 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Region-Aware Convolution
Paper and Code
Mar 27, 2020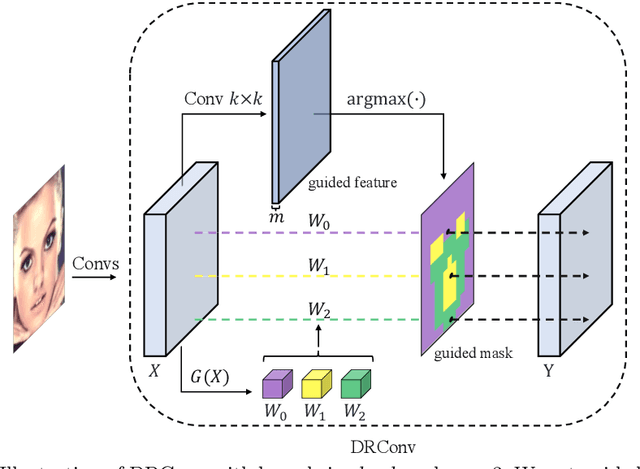
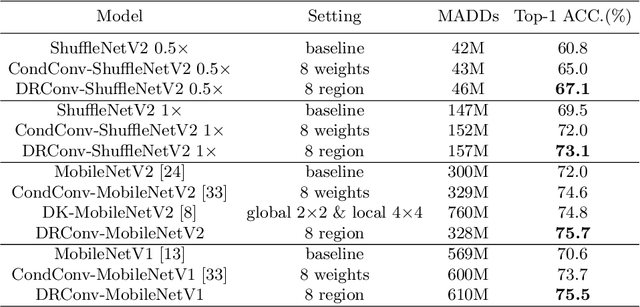
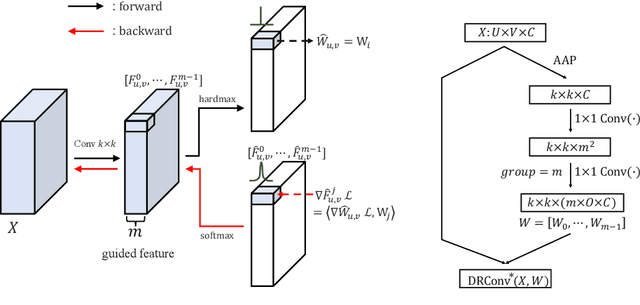

We propose a new convolution called Dynamic Region-Aware Convolution (DRConv), which can automatically assign multiple filters to corresponding spatial regions where features have similar representation. In this way, DRConv outperforms standard convolution in modeling semantic variations. Standard convolution can increase the number of channels to extract more visual elements but results in high computational cost. More gracefully, our DRConv transfers the increasing channel-wise filters to spatial dimension with learnable instructor, which significantly improves representation ability of convolution and maintains translation-invariance like standard convolution. DRConv is an effective and elegant method for handling complex and variable spatial information distribution. It can substitute standard convolution in any existing networks for its plug-and-play property. We evaluate DRConv on a wide range of models (MobileNet series, ShuffleNetV2, etc.) and tasks (Classification, Face Recognition, Detection and Segmentation.). On ImageNet classification, DRConv-based ShuffleNetV2-0.5x achieves state-of-the-art performance of 67.1% at 46M multiply-adds level with 6.3% relative improvement.