 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Anything in $360^\circ$: Towards Scale Invariance in the Wild
Dec 28, 2025Panoramic depth estimation provides a comprehensive solution for capturing complete $360^\circ$ environmental structural information, offering significant benefits for robotics and AR/VR applications. However, while extensively studied in indoor settings, its zero-shot generalization to open-world domains lags far behind perspective images, which benefit from abundant training data. This disparity makes transferring capabilities from the perspective domain an attractive solution. To bridge this gap, we present Depth Anything in $360^\circ$ (DA360), a panoramic-adapted version of Depth Anything V2. Our key innovation involves learning a shift parameter from the ViT backbone, transforming the model's scale- and shift-invariant output into a scale-invariant estimate that directly yields well-formed 3D point clouds. This is complemented by integrating circular padding into the DPT decoder to eliminate seam artifacts, ensuring spatially coherent depth maps that respect spherical continuity. Evaluated on standard indoor benchmarks and our newly curated outdoor dataset, Metropolis, DA360 shows substantial gains over its base model, achieving over 50\% and 10\% relative depth error reduction on indoor and outdoor benchmarks, respectively. Furthermore, DA360 significantly outperforms robust panoramic depth estimation methods, achieving about 30\% relative error improvement compared to PanDA across all three test datasets and establishing new state-of-the-art performance for zero-shot panoramic depth estimation.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
DEFOM-Stereo: Depth Foundation Model Based Stereo Matching
Jan 16, 2025



Stereo matching is a key technique for metric depth estimation in computer vision and robotics. Real-world challenges like occlusion and non-texture hinder accurate disparity estimation from binocular matching cues. Recently, monocular relative depth estimation has shown remarkable generalization using vision foundation models. Thus, to facilitate robust stereo matching with monocular depth cues, we incorporate a robust monocular relative depth model into the recurrent stereo-matching framework, building a new framework for depth foundation model-based stereo-matching, DEFOM-Stereo. In the feature extraction stage, we construct the combined context and matching feature encoder by integrating features from conventional CNNs and DEFOM. In the update stage, we use the depth predicted by DEFOM to initialize the recurrent disparity and introduce a scale update module to refine the disparity at the correct scale. DEFOM-Stereo is verified to have comparable performance on the Scene Flow dataset with state-of-the-art (SOTA) methods and notably shows much stronger zero-shot generalization. Moreover, DEFOM-Stereo achieves SOTA performance on the KITTI 2012, KITTI 2015, Middlebury, and ETH3D benchmarks, ranking 1st on many metrics. In the joint evaluation under the robust vision challenge, our model simultaneously outperforms previous models on the individual benchmarks. Both results demonstrate the outstanding capabilities of the proposed model.
SST: Real-time End-to-end Monocular 3D Reconstruction via Sparse Spatial-Temporal Guidance
Dec 13, 2022Real-time monocular 3D reconstruction is a challenging problem that remains unsolved. Although recent end-to-end methods have demonstrated promising results, tiny structures and geometric boundaries are hardly captured due to their insufficient supervision neglecting spatial details and oversimplified feature fusion ignoring temporal cues. To address the problems, we propose an end-to-end 3D reconstruction network SST, which utilizes Sparse estimated points from visual SLAM system as additional Spatial guidance and fuses Temporal features via a novel cross-modal attention mechanism, achieving more detailed reconstruction results. We propose a Local Spatial-Temporal Fusion module to exploit more informative spatial-temporal cues from multi-view color information and sparse priors, as well a Global Spatial-Temporal Fusion module to refine the local TSDF volumes with the world-frame model from coarse to fine. Extensive experiments on ScanNet and 7-Scenes demonstrate that SST outperforms all state-of-the-art competitors, whilst keeping a high inference speed at 59 FPS, enabling real-world applications with real-time requirements.
RBP-Pose: Residual Bounding Box Projection for Category-Level Pose Estimation
Jul 30, 2022
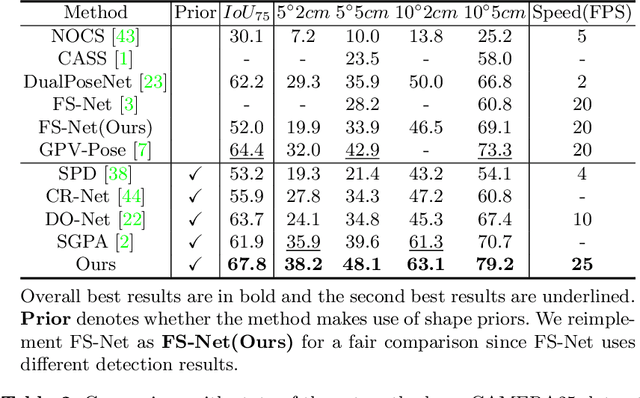


Category-level object pose estimation aims to predict the 6D pose as well as the 3D metric size of arbitrary objects from a known set of categories. Recent methods harness shape prior adaptation to map the observed point cloud into the canonical space and apply Umeyama algorithm to recover the pose and size. However, their shape prior integration strategy boosts pose estimation indirectly, which leads to insufficient pose-sensitive feature extraction and slow inference speed. To tackle this problem, in this paper, we propose a novel geometry-guided Residual Object Bounding Box Projection network RBP-Pose that jointly predicts object pose and residual vectors describing the displacements from the shape-prior-indicated object surface projections on the bounding box towards the real surface projections. Such definition of residual vectors is inherently zero-mean and relatively small, and explicitly encapsulates spatial cues of the 3D object for robust and accurate pose regression. We enforce geometry-aware consistency terms to align the predicted pose and residual vectors to further boost performance.
GPV-Pose: Category-level Object Pose Estimation via Geometry-guided Point-wise Voting
Mar 17, 2022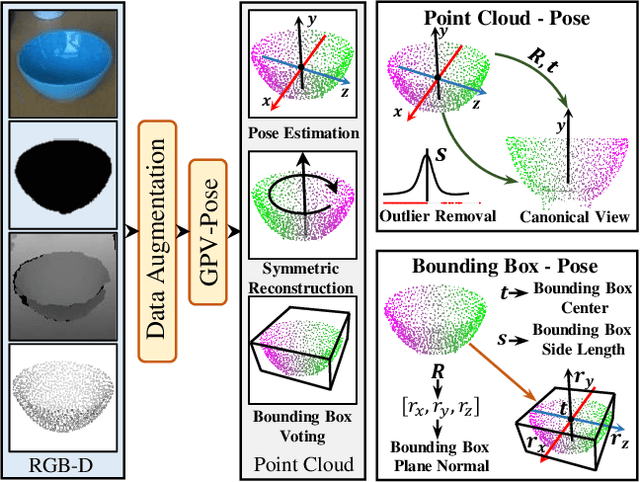



While 6D object pose estimation has recently made a huge leap forward, most methods can still only handle a single or a handful of different objects, which limits their applications. To circumvent this problem, category-level object pose estimation has recently been revamped, which aims at predicting the 6D pose as well as the 3D metric size for previously unseen instances from a given set of object classes. This is, however, a much more challenging task due to severe intra-class shape variations. To address this issue, we propose GPV-Pose, a novel framework for robust category-level pose estimation, harnessing geometric insights to enhance the learning of category-level pose-sensitive features. First, we introduce a decoupled confidence-driven rotation representation, which allows geometry-aware recovery of the associated rotation matrix. Second, we propose a novel geometry-guided point-wise voting paradigm for robust retrieval of the 3D object bounding box. Finally, leveraging these different output streams, we can enforce several geometric consistency terms, further increasing performance, especially for non-symmetric categories. GPV-Pose produces superior results to state-of-the-art competitors on common public benchmarks, whilst almost achieving real-time inference speed at 20 FPS.