 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVistaGEN: Consistent Driving Video Generation with Fine-Grained Control Using Multiview Visual-Language Reasoning
Mar 30, 2026Driving video generation has achieved much progress in controllability, video resolution, and length, but fails to support fine-grained object-level controllability for diverse driving videos, while preserving the spatiotemporal consistency, especially in long video generation. In this paper, we present a new driving video generation technique, called VistaGEN, which enables fine-grained control of specific entities, including 3D objects, images, and text descriptions, while maintaining spatiotemporal consistency in long video sequences. Our key innovation is the incorporation of multiview visual-language reasoning into the long driving video generation. To this end, we inject visual-language features into a multiview video generator to enable fine-grained controllability. More importantly, we propose a multiview vision-language evaluator (MV-VLM) to intelligently and automatically evaluate spatiotemporal consistency of the generated content, thus formulating a novel generation-evaluation-regeneration closed-loop generation mechanism. This mechanism ensures high-quality, coherent outputs, facilitating the creation of complex and reliable driving scenarios. Besides, within the closed-loop generation, we introduce an object-level refinement module to refine the unsatisfied results evaluated from the MV-VLM and then feed them back to the video generator for regeneration. Extensive evaluation shows that our VistaGEN achieves diverse driving video generation results with fine-grained controllability, especially for long-tail objects, and much better spatiotemporal consistency than previous approaches.
HybridSplat: Fast Reflection-baked Gaussian Tracing using Hybrid Splatting
Dec 15, 2025
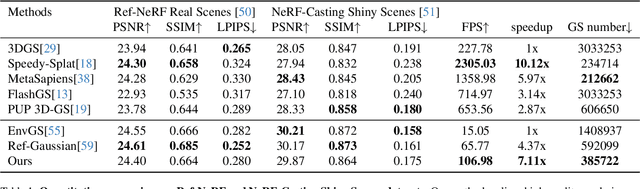


Rendering complex reflection of real-world scenes using 3D Gaussian splatting has been a quite promising solution for photorealistic novel view synthesis, but still faces bottlenecks especially in rendering speed and memory storage. This paper proposes a new Hybrid Splatting(HybridSplat) mechanism for Gaussian primitives. Our key idea is a new reflection-baked Gaussian tracing, which bakes the view-dependent reflection within each Gaussian primitive while rendering the reflection using tile-based Gaussian splatting. Then we integrate the reflective Gaussian primitives with base Gaussian primitives using a unified hybrid splatting framework for high-fidelity scene reconstruction. Moreover, we further introduce a pipeline-level acceleration for the hybrid splatting, and reflection-sensitive Gaussian pruning to reduce the model size, thus achieving much faster rendering speed and lower memory storage while preserving the reflection rendering quality. By extensive evaluation, our HybridSplat accelerates about 7x rendering speed across complex reflective scenes from Ref-NeRF, NeRF-Casting with 4x fewer Gaussian primitives than similar ray-tracing based Gaussian splatting baselines, serving as a new state-of-the-art method especially for complex reflective scenes.
RTMap: Real-Time Recursive Mapping with Change Detection and Localization
Jul 01, 2025While recent online HD mapping methods relieve burdened offline pipelines and solve map freshness, they remain limited by perceptual inaccuracies, occlusion in dense traffic, and an inability to fuse multi-agent observations. We propose RTMap to enhance these single-traversal methods by persistently crowdsourcing a multi-traversal HD map as a self-evolutional memory. On onboard agents, RTMap simultaneously addresses three core challenges in an end-to-end fashion: (1) Uncertainty-aware positional modeling for HD map elements, (2) probabilistic-aware localization w.r.t. the crowdsourced prior-map, and (3) real-time detection for possible road structural changes. Experiments on several public autonomous driving datasets demonstrate our solid performance on both the prior-aided map quality and the localization accuracy, demonstrating our effectiveness of robustly serving downstream prediction and planning modules while gradually improving the accuracy and freshness of the crowdsourced prior-map asynchronously. Our source-code will be made publicly available at https://github.com/CN-ADLab/RTMap (Camera ready version incorporating reviewer suggestions will be updated soon).
GCRayDiffusion: Pose-Free Surface Reconstruction via Geometric Consistent Ray Diffusion
Mar 28, 2025Accurate surface reconstruction from unposed images is crucial for efficient 3D object or scene creation. However, it remains challenging, particularly for the joint camera pose estimation. Previous approaches have achieved impressive pose-free surface reconstruction results in dense-view settings, but could easily fail for sparse-view scenarios without sufficient visual overlap. In this paper, we propose a new technique for pose-free surface reconstruction, which follows triplane-based signed distance field (SDF) learning but regularizes the learning by explicit points sampled from ray-based diffusion of camera pose estimation. Our key contribution is a novel Geometric Consistent Ray Diffusion model (GCRayDiffusion), where we represent camera poses as neural bundle rays and regress the distribution of noisy rays via a diffusion model. More importantly, we further condition the denoising process of RGRayDiffusion using the triplane-based SDF of the entire scene, which provides effective 3D consistent regularization to achieve multi-view consistent camera pose estimation. Finally, we incorporate RGRayDiffusion into the triplane-based SDF learning by introducing on-surface geometric regularization from the sampling points of the neural bundle rays, which leads to highly accurate pose-free surface reconstruction results even for sparse-view inputs. Extensive evaluations on public datasets show that our GCRayDiffusion achieves more accurate camera pose estimation than previous approaches, with geometrically more consistent surface reconstruction results, especially given sparse-view inputs.
MixLight: Borrowing the Best of both Spherical Harmonics and Gaussian Models
Apr 19, 2024Accurately estimating scene lighting is critical for applications such as mixed reality. Existing works estimate illumination by generating illumination maps or regressing illumination parameters. However, the method of generating illumination maps has poor generalization performance and parametric models such as Spherical Harmonic (SH) and Spherical Gaussian (SG) fall short in capturing high-frequency or low-frequency components. This paper presents MixLight, a joint model that utilizes the complementary characteristics of SH and SG to achieve a more complete illumination representation, which uses SH and SG to capture low-frequency ambient and high-frequency light sources respectively. In addition, a special spherical light source sparsemax (SLSparsemax) module that refers to the position and brightness relationship between spherical light sources is designed to improve their sparsity, which is significant but omitted by prior works. Extensive experiments demonstrate that MixLight surpasses state-of-the-art (SOTA) methods on multiple metrics. In addition, experiments on Web Dataset also show that MixLight as a parametric method has better generalization performance than non-parametric methods.
Self-Supervised Depth Completion Guided by 3D Perception and Geometry Consistency
Dec 23, 2023
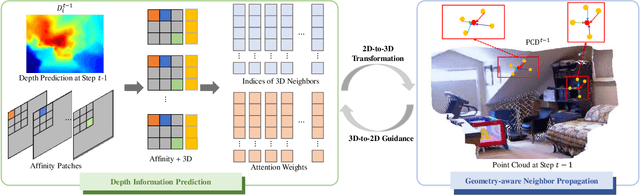


Depth completion, aiming to predict dense depth maps from sparse depth measurements, plays a crucial role in many computer vision related applications. Deep learning approaches have demonstrated overwhelming success in this task. However, high-precision depth completion without relying on the ground-truth data, which are usually costly, still remains challenging. The reason lies on the ignorance of 3D structural information in most previous unsupervised solutions, causing inaccurate spatial propagation and mixed-depth problems. To alleviate the above challenges, this paper explores the utilization of 3D perceptual features and multi-view geometry consistency to devise a high-precision self-supervised depth completion method. Firstly, a 3D perceptual spatial propagation algorithm is constructed with a point cloud representation and an attention weighting mechanism to capture more reasonable and favorable neighboring features during the iterative depth propagation process. Secondly, the multi-view geometric constraints between adjacent views are explicitly incorporated to guide the optimization of the whole depth completion model in a self-supervised manner. Extensive experiments on benchmark datasets of NYU-Depthv2 and VOID demonstrate that the proposed model achieves the state-of-the-art depth completion performance compared with other unsupervised methods, and competitive performance compared with previous supervised methods.
Sparse3D: Distilling Multiview-Consistent Diffusion for Object Reconstruction from Sparse Views
Aug 27, 2023Reconstructing 3D objects from extremely sparse views is a long-standing and challenging problem. While recent techniques employ image diffusion models for generating plausible images at novel viewpoints or for distilling pre-trained diffusion priors into 3D representations using score distillation sampling (SDS), these methods often struggle to simultaneously achieve high-quality, consistent, and detailed results for both novel-view synthesis (NVS) and geometry. In this work, we present Sparse3D, a novel 3D reconstruction method tailored for sparse view inputs. Our approach distills robust priors from a multiview-consistent diffusion model to refine a neural radiance field. Specifically, we employ a controller that harnesses epipolar features from input views, guiding a pre-trained diffusion model, such as Stable Diffusion, to produce novel-view images that maintain 3D consistency with the input. By tapping into 2D priors from powerful image diffusion models, our integrated model consistently delivers high-quality results, even when faced with open-world objects. To address the blurriness introduced by conventional SDS, we introduce the category-score distillation sampling (C-SDS) to enhance detail. We conduct experiments on CO3DV2 which is a multi-view dataset of real-world objects. Both quantitative and qualitative evaluations demonstrate that our approach outperforms previous state-of-the-art works on the metrics regarding NVS and geometry reconstruction.
SC-NeuS: Consistent Neural Surface Reconstruction from Sparse and Noisy Views
Jul 12, 2023The recent neural surface reconstruction by volume rendering approaches have made much progress by achieving impressive surface reconstruction quality, but are still limited to dense and highly accurate posed views. To overcome such drawbacks, this paper pays special attention on the consistent surface reconstruction from sparse views with noisy camera poses. Unlike previous approaches, the key difference of this paper is to exploit the multi-view constraints directly from the explicit geometry of the neural surface, which can be used as effective regularization to jointly learn the neural surface and refine the camera poses. To build effective multi-view constraints, we introduce a fast differentiable on-surface intersection to generate on-surface points, and propose view-consistent losses based on such differentiable points to regularize the neural surface learning. Based on this point, we propose a jointly learning strategy for neural surface and camera poses, named SC-NeuS, to perform geometry-consistent surface reconstruction in an end-to-end manner. With extensive evaluation on public datasets, our SC-NeuS can achieve consistently better surface reconstruction results with fine-grained details than previous state-of-the-art neural surface reconstruction approaches, especially from sparse and noisy camera views.
MonoNeuralFusion: Online Monocular Neural 3D Reconstruction with Geometric Priors
Sep 30, 2022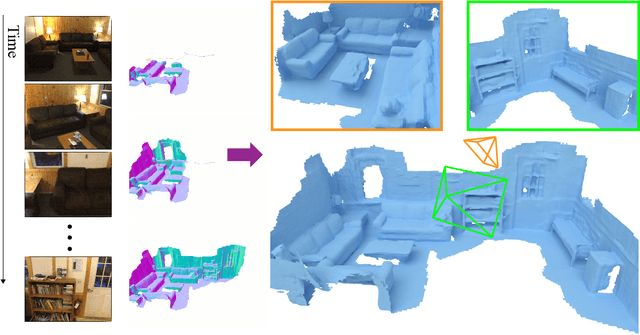
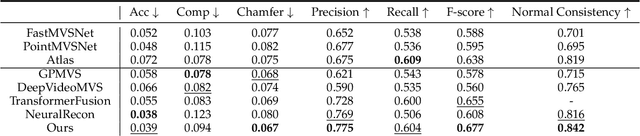
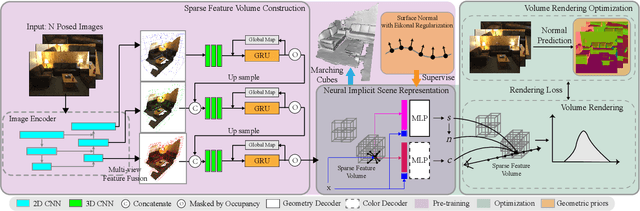
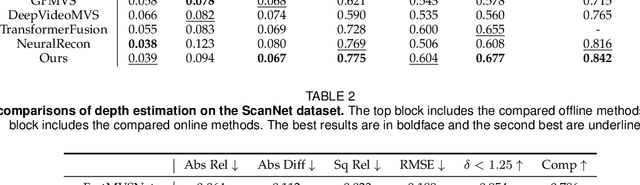
High-fidelity 3D scene reconstruction from monocular videos continues to be challenging, especially for complete and fine-grained geometry reconstruction. The previous 3D reconstruction approaches with neural implicit representations have shown a promising ability for complete scene reconstruction, while their results are often over-smooth and lack enough geometric details. This paper introduces a novel neural implicit scene representation with volume rendering for high-fidelity online 3D scene reconstruction from monocular videos. For fine-grained reconstruction, our key insight is to incorporate geometric priors into both the neural implicit scene representation and neural volume rendering, thus leading to an effective geometry learning mechanism based on volume rendering optimization. Benefiting from this, we present MonoNeuralFusion to perform the online neural 3D reconstruction from monocular videos, by which the 3D scene geometry is efficiently generated and optimized during the on-the-fly 3D monocular scanning. The extensive comparisons with state-of-the-art approaches show that our MonoNeuralFusion consistently generates much better complete and fine-grained reconstruction results, both quantitatively and qualitatively.
DI-Fusion: Online Implicit 3D Reconstruction with Deep Priors
Dec 10, 2020
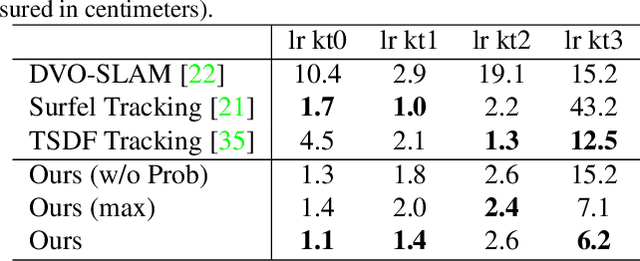
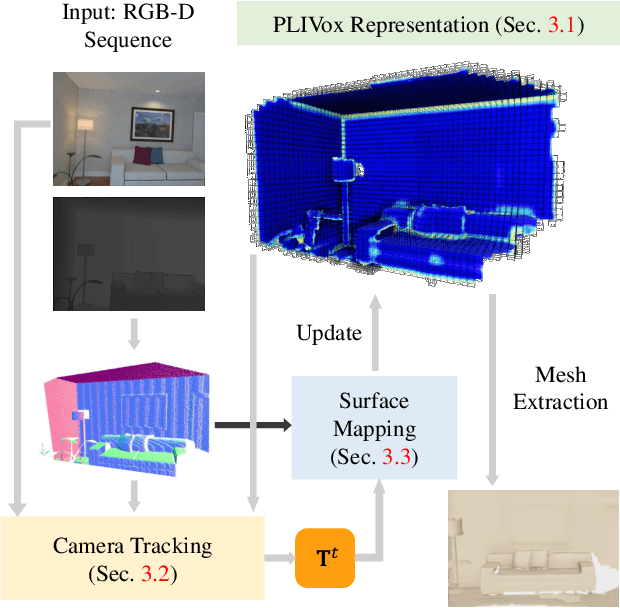
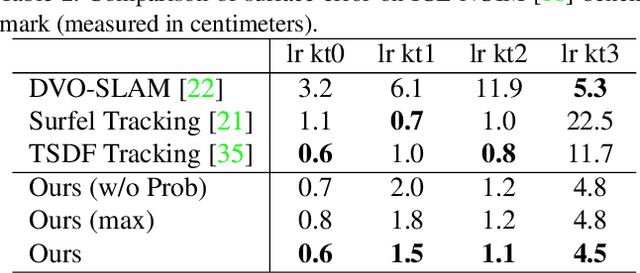
Previous online 3D dense reconstruction methods often cost massive memory storage while achieving unsatisfactory surface quality mainly due to the usage of stagnant underlying geometry representation, such as TSDF (truncated signed distance functions) or surfels, without any knowledge of the scene priors. In this paper, we present DI-Fusion (Deep Implicit Fusion), based on a novel 3D representation, called Probabilistic Local Implicit Voxels (PLIVoxs), for online 3D reconstruction using a commodity RGB-D camera. Our PLIVox encodes scene priors considering both the local geometry and uncertainty parameterized by a deep neural network. With such deep priors, we demonstrate by extensive experiments that we are able to perform online implicit 3D reconstruction achieving state-of-the-art mapping quality and camera trajectory estimation accuracy, while taking much less storage compared with previous online 3D reconstruction approaches.