 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Enhancement for Depth from a Lightweight ToF Sensor with Monocular Images
Jun 16, 2025



Depth map enhancement using paired high-resolution RGB images offers a cost-effective solution for improving low-resolution depth data from lightweight ToF sensors. Nevertheless, naively adopting a depth estimation pipeline to fuse the two modalities requires groundtruth depth maps for supervision. To address this, we propose a self-supervised learning framework, SelfToF, which generates detailed and scale-aware depth maps. Starting from an image-based self-supervised depth estimation pipeline, we add low-resolution depth as inputs, design a new depth consistency loss, propose a scale-recovery module, and finally obtain a large performance boost. Furthermore, since the ToF signal sparsity varies in real-world applications, we upgrade SelfToF to SelfToF* with submanifold convolution and guided feature fusion. Consequently, SelfToF* maintain robust performance across varying sparsity levels in ToF data. Overall, our proposed method is both efficient and effective, as verified by extensive experiments on the NYU and ScanNet datasets. The code will be made public.
DEFOM-Stereo: Depth Foundation Model Based Stereo Matching
Jan 16, 2025



Stereo matching is a key technique for metric depth estimation in computer vision and robotics. Real-world challenges like occlusion and non-texture hinder accurate disparity estimation from binocular matching cues. Recently, monocular relative depth estimation has shown remarkable generalization using vision foundation models. Thus, to facilitate robust stereo matching with monocular depth cues, we incorporate a robust monocular relative depth model into the recurrent stereo-matching framework, building a new framework for depth foundation model-based stereo-matching, DEFOM-Stereo. In the feature extraction stage, we construct the combined context and matching feature encoder by integrating features from conventional CNNs and DEFOM. In the update stage, we use the depth predicted by DEFOM to initialize the recurrent disparity and introduce a scale update module to refine the disparity at the correct scale. DEFOM-Stereo is verified to have comparable performance on the Scene Flow dataset with state-of-the-art (SOTA) methods and notably shows much stronger zero-shot generalization. Moreover, DEFOM-Stereo achieves SOTA performance on the KITTI 2012, KITTI 2015, Middlebury, and ETH3D benchmarks, ranking 1st on many metrics. In the joint evaluation under the robust vision challenge, our model simultaneously outperforms previous models on the individual benchmarks. Both results demonstrate the outstanding capabilities of the proposed model.
CFPNet: Improving Lightweight ToF Depth Completion via Cross-zone Feature Propagation
Nov 07, 2024


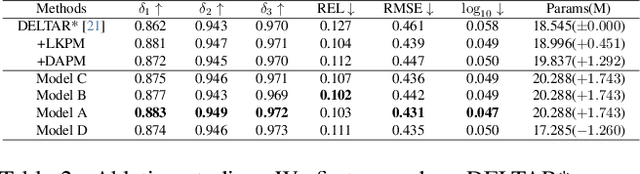
Depth completion using lightweight time-of-flight (ToF) depth sensors is attractive due to their low cost. However, lightweight ToF sensors usually have a limited field of view (FOV) compared with cameras. Thus, only pixels in the zone area of the image can be associated with depth signals. Previous methods fail to propagate depth features from the zone area to the outside-zone area effectively, thus suffering from degraded depth completion performance outside the zone. To this end, this paper proposes the CFPNet to achieve cross-zone feature propagation from the zone area to the outside-zone area with two novel modules. The first is a direct-attention-based propagation module (DAPM), which enforces direct cross-zone feature acquisition. The second is a large-kernel-based propagation module (LKPM), which realizes cross-zone feature propagation by utilizing convolution layers with kernel sizes up to 31. CFPNet achieves state-of-the-art (SOTA) depth completion performance by combining these two modules properly, as verified by extensive experimental results on the ZJU-L5 dataset. The code will be made public.
ROA-BEV: 2D Region-Oriented Attention for BEV-based 3D Object
Oct 14, 2024



Vision-based BEV (Bird-Eye-View) 3D object detection has recently become popular in autonomous driving. However, objects with a high similarity to the background from a camera perspective cannot be detected well by existing methods. In this paper, we propose 2D Region-oriented Attention for a BEV-based 3D Object Detection Network (ROA-BEV), which can make the backbone focus more on feature learning in areas where objects may exist. Moreover, our method increases the information content of ROA through a multi-scale structure. In addition, every block of ROA utilizes a large kernel to ensure that the receptive field is large enough to catch large objects' information. Experiments on nuScenes show that ROA-BEV improves the performance based on BEVDet and BEVDepth. The code will be released soon.
Towards Cross-View-Consistent Self-Supervised Surround Depth Estimation
Jul 04, 2024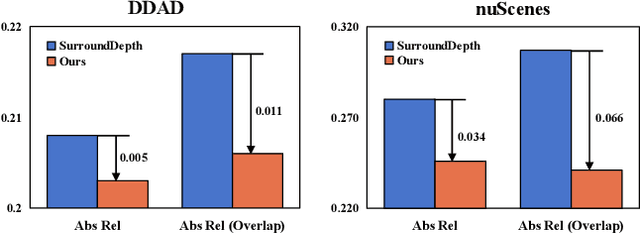
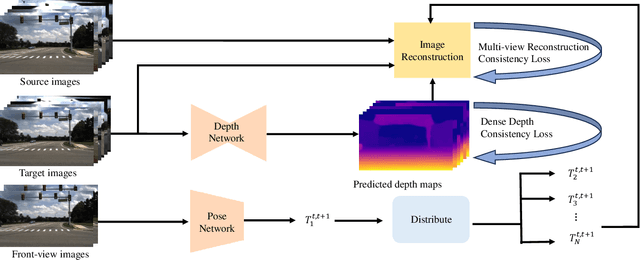
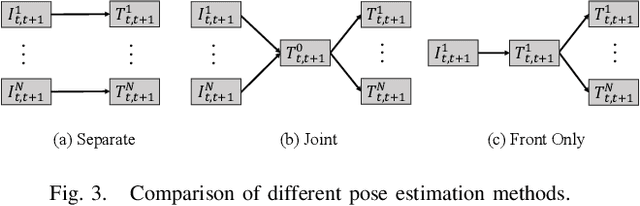

Depth estimation is a cornerstone for autonomous driving, yet acquiring per-pixel depth ground truth for supervised learning is challenging. Self-Supervised Surround Depth Estimation (SSSDE) from consecutive images offers an economical alternative. While previous SSSDE methods have proposed different mechanisms to fuse information across images, few of them explicitly consider the cross-view constraints, leading to inferior performance, particularly in overlapping regions. This paper proposes an efficient and consistent pose estimation design and two loss functions to enhance cross-view consistency for SSSDE. For pose estimation, we propose to use only front-view images to reduce training memory and sustain pose estimation consistency. The first loss function is the dense depth consistency loss, which penalizes the difference between predicted depths in overlapping regions. The second one is the multi-view reconstruction consistency loss, which aims to maintain consistency between reconstruction from spatial and spatial-temporal contexts. Additionally, we introduce a novel flipping augmentation to improve the performance further. Our techniques enable a simple neural model to achieve state-of-the-art performance on the DDAD and nuScenes datasets. Last but not least, our proposed techniques can be easily applied to other methods. The code will be made public.
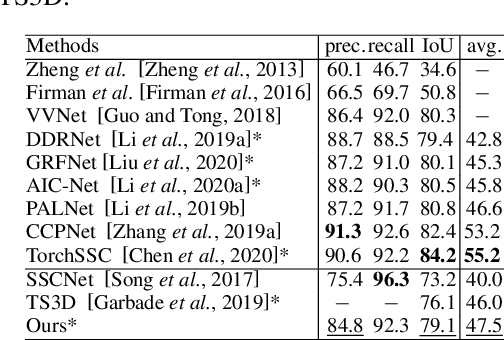
Towards Balanced RGB-TSDF Fusion for Consistent Semantic Scene Completion by 3D RGB Feature Completion and a Classwise Entropy Loss Function
Mar 25, 2024Semantic Scene Completion (SSC) aims to jointly infer semantics and occupancies of 3D scenes. Truncated Signed Distance Function (TSDF), a 3D encoding of depth, has been a common input for SSC. Furthermore, RGB-TSDF fusion, seems promising since these two modalities provide color and geometry information, respectively. Nevertheless, RGB-TSDF fusion has been considered nontrivial and commonly-used naive addition will result in inconsistent results. We argue that the inconsistency comes from the sparsity of RGB features upon projecting into 3D space, while TSDF features are dense, leading to imbalanced feature maps when summed up. To address this RGB-TSDF distribution difference, we propose a two-stage network with a 3D RGB feature completion module that completes RGB features with meaningful values for occluded areas. Moreover, we propose an effective classwise entropy loss function to punish inconsistency. Extensive experiments on public datasets verify that our method achieves state-of-the-art performance among methods that do not adopt extra data.
PLNet: Plane and Line Priors for Unsupervised Indoor Depth Estimation
Oct 12, 2021
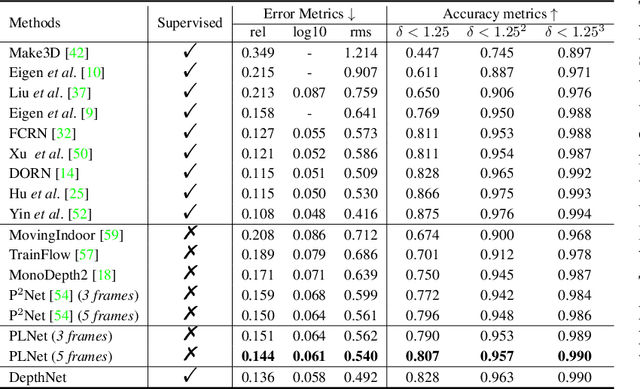
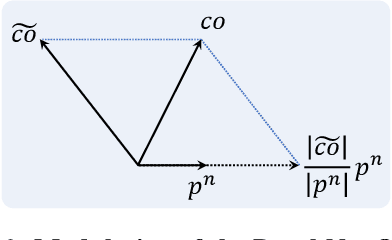

Unsupervised learning of depth from indoor monocular videos is challenging as the artificial environment contains many textureless regions. Fortunately, the indoor scenes are full of specific structures, such as planes and lines, which should help guide unsupervised depth learning. This paper proposes PLNet that leverages the plane and line priors to enhance the depth estimation. We first represent the scene geometry using local planar coefficients and impose the smoothness constraint on the representation. Moreover, we enforce the planar and linear consistency by randomly selecting some sets of points that are probably coplanar or collinear to construct simple and effective consistency losses. To verify the proposed method's effectiveness, we further propose to evaluate the flatness and straightness of the predicted point cloud on the reliable planar and linear regions. The regularity of these regions indicates quality indoor reconstruction. Experiments on NYU Depth V2 and ScanNet show that PLNet outperforms existing methods. The code is available at \url{https://github.com/HalleyJiang/PLNet}.
Unsupervised Monocular Depth Perception: Focusing on Moving Objects
Aug 30, 2021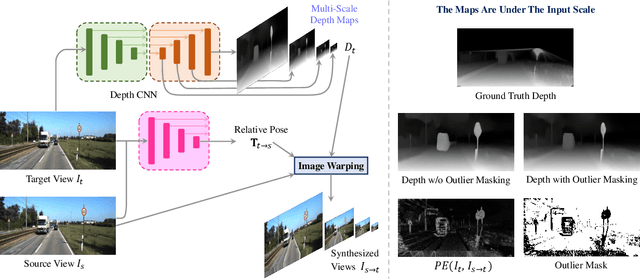
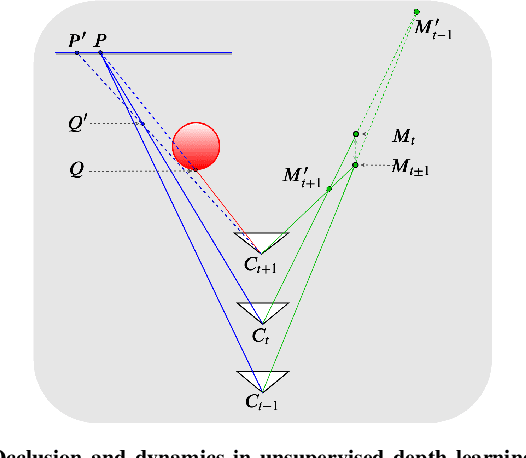
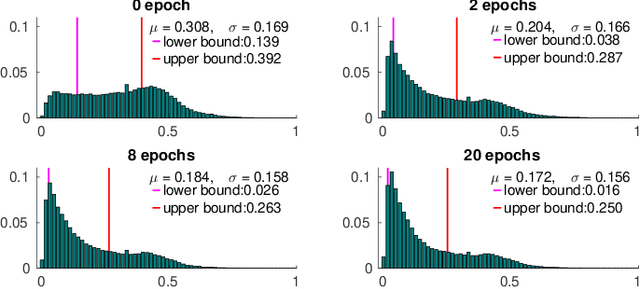
As a flexible passive 3D sensing means, unsupervised learning of depth from monocular videos is becoming an important research topic. It utilizes the photometric errors between the target view and the synthesized views from its adjacent source views as the loss instead of the difference from the ground truth. Occlusion and scene dynamics in real-world scenes still adversely affect the learning, despite significant progress made recently. In this paper, we show that deliberately manipulating photometric errors can efficiently deal with these difficulties better. We first propose an outlier masking technique that considers the occluded or dynamic pixels as statistical outliers in the photometric error map. With the outlier masking, the network learns the depth of objects that move in the opposite direction to the camera more accurately. To the best of our knowledge, such cases have not been seriously considered in the previous works, even though they pose a high risk in applications like autonomous driving. We also propose an efficient weighted multi-scale scheme to reduce the artifacts in the predicted depth maps. Extensive experiments on the KITTI dataset and additional experiments on the Cityscapes dataset have verified the proposed approach's effectiveness on depth or ego-motion estimation. Furthermore, for the first time, we evaluate the predicted depth on the regions of dynamic objects and static background separately for both supervised and unsupervised methods. The evaluation further verifies the effectiveness of our proposed technical approach and provides some interesting observations that might inspire future research in this direction.
IMENet: Joint 3D Semantic Scene Completion and 2D Semantic Segmentation through Iterative Mutual Enhancement
Jun 29, 2021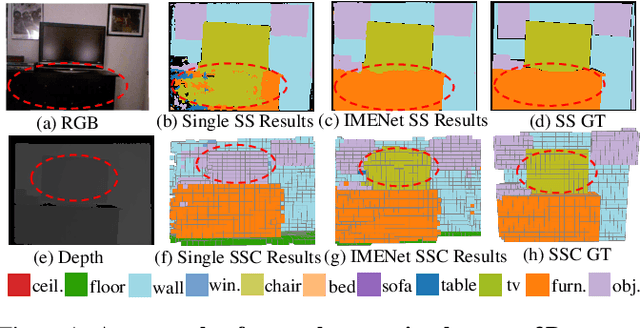
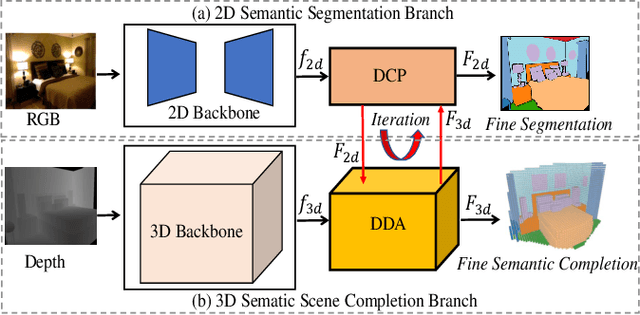
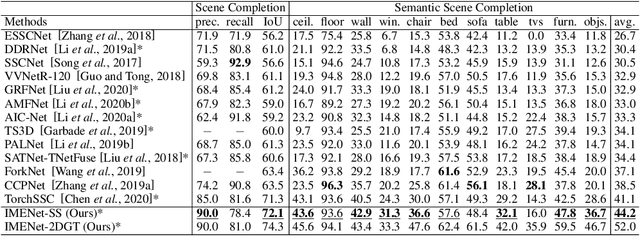
3D semantic scene completion and 2D semantic segmentation are two tightly correlated tasks that are both essential for indoor scene understanding, because they predict the same semantic classes, using positively correlated high-level features. Current methods use 2D features extracted from early-fused RGB-D images for 2D segmentation to improve 3D scene completion. We argue that this sequential scheme does not ensure these two tasks fully benefit each other, and present an Iterative Mutual Enhancement Network (IMENet) to solve them jointly, which interactively refines the two tasks at the late prediction stage. Specifically, two refinement modules are developed under a unified framework for the two tasks. The first is a 2D Deformable Context Pyramid (DCP) module, which receives the projection from the current 3D predictions to refine the 2D predictions. In turn, a 3D Deformable Depth Attention (DDA) module is proposed to leverage the reprojected results from 2D predictions to update the coarse 3D predictions. This iterative fusion happens to the stable high-level features of both tasks at a late stage. Extensive experiments on NYU and NYUCAD datasets verify the effectiveness of the proposed iterative late fusion scheme, and our approach outperforms the state of the art on both 3D semantic scene completion and 2D semantic segmentation.
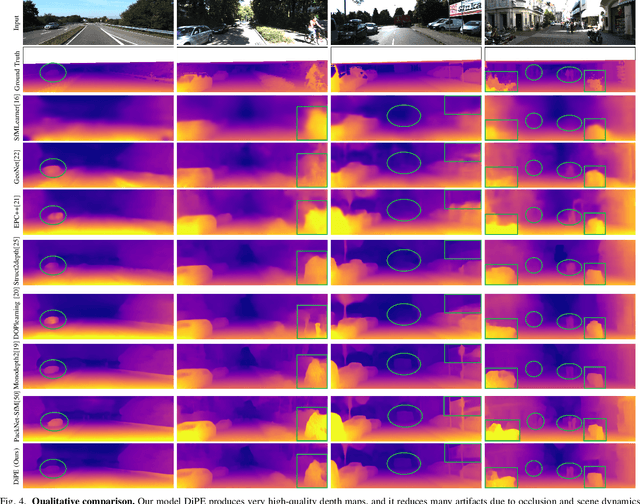
DiPE: Deeper into Photometric Errors for Unsupervised Learning of Depth and Ego-motion from Monocular Videos
Mar 03, 2020
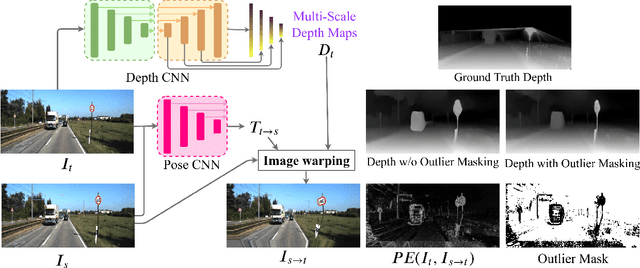
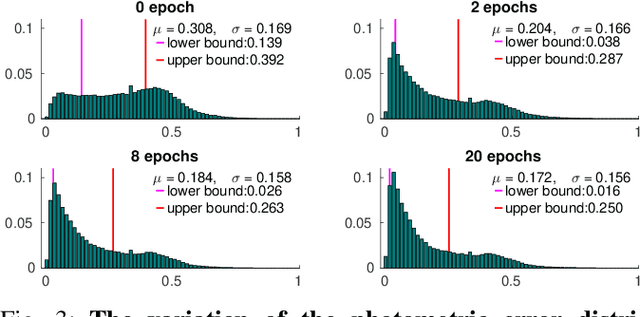
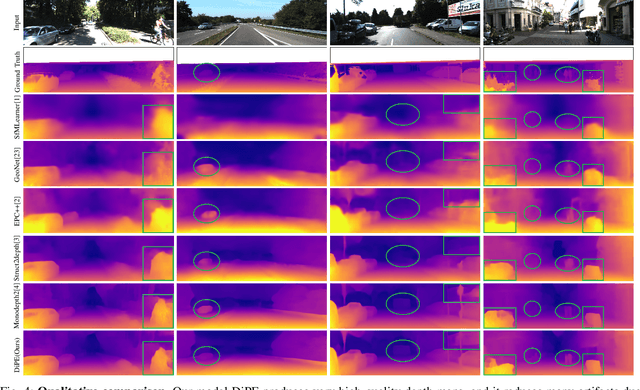
Unsupervised learning of depth and ego-motion from unlabelled monocular videos has recently drawn attention as it has notable advantages than the supervised ones. It uses the photometric errors between the target view and the synthesized views from its adjacent source views as the loss. Although significant progress has been made, the learning still suffers from occlusion and scene dynamics. This paper shows that carefully manipulating photometric errors can tackle these difficulties better. The primary improvement is achieved by masking out the invisible or nonstationary pixels in the photometric error map using a statistical technique. With this outlier masking approach, the depth of objects that move in the opposite direction to the camera can be estimated more accurately. According to our best knowledge, such objects have not been seriously considered in the previous work, even though they pose a higher risk in applications like autonomous driving. We also propose an efficient weighted multi-scale scheme to reduce the artifacts in the predicted depth maps. Extensive experiments on the KITTI dataset show the effectiveness of the proposed approaches. The overall system achieves state-of-the-art performance on both depth and ego-motion estimation.