 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepGhost: A Hardware-Efficient Ghost Module via Re-parameterization
Nov 11, 2022



Feature reuse has been a key technique in light-weight convolutional neural networks (CNNs) design. Current methods usually utilize a concatenation operator to keep large channel numbers cheaply (thus large network capacity) by reusing feature maps from other layers. Although concatenation is parameters- and FLOPs-free, its computational cost on hardware devices is non-negligible. To address this, this paper provides a new perspective to realize feature reuse via structural re-parameterization technique. A novel hardware-efficient RepGhost module is proposed for implicit feature reuse via re-parameterization, instead of using concatenation operator. Based on the RepGhost module, we develop our efficient RepGhost bottleneck and RepGhostNet. Experiments on ImageNet and COCO benchmarks demonstrate that the proposed RepGhostNet is much more effective and efficient than GhostNet and MobileNetV3 on mobile devices. Specially, our RepGhostNet surpasses GhostNet 0.5x by 2.5% Top-1 accuracy on ImageNet dataset with less parameters and comparable latency on an ARM-based mobile phone.
Pixel-Wise Contrastive Distillation
Nov 01, 2022We present the first pixel-level self-supervised distillation framework specified for dense prediction tasks. Our approach, called Pixel-Wise Contrastive Distillation (PCD), distills knowledge by attracting the corresponding pixels from student's and teacher's output feature maps. This pixel-to-pixel distillation demands for maintaining the spatial information of teacher's output. We propose a SpatialAdaptor that adapts the well-trained projection/prediction head of the teacher used to encode vectorized features to processing 2D feature maps. SpatialAdaptor enables more informative pixel-level distillation, yielding a better student for dense prediction tasks. Besides, in light of the inadequate effective receptive fields of small models, we utilize a plug-in multi-head self-attention module to explicitly relate the pixels of student's feature maps. Overall, our PCD outperforms previous self-supervised distillation methods on various dense prediction tasks. A backbone of ResNet-18 distilled by PCD achieves $37.4$ AP$^\text{bbox}$ and $34.0$ AP$^{mask}$ with Mask R-CNN detector on COCO dataset, emerging as the first pre-training method surpassing the supervised pre-trained counterpart.
Angle-based Search Space Shrinking for Neural Architecture Search
May 01, 2020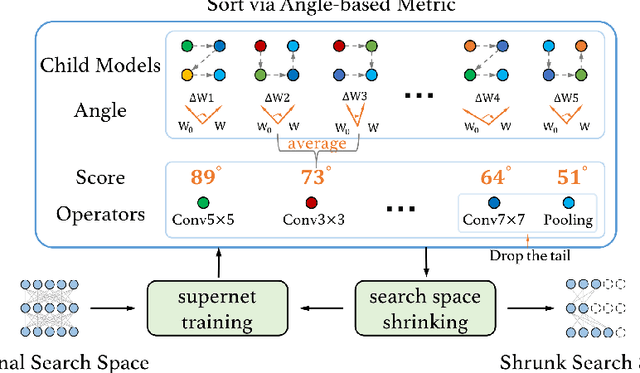


In this work, we present a simple and general search space shrinking method, called Angle-Based search space Shrinking (ABS), for Neural Architecture Search (NAS). Our approach progressively simplifies the original search space by dropping unpromising candidates, thus can reduce difficulties for existing NAS methods to find superior architectures. In particular, we propose an angle-based metric to guide the shrinking process. We provide comprehensive evidences showing that, in weight-sharing supernet, the proposed metric is more stable and accurate than accuracy-based and magnitude-based metrics to predict the capability of child models. We also show that the angle-based metric can converge fast while training supernet, enabling us to get promising shrunk search spaces efficiently. ABS can easily apply to most of popular NAS approaches (e.g. SPOS, FariNAS, ProxylessNAS, DARTS and PDARTS). Comprehensive experiments show that ABS can dramatically enhance existing NAS approaches by providing a promising shrunk search space.
Dynamic Region-Aware Convolution
Mar 27, 2020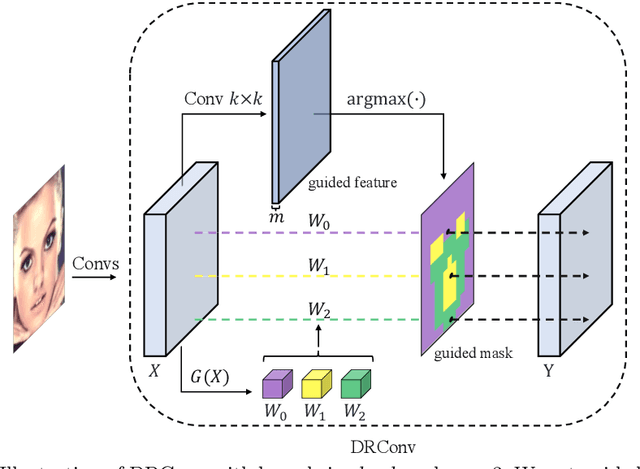
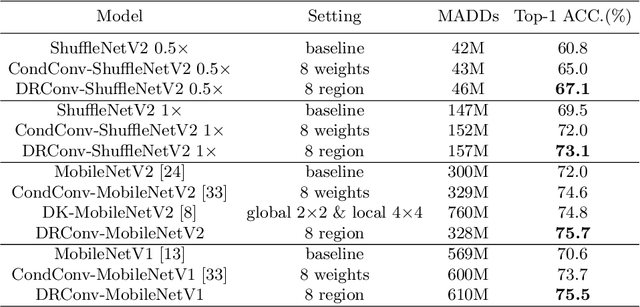
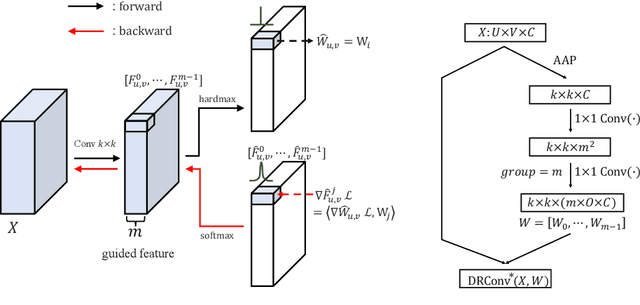

We propose a new convolution called Dynamic Region-Aware Convolution (DRConv), which can automatically assign multiple filters to corresponding spatial regions where features have similar representation. In this way, DRConv outperforms standard convolution in modeling semantic variations. Standard convolution can increase the number of channels to extract more visual elements but results in high computational cost. More gracefully, our DRConv transfers the increasing channel-wise filters to spatial dimension with learnable instructor, which significantly improves representation ability of convolution and maintains translation-invariance like standard convolution. DRConv is an effective and elegant method for handling complex and variable spatial information distribution. It can substitute standard convolution in any existing networks for its plug-and-play property. We evaluate DRConv on a wide range of models (MobileNet series, ShuffleNetV2, etc.) and tasks (Classification, Face Recognition, Detection and Segmentation.). On ImageNet classification, DRConv-based ShuffleNetV2-0.5x achieves state-of-the-art performance of 67.1% at 46M multiply-adds level with 6.3% relative improvement.
Single Path One-Shot Neural Architecture Search with Uniform Sampling
Apr 06, 2019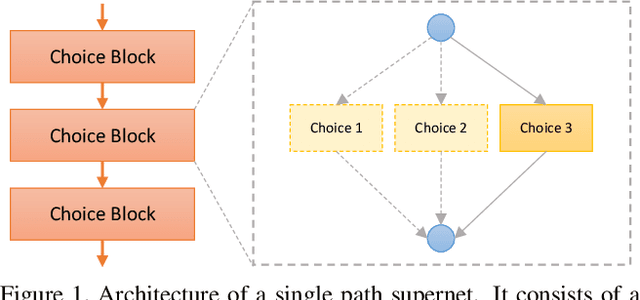
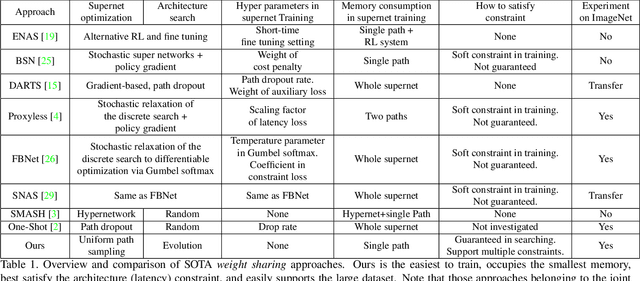
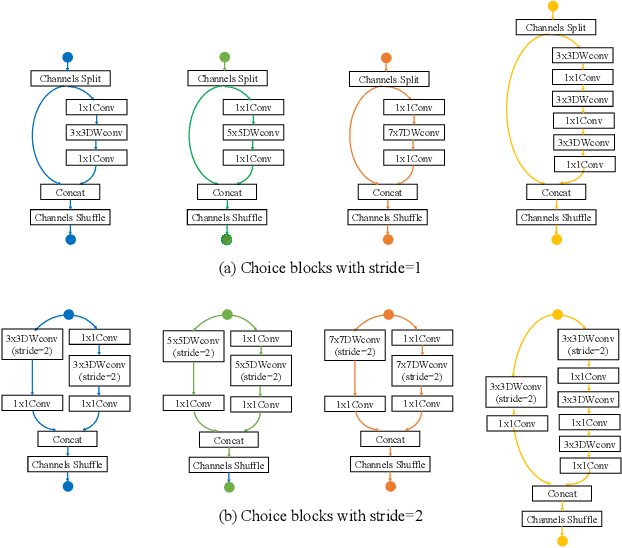
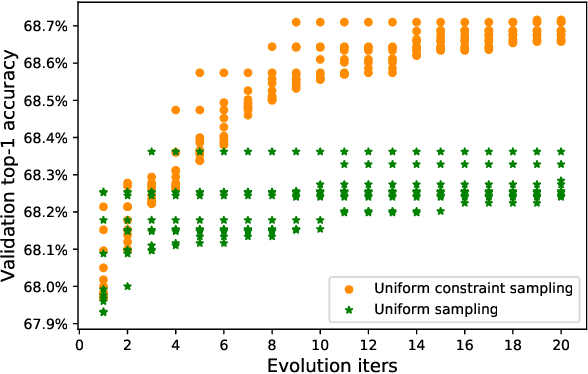
One-shot method is a powerful Neural Architecture Search (NAS) framework, but its training is non-trivial and it is difficult to achieve competitive results on large scale datasets like ImageNet. In this work, we propose a Single Path One-Shot model to address its main challenge in the training. Our central idea is to construct a simplified supernet, Single Path Supernet, which is trained by an uniform path sampling method. All underlying architectures (and their weights) get trained fully and equally. Once we have a trained supernet, we apply an evolutionary algorithm to efficiently search the best-performing architectures without any fine tuning. Comprehensive experiments verify that our approach is flexible and effective. It is easy to train and fast to search. It effortlessly supports complex search spaces (e.g., building blocks, channel, mixed-precision quantization) and different search constraints (e.g., FLOPs, latency). It is thus convenient to use for various needs. It achieves start-of-the-art performance on the large dataset ImageNet.
MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning
Apr 03, 2019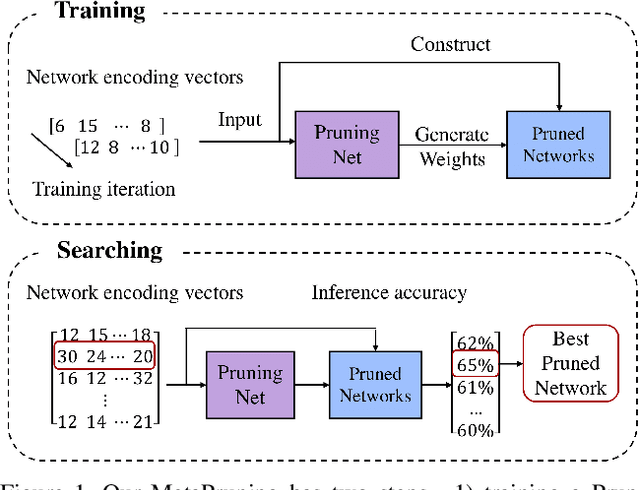
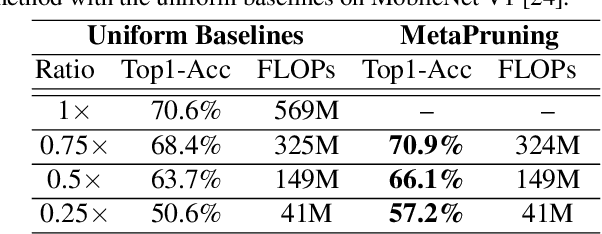
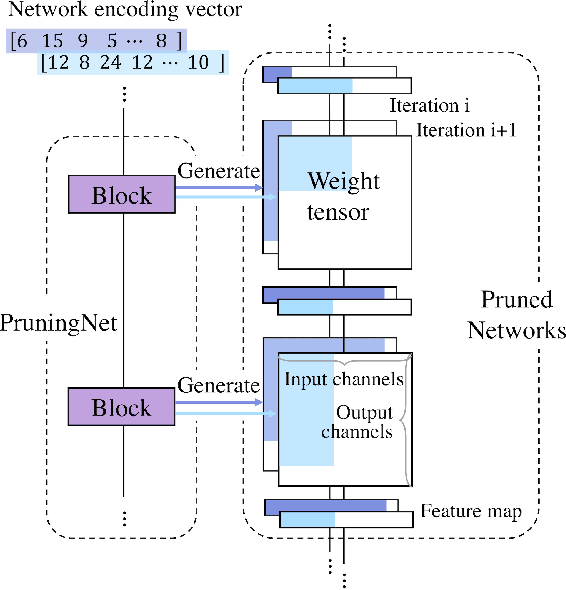
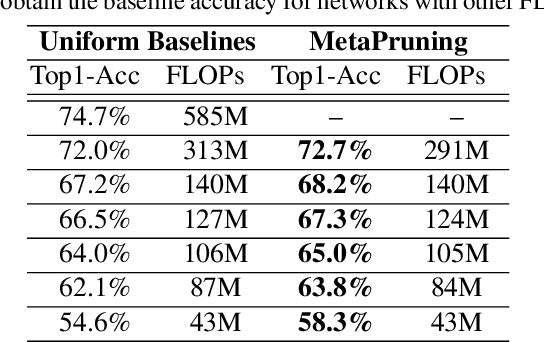
In this paper, we propose a novel meta learning approach for automatic channel pruning of very deep neural networks. We first train a PruningNet, a kind of meta network, which is able to generate weight parameters for any pruned structure given the target network. We use a simple stochastic structure sampling method for training the PruningNet. Then, we apply an evolutionary procedure to search for good-performing pruned networks. The search is highly efficient because the weights are directly generated by the trained PruningNet and we do not need any finetuning. With a single PruningNet trained for the target network, we can search for various Pruned Networks under different constraints with little human participation. We have demonstrated competitive performances on MobileNet V1/V2 networks, up to 9.0/9.9 higher ImageNet accuracy than V1/V2. Compared to the previous state-of-the-art AutoML-based pruning methods, like AMC and NetAdapt, we achieve higher or comparable accuracy under various conditions.