 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Anything in $360^\circ$: Towards Scale Invariance in the Wild
Dec 28, 2025Panoramic depth estimation provides a comprehensive solution for capturing complete $360^\circ$ environmental structural information, offering significant benefits for robotics and AR/VR applications. However, while extensively studied in indoor settings, its zero-shot generalization to open-world domains lags far behind perspective images, which benefit from abundant training data. This disparity makes transferring capabilities from the perspective domain an attractive solution. To bridge this gap, we present Depth Anything in $360^\circ$ (DA360), a panoramic-adapted version of Depth Anything V2. Our key innovation involves learning a shift parameter from the ViT backbone, transforming the model's scale- and shift-invariant output into a scale-invariant estimate that directly yields well-formed 3D point clouds. This is complemented by integrating circular padding into the DPT decoder to eliminate seam artifacts, ensuring spatially coherent depth maps that respect spherical continuity. Evaluated on standard indoor benchmarks and our newly curated outdoor dataset, Metropolis, DA360 shows substantial gains over its base model, achieving over 50\% and 10\% relative depth error reduction on indoor and outdoor benchmarks, respectively. Furthermore, DA360 significantly outperforms robust panoramic depth estimation methods, achieving about 30\% relative error improvement compared to PanDA across all three test datasets and establishing new state-of-the-art performance for zero-shot panoramic depth estimation.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
DEFOM-Stereo: Depth Foundation Model Based Stereo Matching
Jan 16, 2025Stereo matching is a key technique for metric depth estimation in computer vision and robotics. Real-world challenges like occlusion and non-texture hinder accurate disparity estimation from binocular matching cues. Recently, monocular relative depth estimation has shown remarkable generalization using vision foundation models. Thus, to facilitate robust stereo matching with monocular depth cues, we incorporate a robust monocular relative depth model into the recurrent stereo-matching framework, building a new framework for depth foundation model-based stereo-matching, DEFOM-Stereo. In the feature extraction stage, we construct the combined context and matching feature encoder by integrating features from conventional CNNs and DEFOM. In the update stage, we use the depth predicted by DEFOM to initialize the recurrent disparity and introduce a scale update module to refine the disparity at the correct scale. DEFOM-Stereo is verified to have comparable performance on the Scene Flow dataset with state-of-the-art (SOTA) methods and notably shows much stronger zero-shot generalization. Moreover, DEFOM-Stereo achieves SOTA performance on the KITTI 2012, KITTI 2015, Middlebury, and ETH3D benchmarks, ranking 1st on many metrics. In the joint evaluation under the robust vision challenge, our model simultaneously outperforms previous models on the individual benchmarks. Both results demonstrate the outstanding capabilities of the proposed model.
RomniStereo: Recurrent Omnidirectional Stereo Matching
Jan 26, 2024



Omnidirectional stereo matching (OSM) is an essential and reliable means for $360^{\circ}$ depth sensing. However, following earlier works on conventional stereo matching, prior state-of-the-art (SOTA) methods rely on a 3D encoder-decoder block to regularize the cost volume, causing the whole system complicated and sub-optimal results. Recently, the Recurrent All-pairs Field Transforms (RAFT) based approach employs the recurrent update in 2D and has efficiently improved image-matching tasks, ie, optical flow, and stereo matching. To bridge the gap between OSM and RAFT, we mainly propose an opposite adaptive weighting scheme to seamlessly transform the outputs of spherical sweeping of OSM into the required inputs for the recurrent update, thus creating a recurrent omnidirectional stereo matching (RomniStereo) algorithm. Furthermore, we introduce two techniques, ie, grid embedding and adaptive context feature generation, which also contribute to RomniStereo's performance. Our best model improves the average MAE metric by 40.7\% over the previous SOTA baseline across five datasets. When visualizing the results, our models demonstrate clear advantages on both synthetic and realistic examples. The code is available at \url{https://github.com/HalleyJiang/RomniStereo}.
Tightly-coupled Monocular Visual-odometric SLAM using Wheels and a MEMS Gyroscope
Apr 13, 2018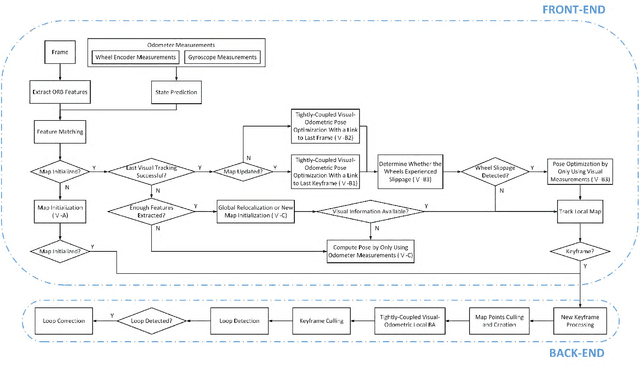
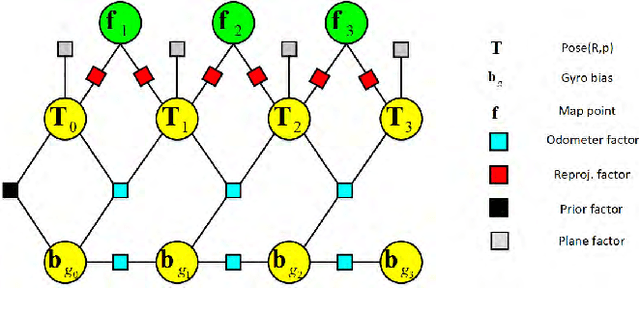

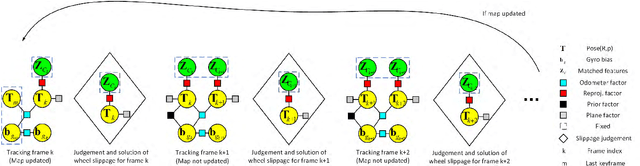
In this paper, we present a novel tightly-coupled probabilistic monocular visual-odometric Simultaneous Localization and Mapping algorithm using wheels and a MEMS gyroscope, which can provide accurate, robust and long-term localization for the ground robot moving on a plane. Firstly, we present an odometer preintegration theory that integrates the wheel encoder measurements and gyroscope measurements to a local frame. The preintegration theory properly addresses the manifold structure of the rotation group SO(3) and carefully deals with uncertainty propagation and bias correction. Then the novel odometer error term is formulated using the odometer preintegration model and it is tightly integrated into the visual optimization framework. Furthermore, we introduce a complete tracking framework to provide different strategies for motion tracking when (1) both measurements are available, (2) visual measurements are not available, and (3) wheel encoder experiences slippage, which leads the system to be accurate and robust. Finally, the proposed algorithm is evaluated by performing extensive experiments, the experimental results demonstrate the superiority of the proposed system.
Accurate Monocular Visual-inertial SLAM using a Map-assisted EKF Approach
Mar 31, 2018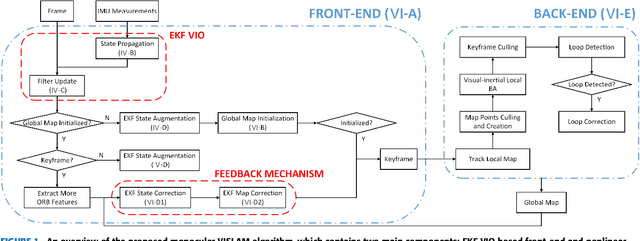
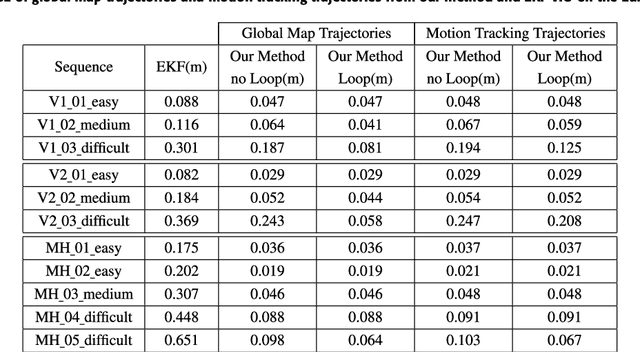
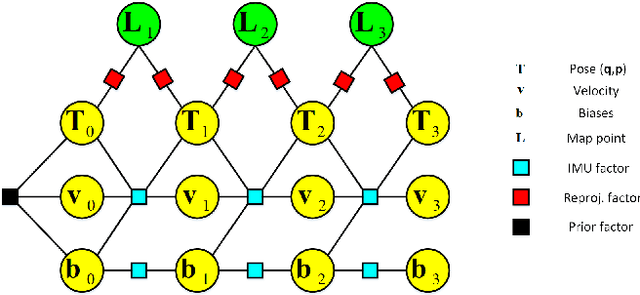
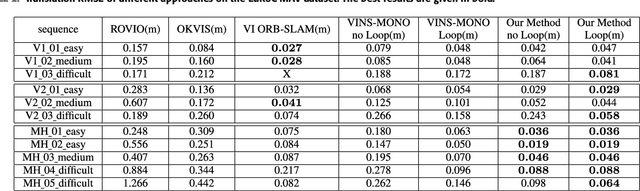
This paper presents a novel tightly-coupled monocular visual-inertial Simultaneous Localization and Mapping algorithm, which provides accurate and robust localization within the globally consistent map in real time on a standard CPU. This is achieved by firstly performing the visual-inertial extended kalman filter(EKF) to provide motion estimate at a high rate. However the filter becomes inconsistent due to the well known linearization issues. So we perform a keyframe-based visual-inertial bundle adjustment to improve the consistency and accuracy of the system. In addition, a loop closure detection and correction module is also added to eliminate the accumulated drift when revisiting an area. Finally, the optimized motion estimates and map are fed back to the EKF-based visual-inertial odometry module, thus the inconsistency and estimation error of the EKF estimator are reduced. In this way, the system can continuously provide reliable motion estimates for the long-term operation. The performance of the algorithm is validated on public datasets and real-world experiments, which proves the superiority of the proposed algorithm.