 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Transfer Learning Framework for Cross-Domain Click-Through Rate Prediction
Aug 29, 2024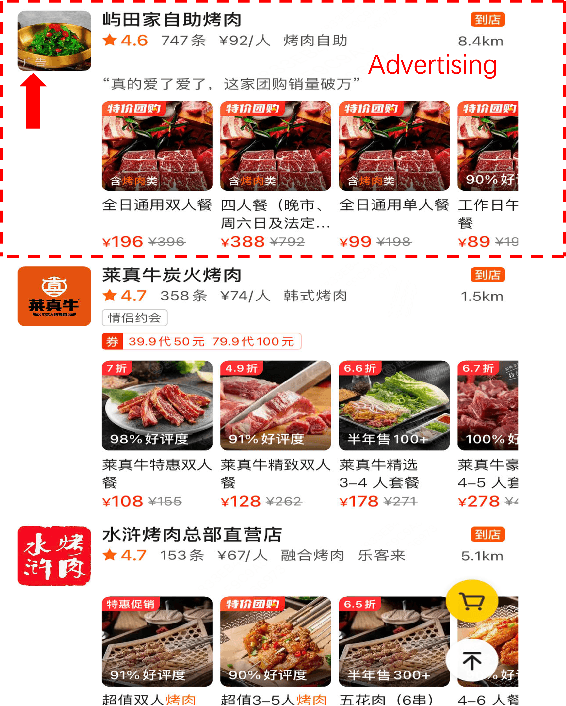
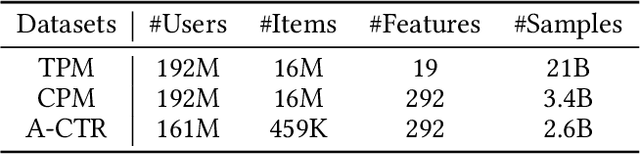
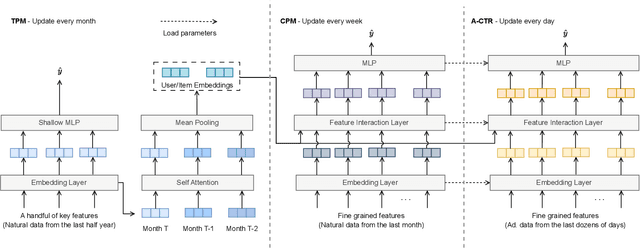
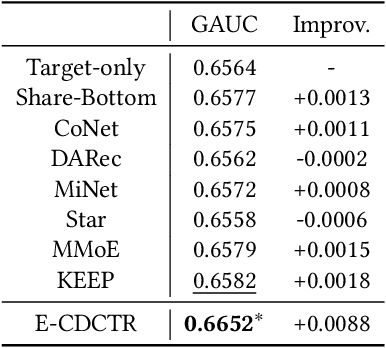
Natural content and advertisement coexist in industrial recommendation systems but differ in data distribution. Concretely, traffic related to the advertisement is considerably sparser compared to that of natural content, which motivates the development of transferring knowledge from the richer source natural content domain to the sparser advertising domain. The challenges include the inefficiencies arising from the management of extensive source data and the problem of 'catastrophic forgetting' that results from the CTR model's daily updating. To this end, we propose a novel tri-level asynchronous framework, i.e., Efficient Transfer Learning Framework for Cross-Domain Click-Through Rate Prediction (E-CDCTR), to transfer comprehensive knowledge of natural content to advertisement CTR models. This framework consists of three key components: Tiny Pre-training Model ((TPM), which trains a tiny CTR model with several basic features on long-term natural data; Complete Pre-training Model (CPM), which trains a CTR model holding network structure and input features the same as target advertisement on short-term natural data; Advertisement CTR model (A-CTR), which derives its parameter initialization from CPM together with multiple historical embeddings from TPM as extra feature and then fine-tunes on advertisement data. TPM provides richer representations of user and item for both the CPM and A-CTR, effectively alleviating the forgetting problem inherent in the daily updates. CPM further enhances the advertisement model by providing knowledgeable initialization, thereby alleviating the data sparsity challenges typically encountered by advertising CTR models. Such a tri-level cross-domain transfer learning framework offers an efficient solution to address both data sparsity and `catastrophic forgetting', yielding remarkable improvements.
MoPE: Mixture of Prefix Experts for Zero-Shot Dialogue State Tracking
Apr 12, 2024



Zero-shot dialogue state tracking (DST) transfers knowledge to unseen domains, reducing the cost of annotating new datasets. Previous zero-shot DST models mainly suffer from domain transferring and partial prediction problems. To address these challenges, we propose Mixture of Prefix Experts (MoPE) to establish connections between similar slots in different domains, which strengthens the model transfer performance in unseen domains. Empirical results demonstrate that MoPE-DST achieves the joint goal accuracy of 57.13% on MultiWOZ2.1 and 55.40% on SGD.
DiffusionDialog: A Diffusion Model for Diverse Dialog Generation with Latent Space
Apr 10, 2024



In real-life conversations, the content is diverse, and there exists the one-to-many problem that requires diverse generation. Previous studies attempted to introduce discrete or Gaussian-based continuous latent variables to address the one-to-many problem, but the diversity is limited. Recently, diffusion models have made breakthroughs in computer vision, and some attempts have been made in natural language processing. In this paper, we propose DiffusionDialog, a novel approach to enhance the diversity of dialogue generation with the help of diffusion model. In our approach, we introduce continuous latent variables into the diffusion model. The problem of using latent variables in the dialog task is how to build both an effective prior of the latent space and an inferring process to obtain the proper latent given the context. By combining the encoder and latent-based diffusion model, we encode the response's latent representation in a continuous space as the prior, instead of fixed Gaussian distribution or simply discrete ones. We then infer the latent by denoising step by step with the diffusion model. The experimental results show that our model greatly enhances the diversity of dialog responses while maintaining coherence. Furthermore, in further analysis, we find that our diffusion model achieves high inference efficiency, which is the main challenge of applying diffusion models in natural language processing.
AT4CTR: Auxiliary Match Tasks for Enhancing Click-Through Rate Prediction
Dec 18, 2023



Click-through rate (CTR) prediction is a vital task in industrial recommendation systems. Most existing methods focus on the network architecture design of the CTR model for better accuracy and suffer from the data sparsity problem. Especially in industrial recommendation systems, the widely applied negative sample down-sampling technique due to resource limitation worsens the problem, resulting in a decline in performance. In this paper, we propose \textbf{A}uxiliary Match \textbf{T}asks for enhancing \textbf{C}lick-\textbf{T}hrough \textbf{R}ate prediction accuracy (AT4CTR) by alleviating the data sparsity problem. Specifically, we design two match tasks inspired by collaborative filtering to enhance the relevance modeling between user and item. As the "click" action is a strong signal which indicates the user's preference towards the item directly, we make the first match task aim at pulling closer the representation between the user and the item regarding the positive samples. Since the user's past click behaviors can also be treated as the user him/herself, we apply the next item prediction as the second match task. For both the match tasks, we choose the InfoNCE as their loss function. The two match tasks can provide meaningful training signals to speed up the model's convergence and alleviate the data sparsity. We conduct extensive experiments on one public dataset and one large-scale industrial recommendation dataset. The result demonstrates the effectiveness of the proposed auxiliary match tasks. AT4CTR has been deployed in the real industrial advertising system and has gained remarkable revenue.
Deep Group Interest Modeling of Full Lifelong User Behaviors for CTR Prediction
Nov 15, 2023



Extracting users' interests from their lifelong behavior sequence is crucial for predicting Click-Through Rate (CTR). Most current methods employ a two-stage process for efficiency: they first select historical behaviors related to the candidate item and then deduce the user's interest from this narrowed-down behavior sub-sequence. This two-stage paradigm, though effective, leads to information loss. Solely using users' lifelong click behaviors doesn't provide a complete picture of their interests, leading to suboptimal performance. In our research, we introduce the Deep Group Interest Network (DGIN), an end-to-end method to model the user's entire behavior history. This includes all post-registration actions, such as clicks, cart additions, purchases, and more, providing a nuanced user understanding. We start by grouping the full range of behaviors using a relevant key (like item_id) to enhance efficiency. This process reduces the behavior length significantly, from O(10^4) to O(10^2). To mitigate the potential loss of information due to grouping, we incorporate two categories of group attributes. Within each group, we calculate statistical information on various heterogeneous behaviors (like behavior counts) and employ self-attention mechanisms to highlight unique behavior characteristics (like behavior type). Based on this reorganized behavior data, the user's interests are derived using the Transformer technique. Additionally, we identify a subset of behaviors that share the same item_id with the candidate item from the lifelong behavior sequence. The insights from this subset reveal the user's decision-making process related to the candidate item, improving prediction accuracy. Our comprehensive evaluation, both on industrial and public datasets, validates DGIN's efficacy and efficiency.
Robust Safe Reinforcement Learning under Adversarial Disturbances
Oct 11, 2023



Safety is a primary concern when applying reinforcement learning to real-world control tasks, especially in the presence of external disturbances. However, existing safe reinforcement learning algorithms rarely account for external disturbances, limiting their applicability and robustness in practice. To address this challenge, this paper proposes a robust safe reinforcement learning framework that tackles worst-case disturbances. First, this paper presents a policy iteration scheme to solve for the robust invariant set, i.e., a subset of the safe set, where persistent safety is only possible for states within. The key idea is to establish a two-player zero-sum game by leveraging the safety value function in Hamilton-Jacobi reachability analysis, in which the protagonist (i.e., control inputs) aims to maintain safety and the adversary (i.e., external disturbances) tries to break down safety. This paper proves that the proposed policy iteration algorithm converges monotonically to the maximal robust invariant set. Second, this paper integrates the proposed policy iteration scheme into a constrained reinforcement learning algorithm that simultaneously synthesizes the robust invariant set and uses it for constrained policy optimization. This algorithm tackles both optimality and safety, i.e., learning a policy that attains high rewards while maintaining safety under worst-case disturbances. Experiments on classic control tasks show that the proposed method achieves zero constraint violation with learned worst-case adversarial disturbances, while other baseline algorithms violate the safety constraints substantially. Our proposed method also attains comparable performance as the baselines even in the absence of the adversary.
STGIN: Spatial-Temporal Graph Interaction Network for Large-scale POI Recommendation
Sep 05, 2023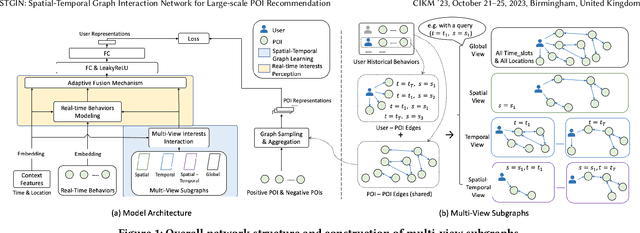
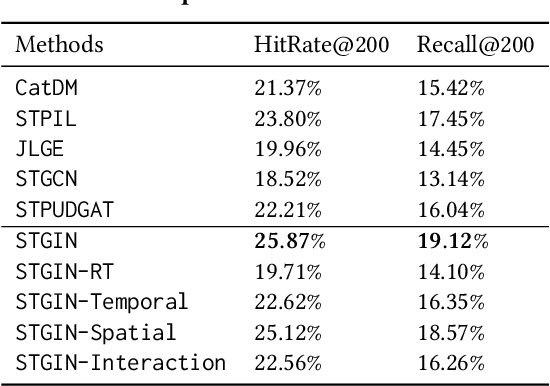

In Location-Based Services, Point-Of-Interest(POI) recommendation plays a crucial role in both user experience and business opportunities. Graph neural networks have been proven effective in providing personalized POI recommendation services. However, there are still two critical challenges. First, existing graph models attempt to capture users' diversified interests through a unified graph, which limits their ability to express interests in various spatial-temporal contexts. Second, the efficiency limitations of graph construction and graph sampling in large-scale systems make it difficult to adapt quickly to new real-time interests. To tackle the above challenges, we propose a novel Spatial-Temporal Graph Interaction Network. Specifically, we construct subgraphs of spatial, temporal, spatial-temporal, and global views respectively to precisely characterize the user's interests in various contexts. In addition, we design an industry-friendly framework to track the user's latest interests. Extensive experiments on the real-world dataset show that our method outperforms state-of-the-art models. This work has been successfully deployed in a large e-commerce platform, delivering a 1.1% CTR and 6.3% RPM improvement.
Deep Context Interest Network for Click-Through Rate Prediction
Aug 11, 2023



Click-Through Rate (CTR) prediction, estimating the probability of a user clicking on an item, is essential in industrial applications, such as online advertising. Many works focus on user behavior modeling to improve CTR prediction performance. However, most of those methods only model users' positive interests from users' click items while ignoring the context information, which is the display items around the clicks, resulting in inferior performance. In this paper, we highlight the importance of context information on user behavior modeling and propose a novel model named Deep Context Interest Network (DCIN), which integrally models the click and its display context to learn users' context-aware interests. DCIN consists of three key modules: 1) Position-aware Context Aggregation Module (PCAM), which performs aggregation of display items with an attention mechanism; 2) Feedback-Context Fusion Module (FCFM), which fuses the representation of clicks and display contexts through non-linear feature interaction; 3) Interest Matching Module (IMM), which activates interests related with the target item. Moreover, we provide our hands-on solution to implement our DCIN model on large-scale industrial systems. The significant improvements in both offline and online evaluations demonstrate the superiority of our proposed DCIN method. Notably, DCIN has been deployed on our online advertising system serving the main traffic, which brings 1.5% CTR and 1.5% RPM lift.
DisenPOI: Disentangling Sequential and Geographical Influence for Point-of-Interest Recommendation
Oct 29, 2022



Point-of-Interest (POI) recommendation plays a vital role in various location-aware services. It has been observed that POI recommendation is driven by both sequential and geographical influences. However, since there is no annotated label of the dominant influence during recommendation, existing methods tend to entangle these two influences, which may lead to sub-optimal recommendation performance and poor interpretability. In this paper, we address the above challenge by proposing DisenPOI, a novel Disentangled dual-graph framework for POI recommendation, which jointly utilizes sequential and geographical relationships on two separate graphs and disentangles the two influences with self-supervision. The key novelty of our model compared with existing approaches is to extract disentangled representations of both sequential and geographical influences with contrastive learning. To be specific, we construct a geographical graph and a sequential graph based on the check-in sequence of a user. We tailor their propagation schemes to become sequence-/geo-aware to better capture the corresponding influences. Preference proxies are extracted from check-in sequence as pseudo labels for the two influences, which supervise the disentanglement via a contrastive loss. Extensive experiments on three datasets demonstrate the superiority of the proposed model.
Hybrid CNN Based Attention with Category Prior for User Image Behavior Modeling
May 05, 2022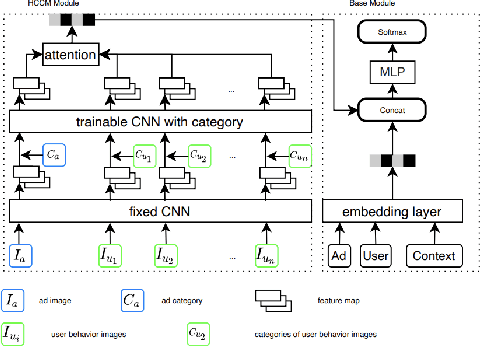
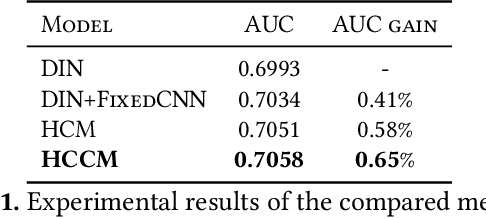
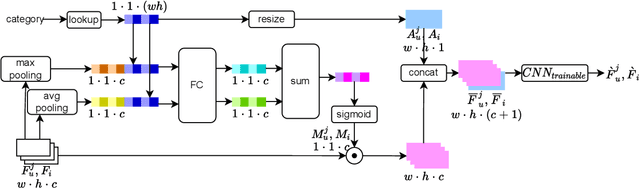
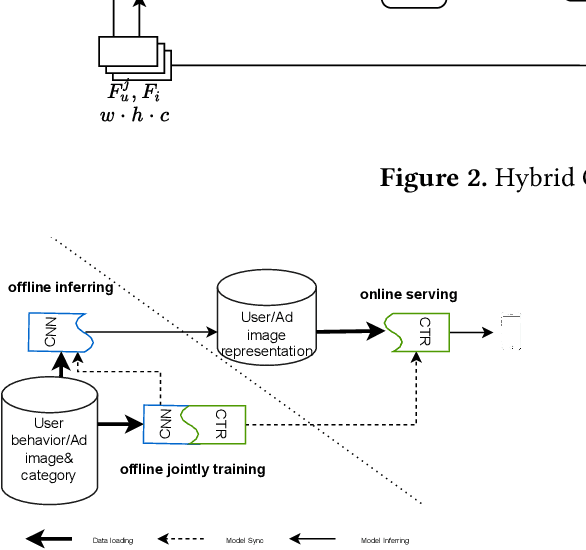
User historical behaviors are proved useful for Click Through Rate (CTR) prediction in online advertising system. In Meituan, one of the largest e-commerce platform in China, an item is typically displayed with its image and whether a user clicks the item or not is usually influenced by its image, which implies that user's image behaviors are helpful for understanding user's visual preference and improving the accuracy of CTR prediction. Existing user image behavior models typically use a two-stage architecture, which extracts visual embeddings of images through off-the-shelf Convolutional Neural Networks (CNNs) in the first stage, and then jointly trains a CTR model with those visual embeddings and non-visual features. We find that the two-stage architecture is sub-optimal for CTR prediction. Meanwhile, precisely labeled categories in online ad systems contain abundant visual prior information, which can enhance the modeling of user image behaviors. However, off-the-shelf CNNs without category prior may extract category unrelated features, limiting CNN's expression ability. To address the two issues, we propose a hybrid CNN based attention module, unifying user's image behaviors and category prior, for CTR prediction. Our approach achieves significant improvements in both online and offline experiments on a billion scale real serving dataset.