI) module. In the SEI module, we model the modality correlation between items using Refined Graph Neural Network (RGNN), and introduce a regularization term to reduce the redundancy of user/item representations. In the SSI module, we design a self-supervised retrieval task to further indirectly integrate the semantic knowledge of multimodal features, and enhance the semantic discrimination of item representations. Extensive experiments on three benchmark datasets demonstrate the superiority of KSI and validate the effectiveness of its two modules.
A Deep Behavior Path Matching Network for Click-Through Rate Prediction
Feb 01, 2023



User behaviors on an e-commerce app not only contain different kinds of feedback on items but also sometimes imply the cognitive clue of the user's decision-making. For understanding the psychological procedure behind user decisions, we present the behavior path and propose to match the user's current behavior path with historical behavior paths to predict user behaviors on the app. Further, we design a deep neural network for behavior path matching and solve three difficulties in modeling behavior paths: sparsity, noise interference, and accurate matching of behavior paths. In particular, we leverage contrastive learning to augment user behavior paths, provide behavior path self-activation to alleviate the effect of noise, and adopt a two-level matching mechanism to identify the most appropriate candidate. Our model shows excellent performance on two real-world datasets, outperforming the state-of-the-art CTR model. Moreover, our model has been deployed on the Meituan food delivery platform and has accumulated 1.6% improvement in CTR and 1.8% improvement in advertising revenue.
Decision-Making Context Interaction Network for Click-Through Rate Prediction
Jan 29, 2023



Click-through rate (CTR) prediction is crucial in recommendation and online advertising systems. Existing methods usually model user behaviors, while ignoring the informative context which influences the user to make a click decision, e.g., click pages and pre-ranking candidates that inform inferences about user interests, leading to suboptimal performance. In this paper, we propose a Decision-Making Context Interaction Network (DCIN), which deploys a carefully designed Context Interaction Unit (CIU) to learn decision-making contexts and thus benefits CTR prediction. In addition, the relationship between different decision-making context sources is explored by the proposed Adaptive Interest Aggregation Unit (AIAU) to improve CTR prediction further. In the experiments on public and industrial datasets, DCIN significantly outperforms the state-of-the-art methods. Notably, the model has obtained the improvement of CTR+2.9%/CPM+2.1%/GMV+1.5% for online A/B testing and served the main traffic of Meituan Waimai advertising system.
RepGhost: A Hardware-Efficient Ghost Module via Re-parameterization
Nov 11, 2022



Feature reuse has been a key technique in light-weight convolutional neural networks (CNNs) design. Current methods usually utilize a concatenation operator to keep large channel numbers cheaply (thus large network capacity) by reusing feature maps from other layers. Although concatenation is parameters- and FLOPs-free, its computational cost on hardware devices is non-negligible. To address this, this paper provides a new perspective to realize feature reuse via structural re-parameterization technique. A novel hardware-efficient RepGhost module is proposed for implicit feature reuse via re-parameterization, instead of using concatenation operator. Based on the RepGhost module, we develop our efficient RepGhost bottleneck and RepGhostNet. Experiments on ImageNet and COCO benchmarks demonstrate that the proposed RepGhostNet is much more effective and efficient than GhostNet and MobileNetV3 on mobile devices. Specially, our RepGhostNet surpasses GhostNet 0.5x by 2.5% Top-1 accuracy on ImageNet dataset with less parameters and comparable latency on an ARM-based mobile phone.