 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepGhost: A Hardware-Efficient Ghost Module via Re-parameterization
Nov 11, 2022



Feature reuse has been a key technique in light-weight convolutional neural networks (CNNs) design. Current methods usually utilize a concatenation operator to keep large channel numbers cheaply (thus large network capacity) by reusing feature maps from other layers. Although concatenation is parameters- and FLOPs-free, its computational cost on hardware devices is non-negligible. To address this, this paper provides a new perspective to realize feature reuse via structural re-parameterization technique. A novel hardware-efficient RepGhost module is proposed for implicit feature reuse via re-parameterization, instead of using concatenation operator. Based on the RepGhost module, we develop our efficient RepGhost bottleneck and RepGhostNet. Experiments on ImageNet and COCO benchmarks demonstrate that the proposed RepGhostNet is much more effective and efficient than GhostNet and MobileNetV3 on mobile devices. Specially, our RepGhostNet surpasses GhostNet 0.5x by 2.5% Top-1 accuracy on ImageNet dataset with less parameters and comparable latency on an ARM-based mobile phone.
Controllable Face Aging
Dec 20, 2019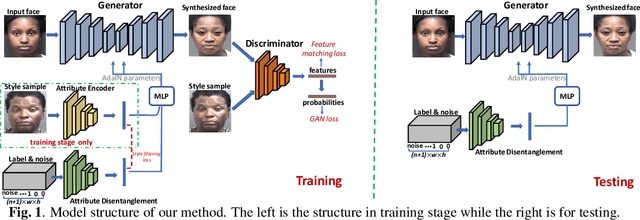
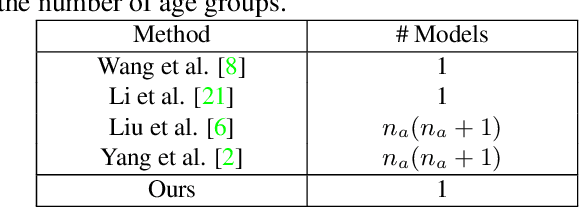
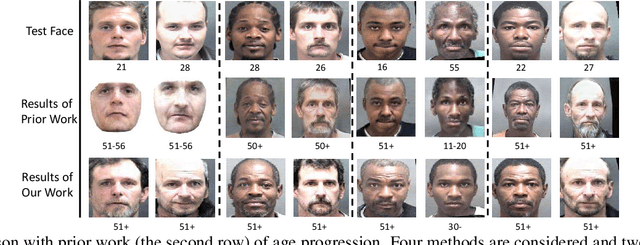
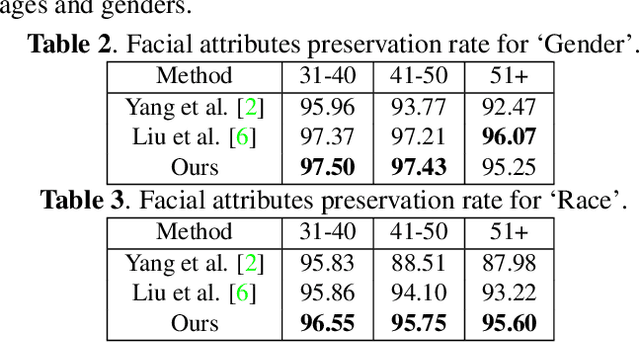
Motivated by the following two observations: 1) people are aging differently under different conditions for changeable facial attributes, e.g., skin color may become darker when working outside, and 2) it needs to keep some unchanged facial attributes during the aging process, e.g., race and gender, we propose a controllable face aging method via attribute disentanglement generative adversarial network. To offer fine control over the synthesized face images, first, an individual embedding of the face is directly learned from an image that contains the desired facial attribute. Second, since the image may contain other unwanted attributes, an attribute disentanglement network is used to separate the individual embedding and learn the common embedding that contains information about the face attribute (e.g., race). With the common embedding, we can manipulate the generated face image with the desired attribute in an explicit manner. Experimental results on two common benchmarks demonstrate that our proposed generator achieves comparable performance on the aging effect with state-of-the-art baselines while gaining more flexibility for attribute control. Code is available at supplementary material.
Modal-aware Features for Multimodal Hashing
Nov 19, 2019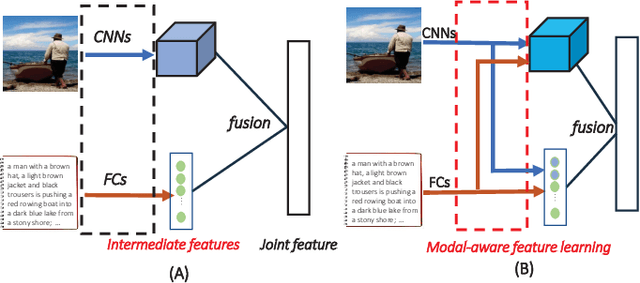


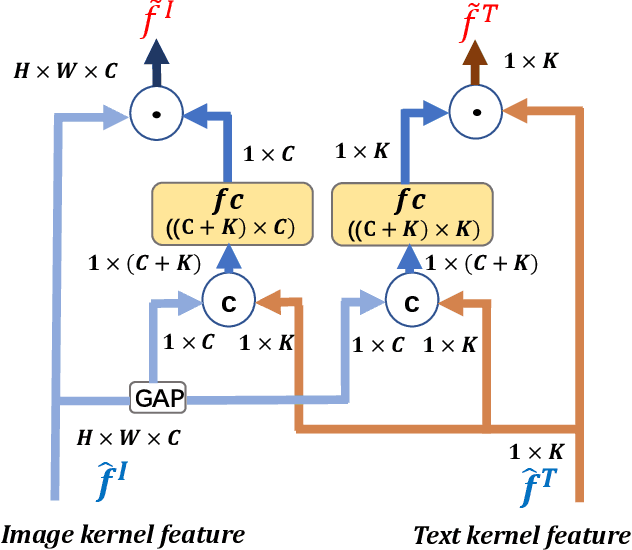
Many retrieval applications can benefit from multiple modalities, e.g., text that contains images on Wikipedia, for which how to represent multimodal data is the critical component. Most deep multimodal learning methods typically involve two steps to construct the joint representations: 1) learning of multiple intermediate features, with each intermediate feature corresponding to a modality, using separate and independent deep models; 2) merging the intermediate features into a joint representation using a fusion strategy. However, in the first step, these intermediate features do not have previous knowledge of each other and cannot fully exploit the information contained in the other modalities. In this paper, we present a modal-aware operation as a generic building block to capture the non-linear dependences among the heterogeneous intermediate features that can learn the underlying correlation structures in other multimodal data as soon as possible. The modal-aware operation consists of a kernel network and an attention network. The kernel network is utilized to learn the non-linear relationships with other modalities. Then, to learn better representations for binary hash codes, we present an attention network that finds the informative regions of these modal-aware features that are favorable for retrieval. Experiments conducted on three public benchmark datasets demonstrate significant improvements in the performance of our method relative to state-of-the-art methods.
Simultaneous Region Localization and Hash Coding for Fine-grained Image Retrieval
Nov 19, 2019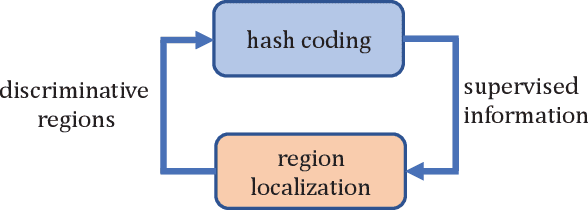
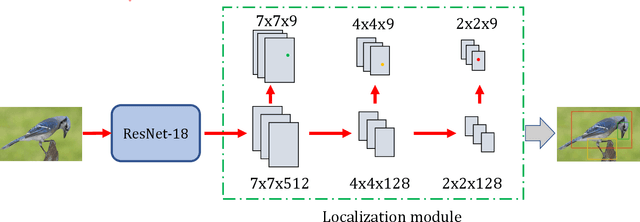
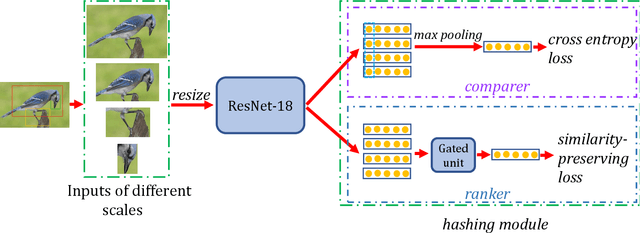
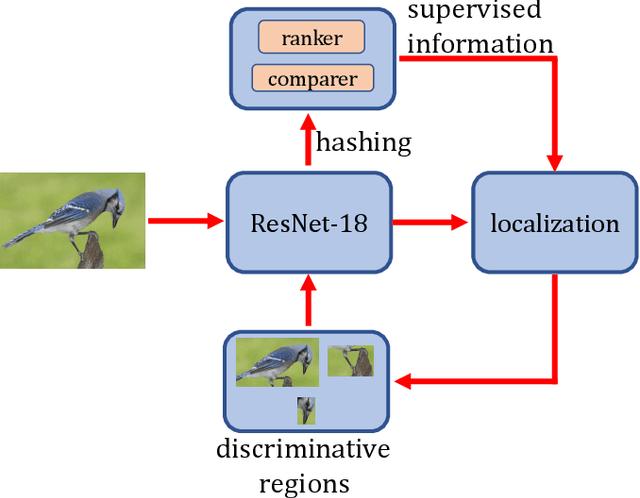
Fine-grained image hashing is a challenging problem due to the difficulties of discriminative region localization and hash code generation. Most existing deep hashing approaches solve the two tasks independently. While these two tasks are correlated and can reinforce each other. In this paper, we propose a deep fine-grained hashing to simultaneously localize the discriminative regions and generate the efficient binary codes. The proposed approach consists of a region localization module and a hash coding module. The region localization module aims to provide informative regions to the hash coding module. The hash coding module aims to generate effective binary codes and give feedback for learning better localizer. Moreover, to better capture subtle differences, multi-scale regions at different layers are learned without the need of bounding-box/part annotations. Extensive experiments are conducted on two public benchmark fine-grained datasets. The results demonstrate significant improvements in the performance of our method relative to other fine-grained hashing algorithms.