 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBABE: Biology Arena BEnchmark
Feb 05, 2026The rapid evolution of large language models (LLMs) has expanded their capabilities from basic dialogue to advanced scientific reasoning. However, existing benchmarks in biology often fail to assess a critical skill required of researchers: the ability to integrate experimental results with contextual knowledge to derive meaningful conclusions. To address this gap, we introduce BABE(Biology Arena BEnchmark), a comprehensive benchmark designed to evaluate the experimental reasoning capabilities of biological AI systems. BABE is uniquely constructed from peer-reviewed research papers and real-world biological studies, ensuring that tasks reflect the complexity and interdisciplinary nature of actual scientific inquiry. BABE challenges models to perform causal reasoning and cross-scale inference. Our benchmark provides a robust framework for assessing how well AI systems can reason like practicing scientists, offering a more authentic measure of their potential to contribute to biological research.
Retrieval-Infused Reasoning Sandbox: A Benchmark for Decoupling Retrieval and Reasoning Capabilities
Jan 29, 2026Despite strong performance on existing benchmarks, it remains unclear whether large language models can reason over genuinely novel scientific information. Most evaluations score end-to-end RAG pipelines, where reasoning is confounded with retrieval and toolchain choices, and the signal is further contaminated by parametric memorization and open-web volatility. We introduce DeR2, a controlled deep-research sandbox that isolates document-grounded reasoning while preserving core difficulties of deep search: multi-step synthesis, denoising, and evidence-based conclusion making. DeR2 decouples evidence access from reasoning via four regimes--Instruction-only, Concepts (gold concepts without documents), Related-only (only relevant documents), and Full-set (relevant documents plus topically related distractors)--yielding interpretable regime gaps that operationalize retrieval loss vs. reasoning loss and enable fine-grained error attribution. To prevent parametric leakage, we apply a two-phase validation that requires parametric failure without evidence while ensuring oracle-concept solvability. To ensure reproducibility, each instance provides a frozen document library (drawn from 2023-2025 theoretical papers) with expert-annotated concepts and validated rationales. Experiments across a diverse set of state-of-the-art foundation models reveal substantial variation and significant headroom: some models exhibit mode-switch fragility, performing worse with the Full-set than with Instruction-only, while others show structural concept misuse, correctly naming concepts but failing to execute them as procedures.
WholeBodyVLA: Towards Unified Latent VLA for Whole-Body Loco-Manipulation Control
Dec 15, 2025Humanoid robots require precise locomotion and dexterous manipulation to perform challenging loco-manipulation tasks. Yet existing approaches, modular or end-to-end, are deficient in manipulation-aware locomotion. This confines the robot to a limited workspace, preventing it from performing large-space loco-manipulation. We attribute this to: (1) the challenge of acquiring loco-manipulation knowledge due to the scarcity of humanoid teleoperation data, and (2) the difficulty of faithfully and reliably executing locomotion commands, stemming from the limited precision and stability of existing RL controllers. To acquire richer loco-manipulation knowledge, we propose a unified latent learning framework that enables Vision-Language-Action (VLA) system to learn from low-cost action-free egocentric videos. Moreover, an efficient human data collection pipeline is devised to augment the dataset and scale the benefits. To execute the desired locomotion commands more precisely, we present a loco-manipulation-oriented (LMO) RL policy specifically tailored for accurate and stable core loco-manipulation movements, such as advancing, turning, and squatting. Building on these components, we introduce WholeBodyVLA, a unified framework for humanoid loco-manipulation. To the best of our knowledge, WholeBodyVLA is one of its kind enabling large-space humanoid loco-manipulation. It is verified via comprehensive experiments on the AgiBot X2 humanoid, outperforming prior baseline by 21.3%. It also demonstrates strong generalization and high extensibility across a broad range of tasks.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Beyond the Seen: Bounded Distribution Estimation for Open-Vocabulary Learning
Oct 06, 2025



Open-vocabulary learning requires modeling the data distribution in open environments, which consists of both seen-class and unseen-class data. Existing methods estimate the distribution in open environments using seen-class data, where the absence of unseen classes makes the estimation error inherently unidentifiable. Intuitively, learning beyond the seen classes is crucial for distribution estimation to bound the estimation error. We theoretically demonstrate that the distribution can be effectively estimated by generating unseen-class data, through which the estimation error is upper-bounded. Building on this theoretical insight, we propose a novel open-vocabulary learning method, which generates unseen-class data for estimating the distribution in open environments. The method consists of a class-domain-wise data generation pipeline and a distribution alignment algorithm. The data generation pipeline generates unseen-class data under the guidance of a hierarchical semantic tree and domain information inferred from the seen-class data, facilitating accurate distribution estimation. With the generated data, the distribution alignment algorithm estimates and maximizes the posterior probability to enhance generalization in open-vocabulary learning. Extensive experiments on $11$ datasets demonstrate that our method outperforms baseline approaches by up to $14\%$, highlighting its effectiveness and superiority.
Is Diversity All You Need for Scalable Robotic Manipulation?
Jul 08, 2025Data scaling has driven remarkable success in foundation models for Natural Language Processing (NLP) and Computer Vision (CV), yet the principles of effective data scaling in robotic manipulation remain insufficiently understood. In this work, we investigate the nuanced role of data diversity in robot learning by examining three critical dimensions-task (what to do), embodiment (which robot to use), and expert (who demonstrates)-challenging the conventional intuition of "more diverse is better". Throughout extensive experiments on various robot platforms, we reveal that (1) task diversity proves more critical than per-task demonstration quantity, benefiting transfer from diverse pre-training tasks to novel downstream scenarios; (2) multi-embodiment pre-training data is optional for cross-embodiment transfer-models trained on high-quality single-embodiment data can efficiently transfer to different platforms, showing more desirable scaling property during fine-tuning than multi-embodiment pre-trained models; and (3) expert diversity, arising from individual operational preferences and stochastic variations in human demonstrations, can be confounding to policy learning, with velocity multimodality emerging as a key contributing factor. Based on this insight, we propose a distribution debiasing method to mitigate velocity ambiguity, the yielding GO-1-Pro achieves substantial performance gains of 15%, equivalent to using 2.5 times pre-training data. Collectively, these findings provide new perspectives and offer practical guidance on how to scale robotic manipulation datasets effectively.
Detection of Breast Cancer Lumpectomy Margin with SAM-incorporated Forward-Forward Contrastive Learning
Jun 26, 2025Complete removal of cancer tumors with a negative specimen margin during lumpectomy is essential in reducing breast cancer recurrence. However, 2D specimen radiography (SR), the current method used to assess intraoperative specimen margin status, has limited accuracy, resulting in nearly a quarter of patients requiring additional surgery. To address this, we propose a novel deep learning framework combining the Segment Anything Model (SAM) with Forward-Forward Contrastive Learning (FFCL), a pre-training strategy leveraging both local and global contrastive learning for patch-level classification of SR images. After annotating SR images with regions of known maligancy, non-malignant tissue, and pathology-confirmed margins, we pre-train a ResNet-18 backbone with FFCL to classify margin status, then reconstruct coarse binary masks to prompt SAM for refined tumor margin segmentation. Our approach achieved an AUC of 0.8455 for margin classification and segmented margins with a 27.4% improvement in Dice similarity over baseline models, while reducing inference time to 47 milliseconds per image. These results demonstrate that FFCL-SAM significantly enhances both the speed and accuracy of intraoperative margin assessment, with strong potential to reduce re-excision rates and improve surgical outcomes in breast cancer treatment. Our code is available at https://github.com/tbwa233/FFCL-SAM/.
NDCG-Consistent Softmax Approximation with Accelerated Convergence
Jun 11, 2025
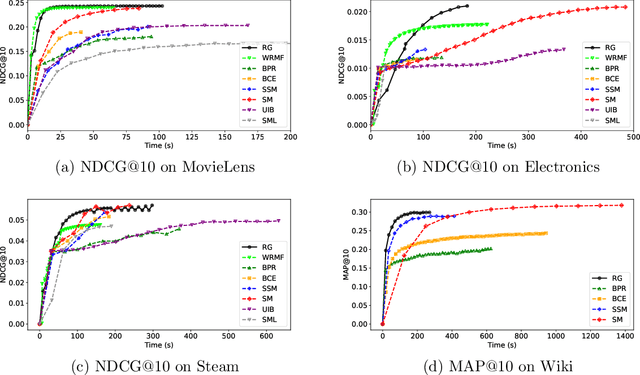

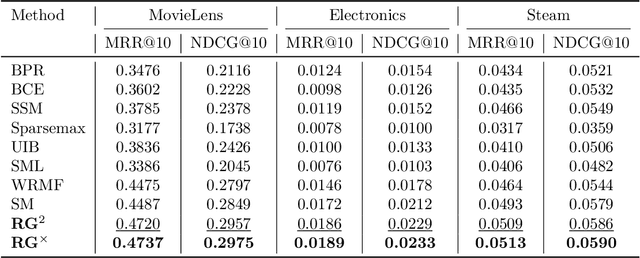
Ranking tasks constitute fundamental components of extreme similarity learning frameworks, where extremely large corpora of objects are modeled through relative similarity relationships adhering to predefined ordinal structures. Among various ranking surrogates, Softmax (SM) Loss has been widely adopted due to its natural capability to handle listwise ranking via global negative comparisons, along with its flexibility across diverse application scenarios. However, despite its effectiveness, SM Loss often suffers from significant computational overhead and scalability limitations when applied to large-scale object spaces. To address this challenge, we propose novel loss formulations that align directly with ranking metrics: the Ranking-Generalizable \textbf{squared} (RG$^2$) Loss and the Ranking-Generalizable interactive (RG$^\times$) Loss, both derived through Taylor expansions of the SM Loss. Notably, RG$^2$ reveals the intrinsic mechanisms underlying weighted squared losses (WSL) in ranking methods and uncovers fundamental connections between sampling-based and non-sampling-based loss paradigms. Furthermore, we integrate the proposed RG losses with the highly efficient Alternating Least Squares (ALS) optimization method, providing both generalization guarantees and convergence rate analyses. Empirical evaluations on real-world datasets demonstrate that our approach achieves comparable or superior ranking performance relative to SM Loss, while significantly accelerating convergence. This framework offers the similarity learning community both theoretical insights and practically efficient tools, with methodologies applicable to a broad range of tasks where balancing ranking quality and computational efficiency is essential.
VUDG: A Dataset for Video Understanding Domain Generalization
May 30, 2025Video understanding has made remarkable progress in recent years, largely driven by advances in deep models and the availability of large-scale annotated datasets. However, existing works typically ignore the inherent domain shifts encountered in real-world video applications, leaving domain generalization (DG) in video understanding underexplored. Hence, we propose Video Understanding Domain Generalization (VUDG), a novel dataset designed specifically for evaluating the DG performance in video understanding. VUDG contains videos from 11 distinct domains that cover three types of domain shifts, and maintains semantic similarity across different domains to ensure fair and meaningful evaluation. We propose a multi-expert progressive annotation framework to annotate each video with both multiple-choice and open-ended question-answer pairs. Extensive experiments on 9 representative large video-language models (LVLMs) and several traditional video question answering methods show that most models (including state-of-the-art LVLMs) suffer performance degradation under domain shifts. These results highlight the challenges posed by VUDG and the difference in the robustness of current models to data distribution shifts. We believe VUDG provides a valuable resource for prompting future research in domain generalization video understanding.
LLM-driven Effective Knowledge Tracing by Integrating Dual-channel Difficulty
Feb 27, 2025Knowledge Tracing (KT) is a fundamental technology in intelligent tutoring systems used to simulate changes in students' knowledge state during learning, track personalized knowledge mastery, and predict performance. However, current KT models face three major challenges: (1) When encountering new questions, models face cold-start problems due to sparse interaction records, making precise modeling difficult; (2) Traditional models only use historical interaction records for student personalization modeling, unable to accurately track individual mastery levels, resulting in unclear personalized modeling; (3) The decision-making process is opaque to educators, making it challenging for them to understand model judgments. To address these challenges, we propose a novel Dual-channel Difficulty-aware Knowledge Tracing (DDKT) framework that utilizes Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) for subjective difficulty assessment, while integrating difficulty bias-aware algorithms and student mastery algorithms for precise difficulty measurement. Our framework introduces three key innovations: (1) Difficulty Balance Perception Sequence (DBPS) - students' subjective perceptions combined with objective difficulty, measuring gaps between LLM-assessed difficulty, mathematical-statistical difficulty, and students' subjective perceived difficulty through attention mechanisms; (2) Difficulty Mastery Ratio (DMR) - precise modeling of student mastery levels through different difficulty zones; (3) Knowledge State Update Mechanism - implementing personalized knowledge acquisition through gated networks and updating student knowledge state. Experimental results on two real datasets show our method consistently outperforms nine baseline models, improving AUC metrics by 2% to 10% while effectively addressing cold-start problems and enhancing model interpretability.