 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Transfer Learning Framework for Cross-Domain Click-Through Rate Prediction
Aug 29, 2024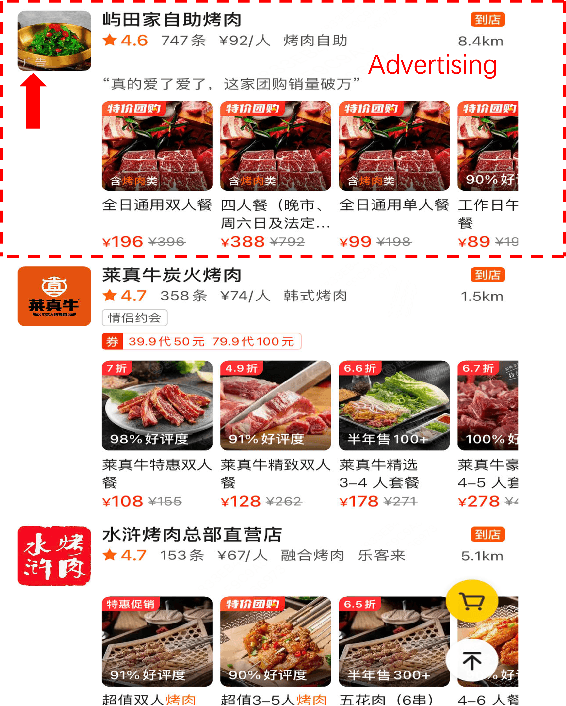
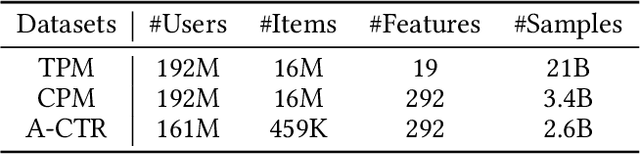
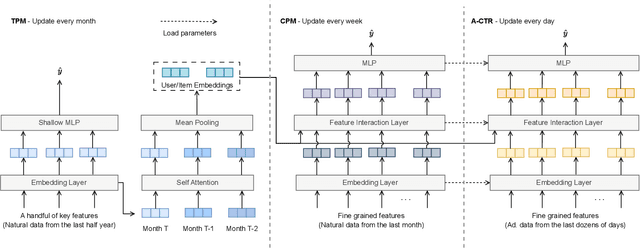
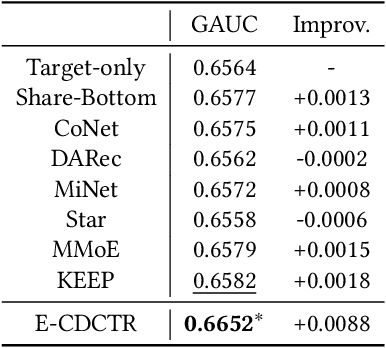
Natural content and advertisement coexist in industrial recommendation systems but differ in data distribution. Concretely, traffic related to the advertisement is considerably sparser compared to that of natural content, which motivates the development of transferring knowledge from the richer source natural content domain to the sparser advertising domain. The challenges include the inefficiencies arising from the management of extensive source data and the problem of 'catastrophic forgetting' that results from the CTR model's daily updating. To this end, we propose a novel tri-level asynchronous framework, i.e., Efficient Transfer Learning Framework for Cross-Domain Click-Through Rate Prediction (E-CDCTR), to transfer comprehensive knowledge of natural content to advertisement CTR models. This framework consists of three key components: Tiny Pre-training Model ((TPM), which trains a tiny CTR model with several basic features on long-term natural data; Complete Pre-training Model (CPM), which trains a CTR model holding network structure and input features the same as target advertisement on short-term natural data; Advertisement CTR model (A-CTR), which derives its parameter initialization from CPM together with multiple historical embeddings from TPM as extra feature and then fine-tunes on advertisement data. TPM provides richer representations of user and item for both the CPM and A-CTR, effectively alleviating the forgetting problem inherent in the daily updates. CPM further enhances the advertisement model by providing knowledgeable initialization, thereby alleviating the data sparsity challenges typically encountered by advertising CTR models. Such a tri-level cross-domain transfer learning framework offers an efficient solution to address both data sparsity and `catastrophic forgetting', yielding remarkable improvements.
AutoHEnsGNN: Winning Solution to AutoGraph Challenge for KDD Cup 2020
Nov 25, 2021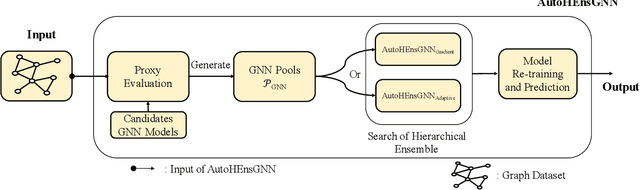
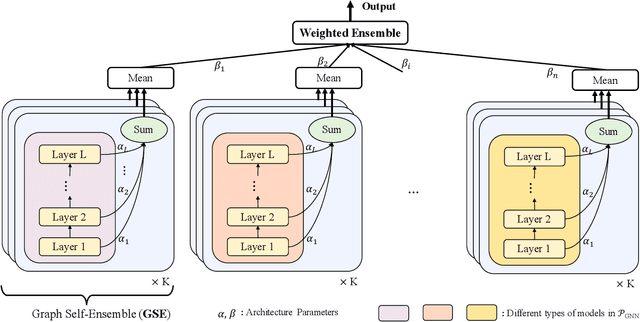
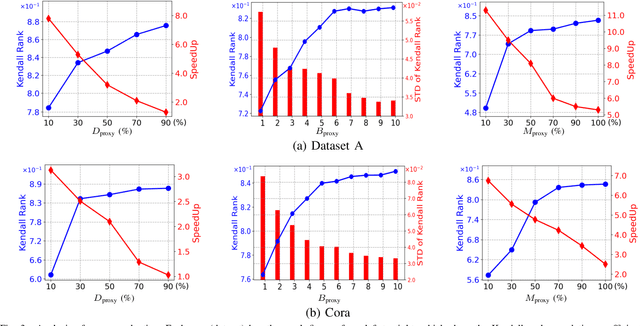
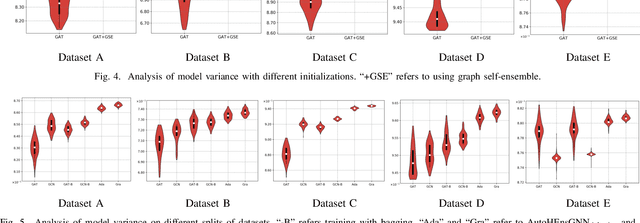
Graph Neural Networks (GNNs) have become increasingly popular and achieved impressive results in many graph-based applications. However, extensive manual work and domain knowledge are required to design effective architectures, and the results of GNN models have high variance with different training setups, which limits the application of existing GNN models. In this paper, we present AutoHEnsGNN, a framework to build effective and robust models for graph tasks without any human intervention. AutoHEnsGNN won first place in the AutoGraph Challenge for KDD Cup 2020, and achieved the best rank score of five real-life datasets in the final phase. Given a task, AutoHEnsGNN first applies a fast proxy evaluation to automatically select a pool of promising GNN models. Then it builds a hierarchical ensemble framework: 1) We propose graph self-ensemble (GSE), which can reduce the variance of weight initialization and efficiently exploit the information of local and global neighborhoods; 2) Based on GSE, a weighted ensemble of different types of GNN models is used to effectively learn more discriminative node representations. To efficiently search the architectures and ensemble weights, we propose AutoHEnsGNN$_{\text{Gradient}}$, which treats the architectures and ensemble weights as architecture parameters and uses gradient-based architecture search to obtain optimal configurations, and AutoHEnsGNN$_{\text{Adaptive}}$, which can adaptively adjust the ensemble weight based on the model accuracy. Extensive experiments on node classification, graph classification, edge prediction and KDD Cup challenge demonstrate the effectiveness and generality of AutoHEnsGNN