 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentVista: Evaluating Multimodal Agents in Ultra-Challenging Realistic Visual Scenarios
Feb 26, 2026Real-world multimodal agents solve multi-step workflows grounded in visual evidence. For example, an agent can troubleshoot a device by linking a wiring photo to a schematic and validating the fix with online documentation, or plan a trip by interpreting a transit map and checking schedules under routing constraints. However, existing multimodal benchmarks mainly evaluate single-turn visual reasoning or specific tool skills, and they do not fully capture the realism, visual subtlety, and long-horizon tool use that practical agents require. We introduce AgentVista, a benchmark for generalist multimodal agents that spans 25 sub-domains across 7 categories, pairing realistic and detail-rich visual scenarios with natural hybrid tool use. Tasks require long-horizon tool interactions across modalities, including web search, image search, page navigation, and code-based operations for both image processing and general programming. Comprehensive evaluation of state-of-the-art models exposes significant gaps in their ability to carry out long-horizon multimodal tool use. Even the best model in our evaluation, Gemini-3-Pro with tools, achieves only 27.3% overall accuracy, and hard instances can require more than 25 tool-calling turns. We expect AgentVista to accelerate the development of more capable and reliable multimodal agents for realistic and ultra-challenging problem solving.
Athena: Enhancing Multimodal Reasoning with Data-efficient Process Reward Models
Jun 11, 2025We present Athena-PRM, a multimodal process reward model (PRM) designed to evaluate the reward score for each step in solving complex reasoning problems. Developing high-performance PRMs typically demands significant time and financial investment, primarily due to the necessity for step-level annotations of reasoning steps. Conventional automated labeling methods, such as Monte Carlo estimation, often produce noisy labels and incur substantial computational costs. To efficiently generate high-quality process-labeled data, we propose leveraging prediction consistency between weak and strong completers as a criterion for identifying reliable process labels. Remarkably, Athena-PRM demonstrates outstanding effectiveness across various scenarios and benchmarks with just 5,000 samples. Furthermore, we also develop two effective strategies to improve the performance of PRMs: ORM initialization and up-sampling for negative data. We validate our approach in three specific scenarios: verification for test time scaling, direct evaluation of reasoning step correctness, and reward ranked fine-tuning. Our Athena-PRM consistently achieves superior performance across multiple benchmarks and scenarios. Notably, when using Qwen2.5-VL-7B as the policy model, Athena-PRM enhances performance by 10.2 points on WeMath and 7.1 points on MathVista for test time scaling. Furthermore, Athena-PRM sets the state-of-the-art (SoTA) results in VisualProcessBench and outperforms the previous SoTA by 3.9 F1-score, showcasing its robust capability to accurately assess the correctness of the reasoning step. Additionally, utilizing Athena-PRM as the reward model, we develop Athena-7B with reward ranked fine-tuning and outperforms baseline with a significant margin on five benchmarks.
UAQFact: Evaluating Factual Knowledge Utilization of LLMs on Unanswerable Questions
May 29, 2025


Handling unanswerable questions (UAQ) is crucial for LLMs, as it helps prevent misleading responses in complex situations. While previous studies have built several datasets to assess LLMs' performance on UAQ, these datasets lack factual knowledge support, which limits the evaluation of LLMs' ability to utilize their factual knowledge when handling UAQ. To address the limitation, we introduce a new unanswerable question dataset UAQFact, a bilingual dataset with auxiliary factual knowledge created from a Knowledge Graph. Based on UAQFact, we further define two new tasks to measure LLMs' ability to utilize internal and external factual knowledge, respectively. Our experimental results across multiple LLM series show that UAQFact presents significant challenges, as LLMs do not consistently perform well even when they have factual knowledge stored. Additionally, we find that incorporating external knowledge may enhance performance, but LLMs still cannot make full use of the knowledge which may result in incorrect responses.
Iterative Value Function Optimization for Guided Decoding
Mar 05, 2025While Reinforcement Learning from Human Feedback (RLHF) has become the predominant method for controlling language model outputs, it suffers from high computational costs and training instability. Guided decoding, especially value-guided methods, offers a cost-effective alternative by controlling outputs without re-training models. However, the accuracy of the value function is crucial for value-guided decoding, as inaccuracies can lead to suboptimal decision-making and degraded performance. Existing methods struggle with accurately estimating the optimal value function, leading to less effective control. We propose Iterative Value Function Optimization, a novel framework that addresses these limitations through two key components: Monte Carlo Value Estimation, which reduces estimation variance by exploring diverse trajectories, and Iterative On-Policy Optimization, which progressively improves value estimation through collecting trajectories from value-guided policies. Extensive experiments on text summarization, multi-turn dialogue, and instruction following demonstrate the effectiveness of value-guided decoding approaches in aligning language models. These approaches not only achieve alignment but also significantly reduce computational costs by leveraging principled value function optimization for efficient and effective control.
Jakiro: Boosting Speculative Decoding with Decoupled Multi-Head via MoE
Feb 10, 2025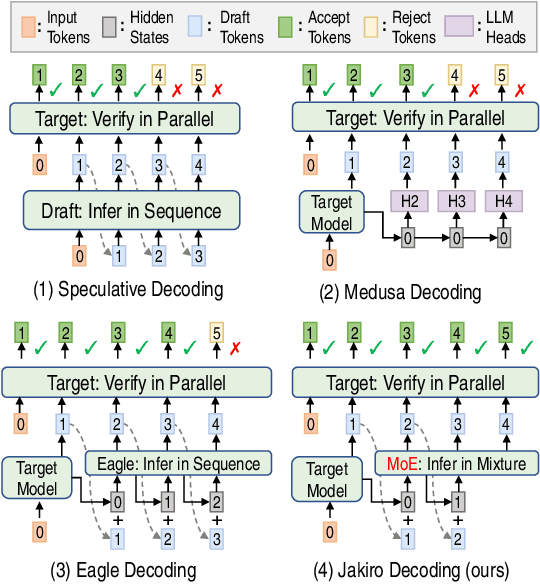
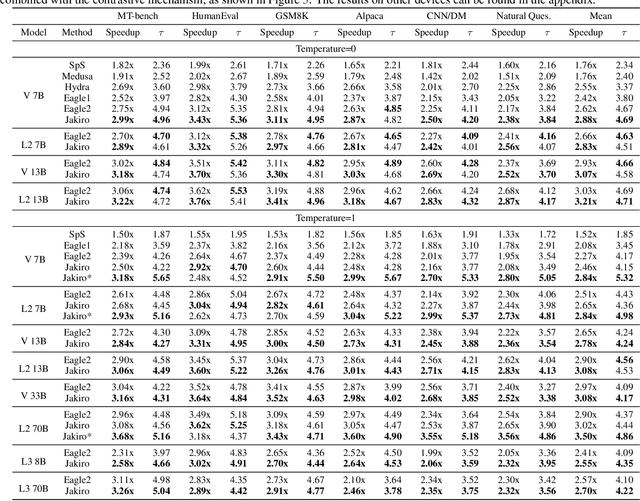
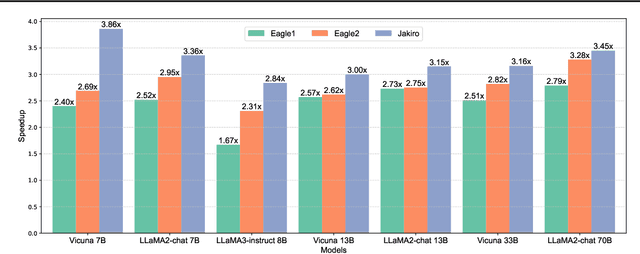
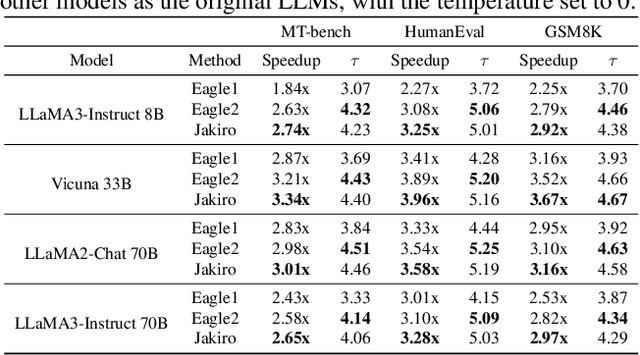
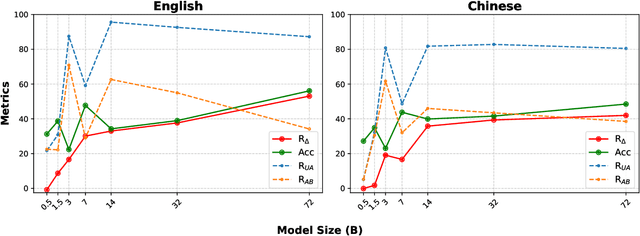
Speculative decoding (SD) accelerates large language model inference by using a smaller draft model to predict multiple tokens, which are then verified in parallel by the larger target model. However, the limited capacity of the draft model often necessitates tree-based sampling to improve prediction accuracy, where multiple candidates are generated at each step. We identify a key limitation in this approach: the candidates at the same step are derived from the same representation, limiting diversity and reducing overall effectiveness. To address this, we propose Jakiro, leveraging Mixture of Experts (MoE), where independent experts generate diverse predictions, effectively decoupling correlations among candidates. Furthermore, we introduce a hybrid inference strategy, combining autoregressive decoding for initial tokens with parallel decoding for subsequent stages, and enhance the latter with contrastive mechanism in features to improve accuracy. Our method significantly boosts prediction accuracy and achieves higher inference speedups. Extensive experiments across diverse models validate the effectiveness and robustness of our approach, establishing a new SOTA in speculative decoding. Our codes are available at https://github.com/haiduo/Jakiro.
Nearly Lossless Adaptive Bit Switching
Feb 03, 2025



Model quantization is widely applied for compressing and accelerating deep neural networks (DNNs). However, conventional Quantization-Aware Training (QAT) focuses on training DNNs with uniform bit-width. The bit-width settings vary across different hardware and transmission demands, which induces considerable training and storage costs. Hence, the scheme of one-shot joint training multiple precisions is proposed to address this issue. Previous works either store a larger FP32 model to switch between different precision models for higher accuracy or store a smaller INT8 model but compromise accuracy due to using shared quantization parameters. In this paper, we introduce the Double Rounding quantization method, which fully utilizes the quantized representation range to accomplish nearly lossless bit-switching while reducing storage by using the highest integer precision instead of full precision. Furthermore, we observe a competitive interference among different precisions during one-shot joint training, primarily due to inconsistent gradients of quantization scales during backward propagation. To tackle this problem, we propose an Adaptive Learning Rate Scaling (ALRS) technique that dynamically adapts learning rates for various precisions to optimize the training process. Additionally, we extend our Double Rounding to one-shot mixed precision training and develop a Hessian-Aware Stochastic Bit-switching (HASB) strategy. Experimental results on the ImageNet-1K classification demonstrate that our methods have enough advantages to state-of-the-art one-shot joint QAT in both multi-precision and mixed-precision. We also validate the feasibility of our method on detection and segmentation tasks, as well as on LLMs task. Our codes are available at https://github.com/haiduo/Double-Rounding.
Grasp What You Want: Embodied Dexterous Grasping System Driven by Your Voice
Dec 14, 2024In recent years, as robotics has advanced, human-robot collaboration has gained increasing importance. However, current robots struggle to fully and accurately interpret human intentions from voice commands alone. Traditional gripper and suction systems often fail to interact naturally with humans, lack advanced manipulation capabilities, and are not adaptable to diverse tasks, especially in unstructured environments. This paper introduces the Embodied Dexterous Grasping System (EDGS), designed to tackle object grasping in cluttered environments for human-robot interaction. We propose a novel approach to semantic-object alignment using a Vision-Language Model (VLM) that fuses voice commands and visual information, significantly enhancing the alignment of multi-dimensional attributes of target objects in complex scenarios. Inspired by human hand-object interactions, we develop a robust, precise, and efficient grasping strategy, incorporating principles like the thumb-object axis, multi-finger wrapping, and fingertip interaction with an object's contact mechanics. We also design experiments to assess Referring Expression Representation Enrichment (RERE) in referring expression segmentation, demonstrating that our system accurately detects and matches referring expressions. Extensive experiments confirm that EDGS can effectively handle complex grasping tasks, achieving stability and high success rates, highlighting its potential for further development in the field of Embodied AI.
Learning to Refuse: Towards Mitigating Privacy Risks in LLMs
Jul 14, 2024Large language models (LLMs) exhibit remarkable capabilities in understanding and generating natural language. However, these models can inadvertently memorize private information, posing significant privacy risks. This study addresses the challenge of enabling LLMs to protect specific individuals' private data without the need for complete retraining. We propose \return, a Real-world pErsonal daTa UnleaRNing dataset, comprising 2,492 individuals from Wikipedia with associated QA pairs, to evaluate machine unlearning (MU) methods for protecting personal data in a realistic scenario. Additionally, we introduce the Name-Aware Unlearning Framework (NAUF) for Privacy Protection, which enables the model to learn which individuals' information should be protected without affecting its ability to answer questions related to other unrelated individuals. Our extensive experiments demonstrate that NAUF achieves a state-of-the-art average unlearning score, surpassing the best baseline method by 5.65 points, effectively protecting target individuals' personal data while maintaining the model's general capabilities.
Probing Language Models for Pre-training Data Detection
Jun 03, 2024Large Language Models (LLMs) have shown their impressive capabilities, while also raising concerns about the data contamination problems due to privacy issues and leakage of benchmark datasets in the pre-training phase. Therefore, it is vital to detect the contamination by checking whether an LLM has been pre-trained on the target texts. Recent studies focus on the generated texts and compute perplexities, which are superficial features and not reliable. In this study, we propose to utilize the probing technique for pre-training data detection by examining the model's internal activations. Our method is simple and effective and leads to more trustworthy pre-training data detection. Additionally, we propose ArxivMIA, a new challenging benchmark comprising arxiv abstracts from Computer Science and Mathematics categories. Our experiments demonstrate that our method outperforms all baselines, and achieves state-of-the-art performance on both WikiMIA and ArxivMIA, with additional experiments confirming its efficacy (Our code and dataset are available at https://github.com/zhliu0106/probing-lm-data).
Kangaroo: Lossless Self-Speculative Decoding via Double Early Exiting
Apr 29, 2024Speculative decoding has demonstrated its effectiveness in accelerating the inference of large language models while maintaining a consistent sampling distribution. However, the conventional approach of training a separate draft model to achieve a satisfactory token acceptance rate can be costly. Drawing inspiration from early exiting, we propose a novel self-speculative decoding framework \emph{Kangaroo}, which uses a fixed shallow sub-network as a self-draft model, with the remaining layers serving as the larger target model. We train a lightweight and efficient adapter module on top of the sub-network to bridge the gap between the sub-network and the full model's representation ability. It is noteworthy that the inference latency of the self-draft model may no longer be negligible compared to the large model, necessitating strategies to increase the token acceptance rate while minimizing the drafting steps of the small model. To address this challenge, we introduce an additional early exiting mechanism for generating draft tokens. Specifically, we halt the small model's subsequent prediction during the drafting phase once the confidence level for the current token falls below a certain threshold. Extensive experiments on the Spec-Bench demonstrate the effectiveness of Kangaroo. Under single-sequence verification, Kangaroo achieves speedups up to $1.68\times$ on Spec-Bench, outperforming Medusa-1 with 88.7\% fewer additional parameters (67M compared to 591M). The code for Kangaroo is available at https://github.com/Equationliu/Kangaroo.