 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCRayDiffusion: Pose-Free Surface Reconstruction via Geometric Consistent Ray Diffusion
Mar 28, 2025Accurate surface reconstruction from unposed images is crucial for efficient 3D object or scene creation. However, it remains challenging, particularly for the joint camera pose estimation. Previous approaches have achieved impressive pose-free surface reconstruction results in dense-view settings, but could easily fail for sparse-view scenarios without sufficient visual overlap. In this paper, we propose a new technique for pose-free surface reconstruction, which follows triplane-based signed distance field (SDF) learning but regularizes the learning by explicit points sampled from ray-based diffusion of camera pose estimation. Our key contribution is a novel Geometric Consistent Ray Diffusion model (GCRayDiffusion), where we represent camera poses as neural bundle rays and regress the distribution of noisy rays via a diffusion model. More importantly, we further condition the denoising process of RGRayDiffusion using the triplane-based SDF of the entire scene, which provides effective 3D consistent regularization to achieve multi-view consistent camera pose estimation. Finally, we incorporate RGRayDiffusion into the triplane-based SDF learning by introducing on-surface geometric regularization from the sampling points of the neural bundle rays, which leads to highly accurate pose-free surface reconstruction results even for sparse-view inputs. Extensive evaluations on public datasets show that our GCRayDiffusion achieves more accurate camera pose estimation than previous approaches, with geometrically more consistent surface reconstruction results, especially given sparse-view inputs.
Estimating the Resize Parameter in End-to-end Learned Image Compression
Apr 26, 2022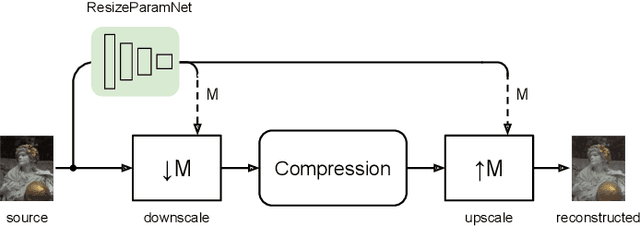
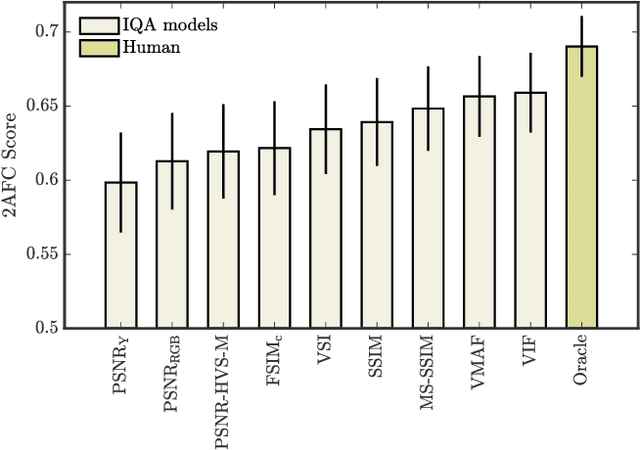
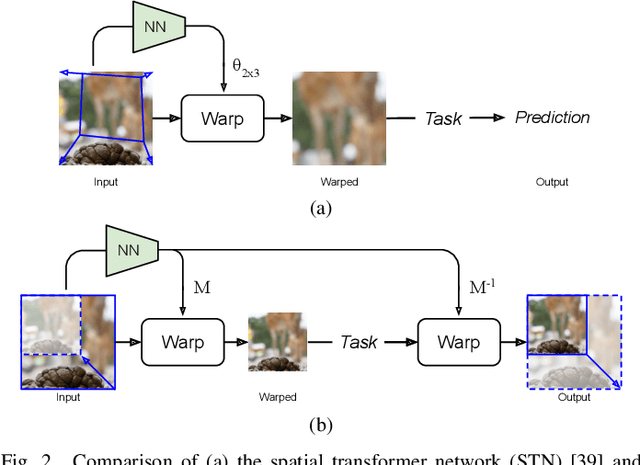
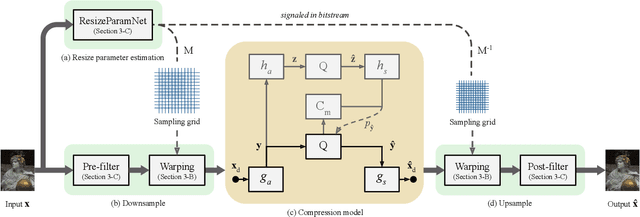
We describe a search-free resizing framework that can further improve the rate-distortion tradeoff of recent learned image compression models. Our approach is simple: compose a pair of differentiable downsampling/upsampling layers that sandwich a neural compression model. To determine resize factors for different inputs, we utilize another neural network jointly trained with the compression model, with the end goal of minimizing the rate-distortion objective. Our results suggest that "compression friendly" downsampled representations can be quickly determined during encoding by using an auxiliary network and differentiable image warping. By conducting extensive experimental tests on existing deep image compression models, we show results that our new resizing parameter estimation framework can provide Bj{\o}ntegaard-Delta rate (BD-rate) improvement of about 10% against leading perceptual quality engines. We also carried out a subjective quality study, the results of which show that our new approach yields favorable compressed images. To facilitate reproducible research in this direction, the implementation used in this paper is being made freely available online at: https://github.com/treammm/ResizeCompression.
Convolutional Block Design for Learned Fractional Downsampling
May 20, 2021
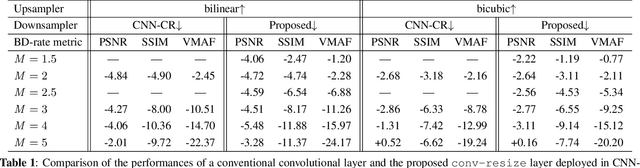
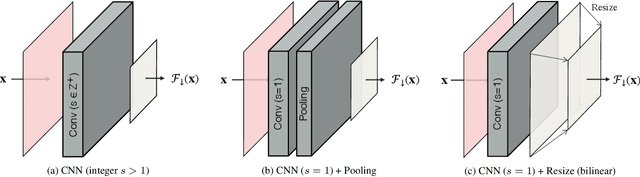
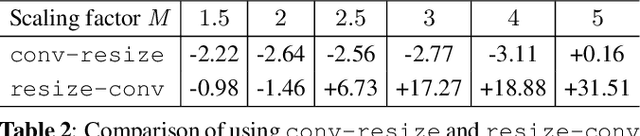
The layers of convolutional neural networks (CNNs) can be used to alter the resolution of their inputs, but the scaling factors are limited to integer values. However, in many image and video processing applications, the ability to resize by a fractional factor would be advantageous. One example is conversion between resolutions standardized for video compression, such as from 1080p to 720p. To solve this problem, we propose an alternative building block, formulated as a conventional convolutional layer followed by a differentiable resizer. More concretely, the convolutional layer preserves the resolution of the input, while the resizing operation is fully handled by the resizer. In this way, any CNN architecture can be adapted for non-integer resizing. As an application, we replace the resizing convolutional layer of a modern deep downsampling model by the proposed building block, and apply it to an adaptive bitrate video streaming scenario. Our experimental results show that an improvement in coding efficiency over the conventional Lanczos algorithm is attained, in terms of PSNR, SSIM, and VMAF on test videos.
Regression or Classification? New Methods to Evaluate No-Reference Picture and Video Quality Models
Jan 30, 2021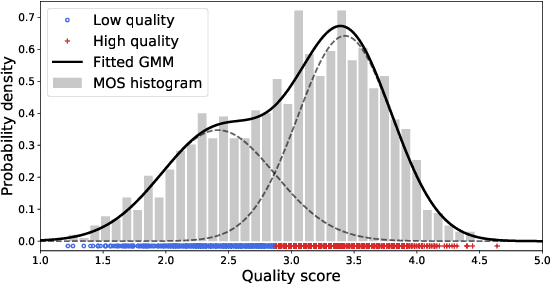
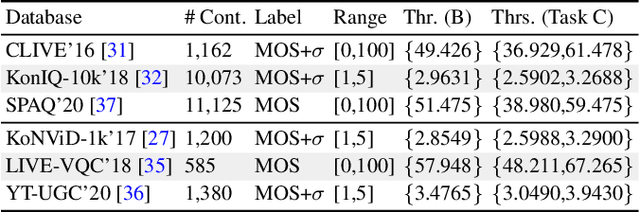
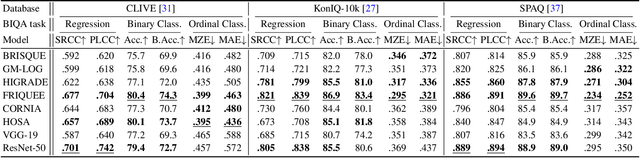
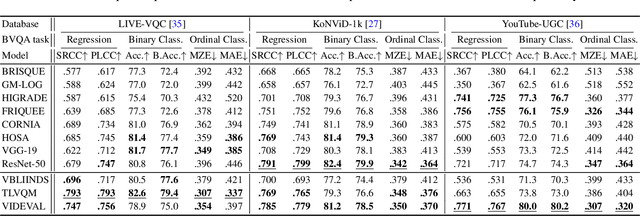
Video and image quality assessment has long been projected as a regression problem, which requires predicting a continuous quality score given an input stimulus. However, recent efforts have shown that accurate quality score regression on real-world user-generated content (UGC) is a very challenging task. To make the problem more tractable, we propose two new methods - binary, and ordinal classification - as alternatives to evaluate and compare no-reference quality models at coarser levels. Moreover, the proposed new tasks convey more practical meaning on perceptually optimized UGC transcoding, or for preprocessing on media processing platforms. We conduct a comprehensive benchmark experiment of popular no-reference quality models on recent in-the-wild picture and video quality datasets, providing reliable baselines for both evaluation methods to support further studies. We hope this work promotes coarse-grained perceptual modeling and its applications to efficient UGC processing.
Perceptually Optimizing Deep Image Compression
Jul 09, 2020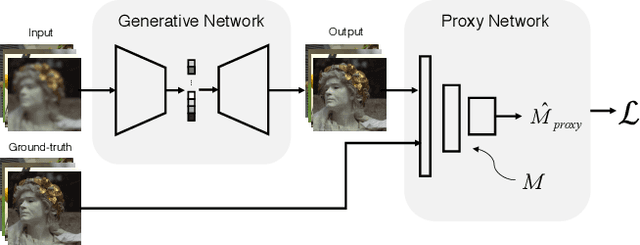
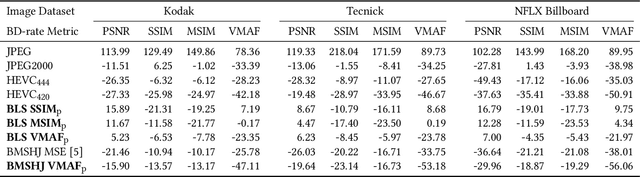

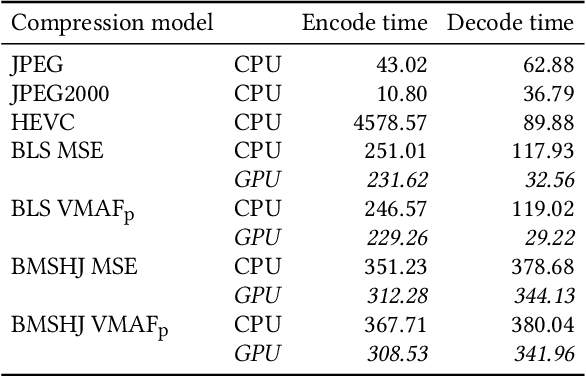
Mean squared error (MSE) and $\ell_p$ norms have largely dominated the measurement of loss in neural networks due to their simplicity and analytical properties. However, when used to assess visual information loss, these simple norms are not highly consistent with human perception. Here, we propose a different proxy approach to optimize image analysis networks against quantitative perceptual models. Specifically, we construct a proxy network, which mimics the perceptual model while serving as a loss layer of the network.We experimentally demonstrate how this optimization framework can be applied to train an end-to-end optimized image compression network. By building on top of a modern deep image compression models, we are able to demonstrate an averaged bitrate reduction of $28.7\%$ over MSE optimization, given a specified perceptual quality (VMAF) level.
A Comparative Evaluation of Temporal Pooling Methods for Blind Video Quality Assessment
Feb 25, 2020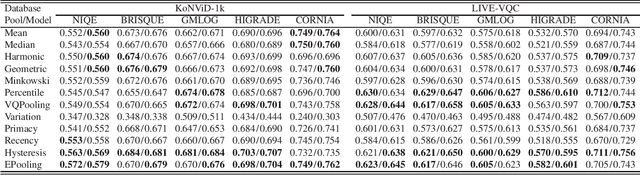
Many objective video quality assessment (VQA) algorithms include a key step of temporal pooling of frame-level quality scores. However, less attention has been paid to studying the relative efficiencies of different pooling methods on no-reference (blind) VQA. Here we conduct a large-scale comparative evaluation to assess the capabilities and limitations of multiple temporal pooling strategies on blind VQA of user-generated videos. The study yields insights and general guidance regarding the application and selection of temporal pooling models. In addition, we also propose an ensemble pooling model built on top of high-performing temporal pooling models. Our experimental results demonstrate the relative efficacies of the evaluated temporal pooling models, using several popular VQA algorithms, and evaluated on two recent large-scale natural video quality databases. In addition to the new ensemble model, we provide a general recipe for applying temporal pooling of frame-based quality predictions.
ProxIQA: A Proxy Approach to Perceptual Optimization of Learned Image Compression
Oct 19, 2019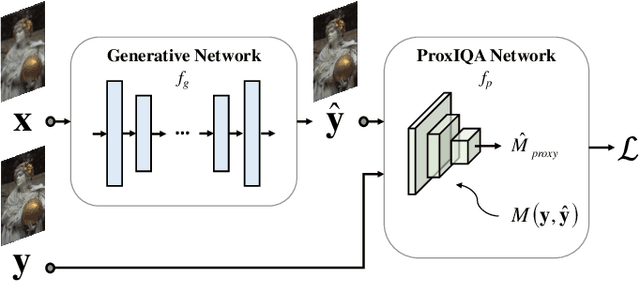

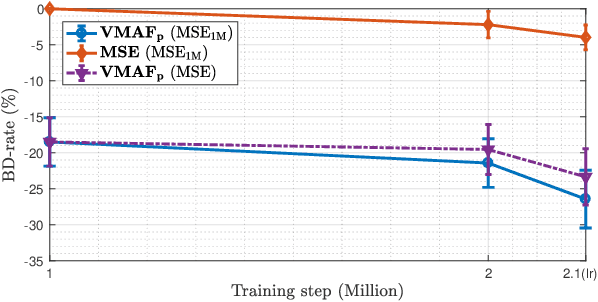
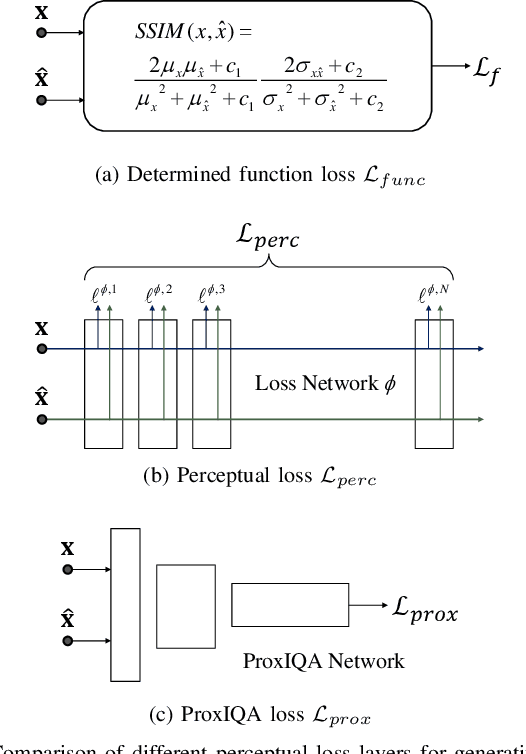
The use of $\ell_p$ $(p=1,2)$ norms has largely dominated the measurement of loss in neural networks due to their simplicity and analytical properties. However, when used to assess the loss of visual information, these simple norms are not very consistent with human perception. Here, we describe a different "proximal" approach to optimize image analysis networks against quantitative perceptual models. Specifically, we construct a proxy network, broadly termed ProxIQA, which mimics the perceptual model while serving as a loss layer of the network. We experimentally demonstrate how this optimization framework can be applied to train an end-to-end optimized image compression network. By building on top of an existing deep image compression model, we are able to demonstrate a bitrate reduction of as much as $31\%$ over MSE optimization, given a specified perceptual quality (VMAF) level.
Facial Emotion Recognition Using Deep Learning
Oct 19, 2019



We aim to construct a system that captures real-world facial images through the front camera on a laptop. The system is capable of processing/recognizing the captured image and predict a result in real-time. In this system, we exploit the power of deep learning technique to learn a facial emotion recognition (FER) model based on a set of labeled facial images. Finally, experiments are conducted to evaluate our model using largely used public database.