 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasp What You Want: Embodied Dexterous Grasping System Driven by Your Voice
Dec 14, 2024In recent years, as robotics has advanced, human-robot collaboration has gained increasing importance. However, current robots struggle to fully and accurately interpret human intentions from voice commands alone. Traditional gripper and suction systems often fail to interact naturally with humans, lack advanced manipulation capabilities, and are not adaptable to diverse tasks, especially in unstructured environments. This paper introduces the Embodied Dexterous Grasping System (EDGS), designed to tackle object grasping in cluttered environments for human-robot interaction. We propose a novel approach to semantic-object alignment using a Vision-Language Model (VLM) that fuses voice commands and visual information, significantly enhancing the alignment of multi-dimensional attributes of target objects in complex scenarios. Inspired by human hand-object interactions, we develop a robust, precise, and efficient grasping strategy, incorporating principles like the thumb-object axis, multi-finger wrapping, and fingertip interaction with an object's contact mechanics. We also design experiments to assess Referring Expression Representation Enrichment (RERE) in referring expression segmentation, demonstrating that our system accurately detects and matches referring expressions. Extensive experiments confirm that EDGS can effectively handle complex grasping tasks, achieving stability and high success rates, highlighting its potential for further development in the field of Embodied AI.
A Reinforcement Learning-Based Automatic Video Editing Method Using Pre-trained Vision-Language Model
Nov 07, 2024



In this era of videos, automatic video editing techniques attract more and more attention from industry and academia since they can reduce workloads and lower the requirements for human editors. Existing automatic editing systems are mainly scene- or event-specific, e.g., soccer game broadcasting, yet the automatic systems for general editing, e.g., movie or vlog editing which covers various scenes and events, were rarely studied before, and converting the event-driven editing method to a general scene is nontrivial. In this paper, we propose a two-stage scheme for general editing. Firstly, unlike previous works that extract scene-specific features, we leverage the pre-trained Vision-Language Model (VLM) to extract the editing-relevant representations as editing context. Moreover, to close the gap between the professional-looking videos and the automatic productions generated with simple guidelines, we propose a Reinforcement Learning (RL)-based editing framework to formulate the editing problem and train the virtual editor to make better sequential editing decisions. Finally, we evaluate the proposed method on a more general editing task with a real movie dataset. Experimental results demonstrate the effectiveness and benefits of the proposed context representation and the learning ability of our RL-based editing framework.
ClickAttention: Click Region Similarity Guided Interactive Segmentation
Aug 13, 2024



Interactive segmentation algorithms based on click points have garnered significant attention from researchers in recent years. However, existing studies typically use sparse click maps as model inputs to segment specific target objects, which primarily affect local regions and have limited abilities to focus on the whole target object, leading to increased times of clicks. In addition, most existing algorithms can not balance well between high performance and efficiency. To address this issue, we propose a click attention algorithm that expands the influence range of positive clicks based on the similarity between positively-clicked regions and the whole input. We also propose a discriminative affinity loss to reduce the attention coupling between positive and negative click regions to avoid an accuracy decrease caused by mutual interference between positive and negative clicks. Extensive experiments demonstrate that our approach is superior to existing methods and achieves cutting-edge performance in fewer parameters. An interactive demo and all reproducible codes will be released at https://github.com/hahamyt/ClickAttention.
Divide and Conquer: Improving Multi-Camera 3D Perception with 2D Semantic-Depth Priors and Input-Dependent Queries
Aug 13, 20243D perception tasks, such as 3D object detection and Bird's-Eye-View (BEV) segmentation using multi-camera images, have drawn significant attention recently. Despite the fact that accurately estimating both semantic and 3D scene layouts are crucial for this task, existing techniques often neglect the synergistic effects of semantic and depth cues, leading to the occurrence of classification and position estimation errors. Additionally, the input-independent nature of initial queries also limits the learning capacity of Transformer-based models. To tackle these challenges, we propose an input-aware Transformer framework that leverages Semantics and Depth as priors (named SDTR). Our approach involves the use of an S-D Encoder that explicitly models semantic and depth priors, thereby disentangling the learning process of object categorization and position estimation. Moreover, we introduce a Prior-guided Query Builder that incorporates the semantic prior into the initial queries of the Transformer, resulting in more effective input-aware queries. Extensive experiments on the nuScenes and Lyft benchmarks demonstrate the state-of-the-art performance of our method in both 3D object detection and BEV segmentation tasks.
Towards Cross-View-Consistent Self-Supervised Surround Depth Estimation
Jul 04, 2024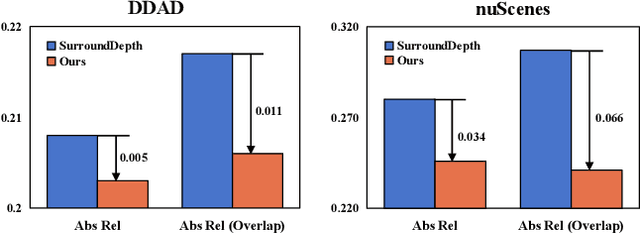
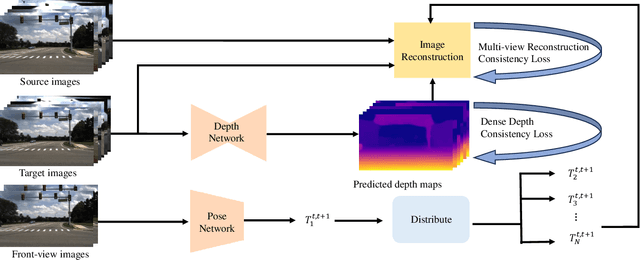
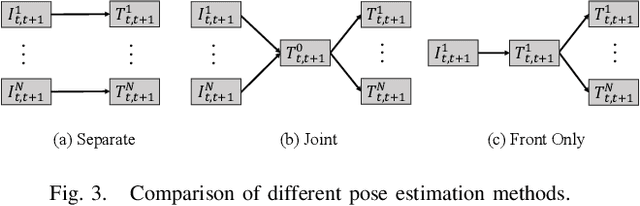

Depth estimation is a cornerstone for autonomous driving, yet acquiring per-pixel depth ground truth for supervised learning is challenging. Self-Supervised Surround Depth Estimation (SSSDE) from consecutive images offers an economical alternative. While previous SSSDE methods have proposed different mechanisms to fuse information across images, few of them explicitly consider the cross-view constraints, leading to inferior performance, particularly in overlapping regions. This paper proposes an efficient and consistent pose estimation design and two loss functions to enhance cross-view consistency for SSSDE. For pose estimation, we propose to use only front-view images to reduce training memory and sustain pose estimation consistency. The first loss function is the dense depth consistency loss, which penalizes the difference between predicted depths in overlapping regions. The second one is the multi-view reconstruction consistency loss, which aims to maintain consistency between reconstruction from spatial and spatial-temporal contexts. Additionally, we introduce a novel flipping augmentation to improve the performance further. Our techniques enable a simple neural model to achieve state-of-the-art performance on the DDAD and nuScenes datasets. Last but not least, our proposed techniques can be easily applied to other methods. The code will be made public.
Structured Click Control in Transformer-based Interactive Segmentation
May 07, 2024
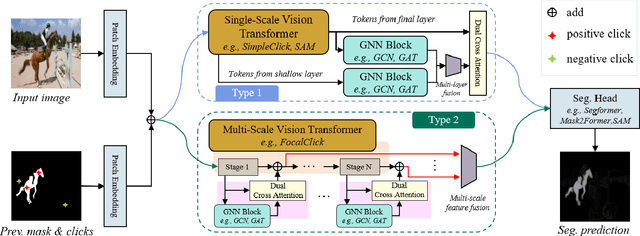
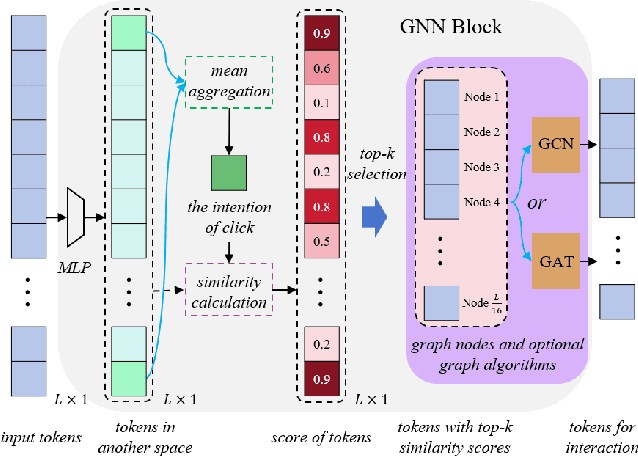
Click-point-based interactive segmentation has received widespread attention due to its efficiency. However, it's hard for existing algorithms to obtain precise and robust responses after multiple clicks. In this case, the segmentation results tend to have little change or are even worse than before. To improve the robustness of the response, we propose a structured click intent model based on graph neural networks, which adaptively obtains graph nodes via the global similarity of user-clicked Transformer tokens. Then the graph nodes will be aggregated to obtain structured interaction features. Finally, the dual cross-attention will be used to inject structured interaction features into vision Transformer features, thereby enhancing the control of clicks over segmentation results. Extensive experiments demonstrated the proposed algorithm can serve as a general structure in improving Transformer-based interactive segmenta?tion performance. The code and data will be released at https://github.com/hahamyt/scc.
HybriMap: Hybrid Clues Utilization for Effective Vectorized HD Map Construction
Apr 17, 2024



Constructing vectorized high-definition maps from surround-view cameras has garnered significant attention in recent years. However, the commonly employed multi-stage sequential workflow in prevailing approaches often leads to the loss of early-stage information, particularly in perspective-view features. Usually, such loss is observed as an instance missing or shape mismatching in the final birds-eye-view predictions. To address this concern, we propose a novel approach, namely \textbf{HybriMap}, which effectively exploits clues from hybrid features to ensure the delivery of valuable information. Specifically, we design the Dual Enhancement Module, to enable both explicit integration and implicit modification under the guidance of hybrid features. Additionally, the perspective keypoints are utilized as supervision, further directing the feature enhancement process. Extensive experiments conducted on existing benchmarks have demonstrated the state-of-the-art performance of our proposed approach.
MST: Adaptive Multi-Scale Tokens Guided Interactive Segmentation
Jan 09, 2024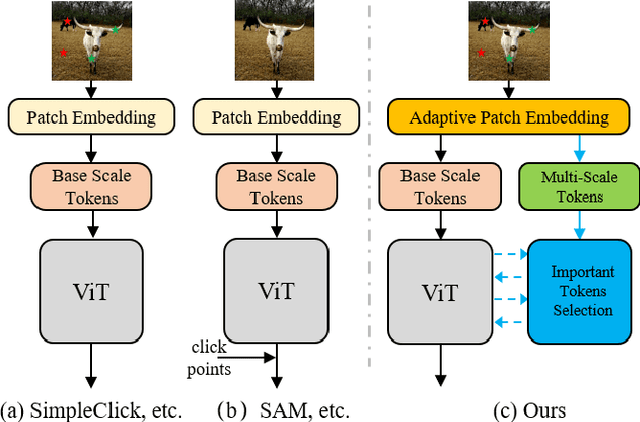

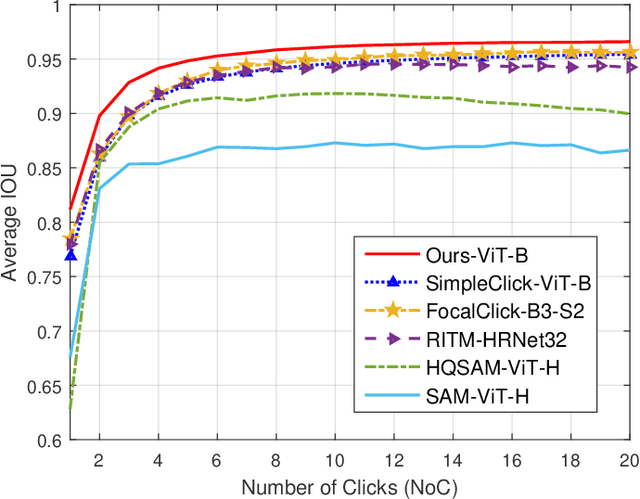
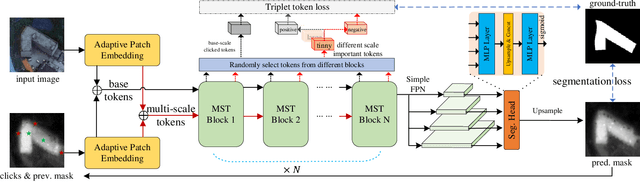
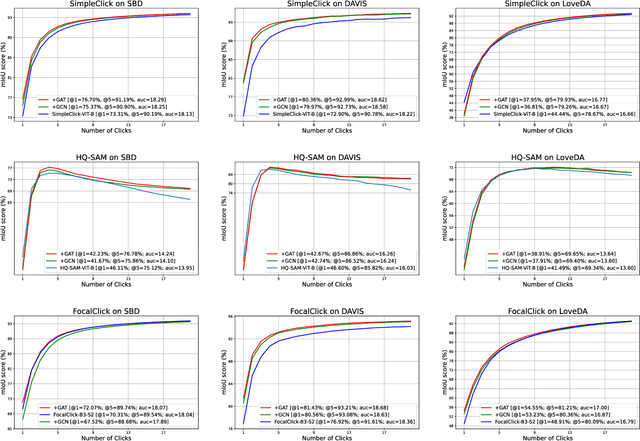
In the field of Industrial Informatics, interactive segmentation has gained significant attention for its application in human-computer interaction and data annotation. Existing algorithms, however, face challenges in balancing the segmentation accuracy between large and small targets, often leading to an increased number of user interactions. To tackle this, a novel multi-scale token adaptation algorithm, leveraging token similarity, has been devised to enhance segmentation across varying target sizes. This algorithm utilizes a differentiable top-k tokens selection mechanism, allowing for fewer tokens to be used while maintaining efficient multi-scale token interaction. Furthermore, a contrastive loss is introduced to better discriminate between target and background tokens, improving the correctness and robustness of the tokens similar to the target. Extensive benchmarking shows that the algorithm achieves state-of-the-art (SOTA) performance compared to current methods. An interactive demo and all reproducible codes will be released at https://github.com/hahamyt/mst.
Design and Control of a Highly Redundant Rigid-Flexible Coupling Robot to Assist the COVID-19 Oropharyngeal-Swab Sampling
Feb 25, 2021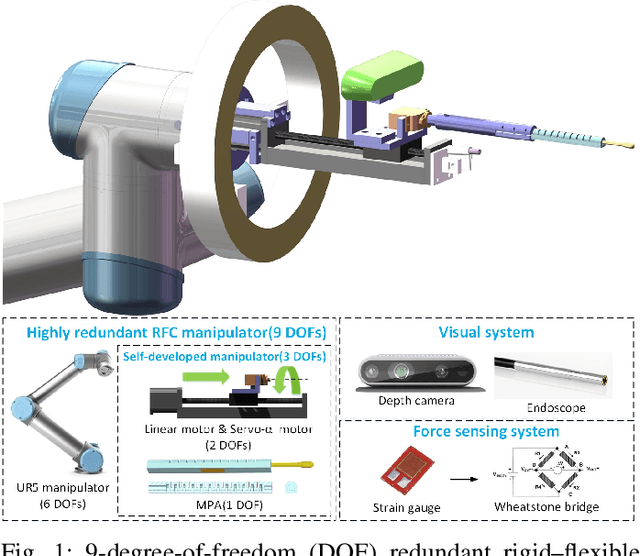
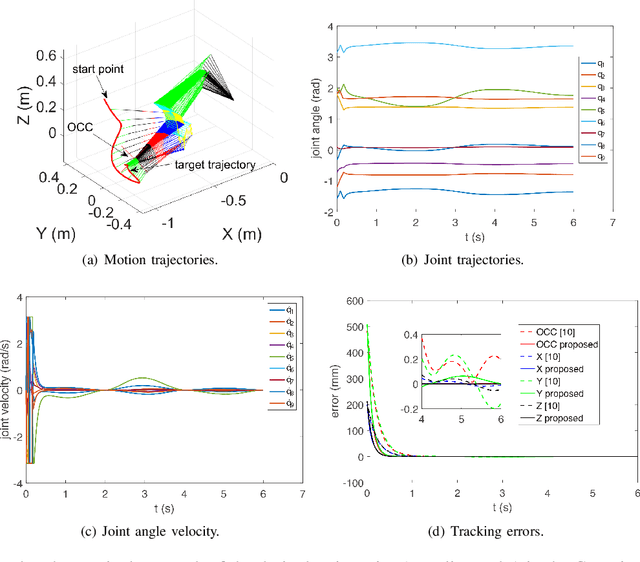
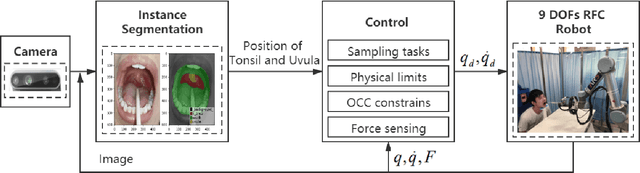
The outbreak of novel coronavirus pneumonia (COVID-19) has caused mortality and morbidity worldwide. Oropharyngeal-swab (OP-swab) sampling is widely used for the diagnosis of COVID-19 in the world. To avoid the clinical staff from being affected by the virus, we developed a 9-degree-of-freedom (DOF) rigid-flexible coupling (RFC) robot to assist the COVID-19 OP-swab sampling. This robot is composed of a visual system, UR5 robot arm, micro-pneumatic actuator and force-sensing system. The robot is expected to reduce risk and free up the clinical staff from the long-term repetitive sampling work. Compared with a rigid sampling robot, the developed force-sensing RFC robot can facilitate OP-swab sampling procedures in a safer and softer way. In addition, a varying-parameter zeroing neural network-based optimization method is also proposed for motion planning of the 9-DOF redundant manipulator. The developed robot system is validated by OP-swab sampling on both oral cavity phantoms and volunteers.