 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo image and video quality metrics model low-level human vision?
Mar 20, 2025Image and video quality metrics, such as SSIM, LPIPS, and VMAF, are aimed to predict the perceived quality of the evaluated content and are often claimed to be "perceptual". Yet, few metrics directly model human visual perception, and most rely on hand-crafted formulas or training datasets to achieve alignment with perceptual data. In this paper, we propose a set of tests for full-reference quality metrics that examine their ability to model several aspects of low-level human vision: contrast sensitivity, contrast masking, and contrast matching. The tests are meant to provide additional scrutiny for newly proposed metrics. We use our tests to analyze 33 existing image and video quality metrics and find their strengths and weaknesses, such as the ability of LPIPS and MS-SSIM to predict contrast masking and poor performance of VMAF in this task. We further find that the popular SSIM metric overemphasizes differences in high spatial frequencies, but its multi-scale counterpart, MS-SSIM, addresses this shortcoming. Such findings cannot be easily made using existing evaluation protocols.
Estimating the Resize Parameter in End-to-end Learned Image Compression
Apr 26, 2022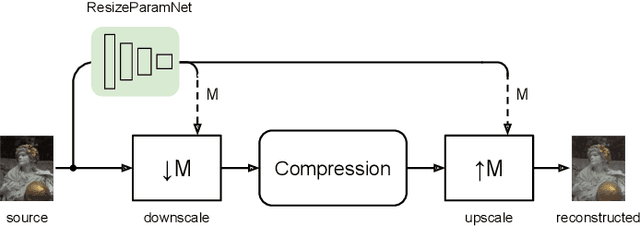
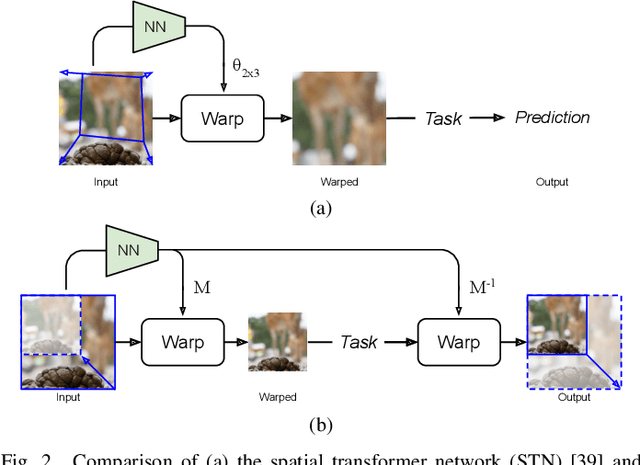
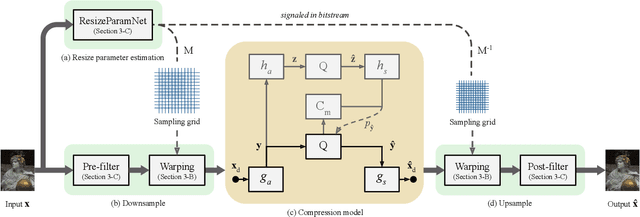
We describe a search-free resizing framework that can further improve the rate-distortion tradeoff of recent learned image compression models. Our approach is simple: compose a pair of differentiable downsampling/upsampling layers that sandwich a neural compression model. To determine resize factors for different inputs, we utilize another neural network jointly trained with the compression model, with the end goal of minimizing the rate-distortion objective. Our results suggest that "compression friendly" downsampled representations can be quickly determined during encoding by using an auxiliary network and differentiable image warping. By conducting extensive experimental tests on existing deep image compression models, we show results that our new resizing parameter estimation framework can provide Bj{\o}ntegaard-Delta rate (BD-rate) improvement of about 10% against leading perceptual quality engines. We also carried out a subjective quality study, the results of which show that our new approach yields favorable compressed images. To facilitate reproducible research in this direction, the implementation used in this paper is being made freely available online at: https://github.com/treammm/ResizeCompression.
Banding vs. Quality: Perceptual Impact and Objective Assessment
Feb 22, 2022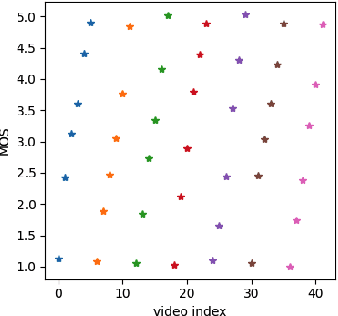
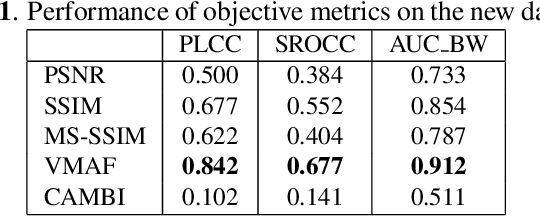
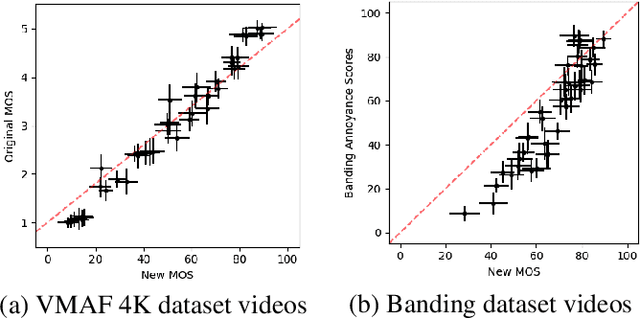
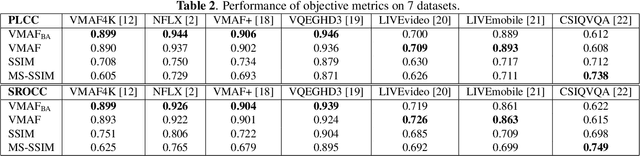
Staircase-like contours introduced to a video by quantization in flat areas, commonly known as banding, have been a long-standing problem in both video processing and quality assessment communities. The fact that even a relatively small change of the original pixel values can result in a strong impact on perceived quality makes banding especially difficult to be detected by objective quality metrics. In this paper, we study how banding annoyance compares to more commonly studied scaling and compression artifacts with respect to the overall perceptual quality. We further propose a simple combination of VMAF and the recently developed banding index, CAMBI, into a banding-aware video quality metric showing improved correlation with overall perceived quality.
Convolutional Block Design for Learned Fractional Downsampling
May 20, 2021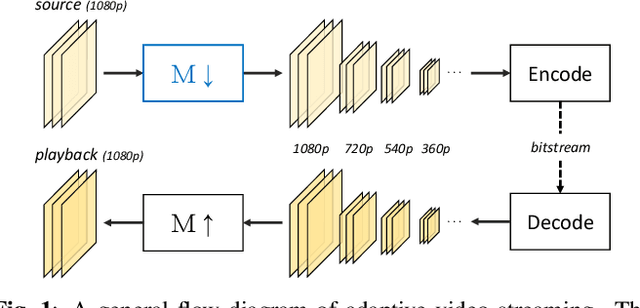
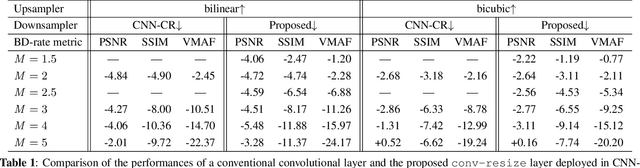
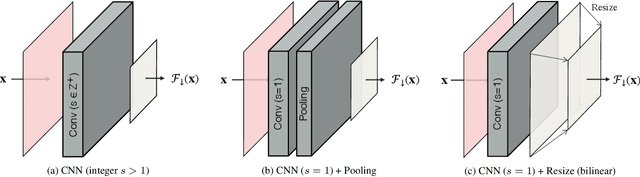
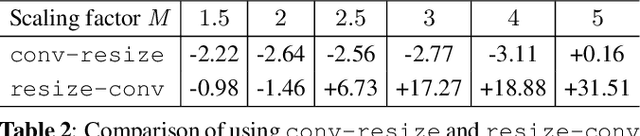
The layers of convolutional neural networks (CNNs) can be used to alter the resolution of their inputs, but the scaling factors are limited to integer values. However, in many image and video processing applications, the ability to resize by a fractional factor would be advantageous. One example is conversion between resolutions standardized for video compression, such as from 1080p to 720p. To solve this problem, we propose an alternative building block, formulated as a conventional convolutional layer followed by a differentiable resizer. More concretely, the convolutional layer preserves the resolution of the input, while the resizing operation is fully handled by the resizer. In this way, any CNN architecture can be adapted for non-integer resizing. As an application, we replace the resizing convolutional layer of a modern deep downsampling model by the proposed building block, and apply it to an adaptive bitrate video streaming scenario. Our experimental results show that an improvement in coding efficiency over the conventional Lanczos algorithm is attained, in terms of PSNR, SSIM, and VMAF on test videos.
A Subjective and Objective Study of Space-Time Subsampled Video Quality
Jan 29, 2021
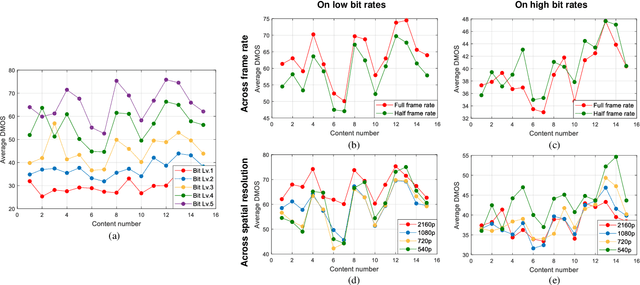
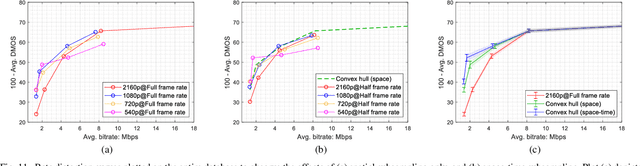
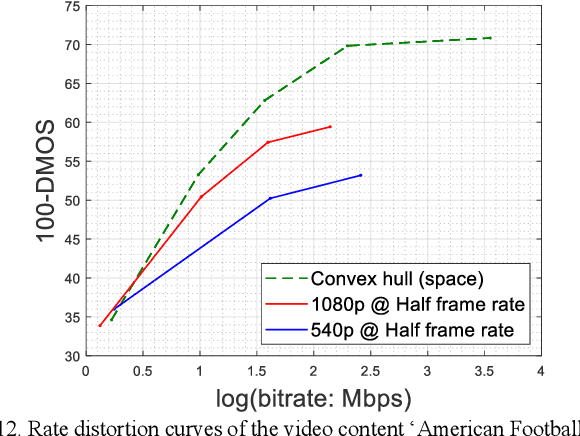
Video dimensions are continuously increasing to provide more realistic and immersive experiences to global streaming and social media viewers. However, increments in video parameters such as spatial resolution and frame rate are inevitably associated with larger data volumes. Transmitting increasingly voluminous videos through limited bandwidth networks in a perceptually optimal way is a current challenge affecting billions of viewers. One recent practice adopted by video service providers is space-time resolution adaptation in conjunction with video compression. Consequently, it is important to understand how different levels of space-time subsampling and compression affect the perceptual quality of videos. Towards making progress in this direction, we constructed a large new resource, called the ETRI-LIVE Space-Time Subsampled Video Quality (ETRI-LIVE STSVQ) database, containing 437 videos generated by applying various levels of combined space-time subsampling and video compression on 15 diverse video contents. We also conducted a large-scale human study on the new dataset, collecting about 15,000 subjective judgments of video quality. We provide a rate-distortion analysis of the collected subjective scores, enabling us to investigate the perceptual impact of space-time subsampling at different bit rates. We also evaluated and compared the performance of leading video quality models on the new database.
Perceptually Optimizing Deep Image Compression
Jul 09, 2020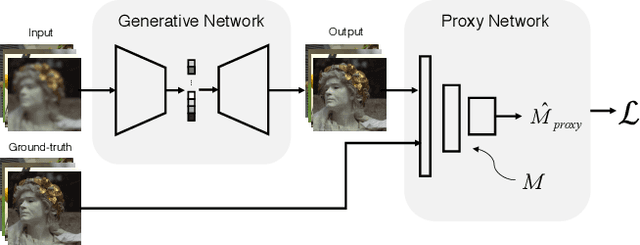
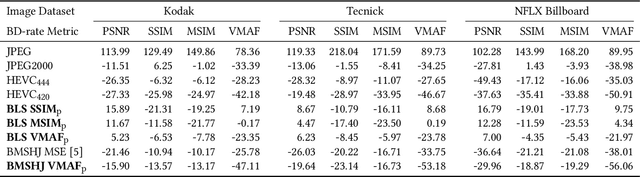

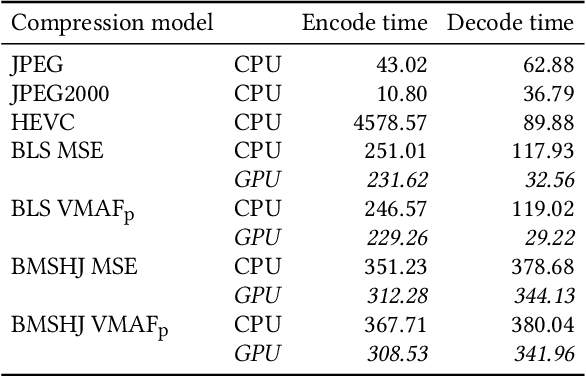
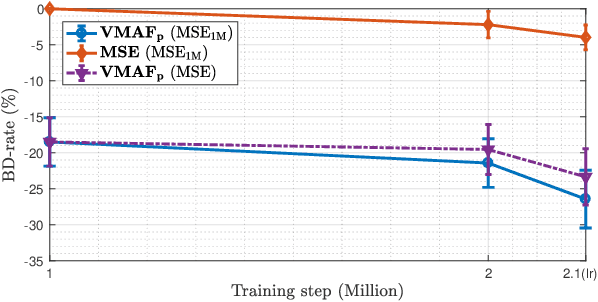
Mean squared error (MSE) and $\ell_p$ norms have largely dominated the measurement of loss in neural networks due to their simplicity and analytical properties. However, when used to assess visual information loss, these simple norms are not highly consistent with human perception. Here, we propose a different proxy approach to optimize image analysis networks against quantitative perceptual models. Specifically, we construct a proxy network, which mimics the perceptual model while serving as a loss layer of the network.We experimentally demonstrate how this optimization framework can be applied to train an end-to-end optimized image compression network. By building on top of a modern deep image compression models, we are able to demonstrate an averaged bitrate reduction of $28.7\%$ over MSE optimization, given a specified perceptual quality (VMAF) level.
ProxIQA: A Proxy Approach to Perceptual Optimization of Learned Image Compression
Oct 19, 2019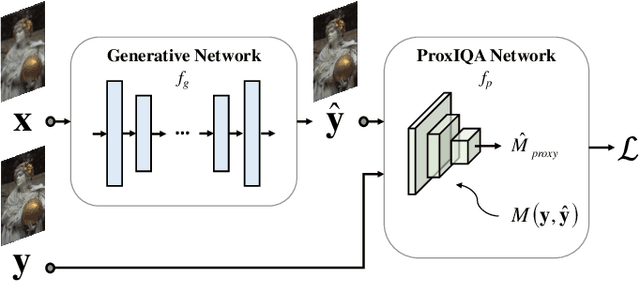

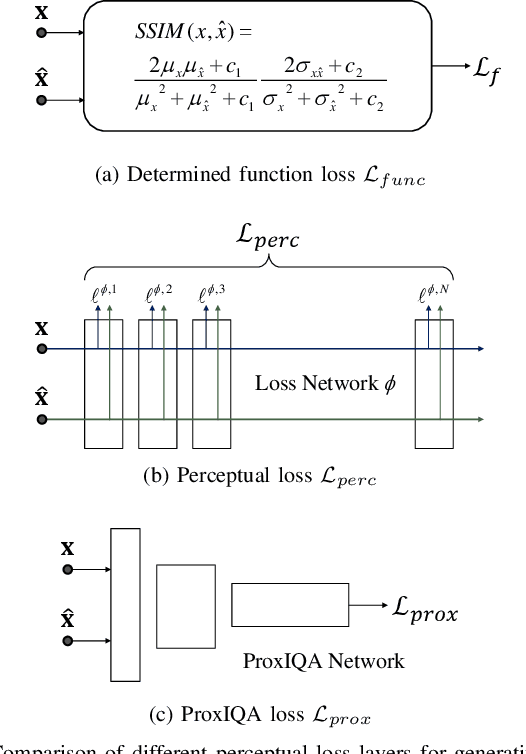
The use of $\ell_p$ $(p=1,2)$ norms has largely dominated the measurement of loss in neural networks due to their simplicity and analytical properties. However, when used to assess the loss of visual information, these simple norms are not very consistent with human perception. Here, we describe a different "proximal" approach to optimize image analysis networks against quantitative perceptual models. Specifically, we construct a proxy network, broadly termed ProxIQA, which mimics the perceptual model while serving as a loss layer of the network. We experimentally demonstrate how this optimization framework can be applied to train an end-to-end optimized image compression network. By building on top of an existing deep image compression model, we are able to demonstrate a bitrate reduction of as much as $31\%$ over MSE optimization, given a specified perceptual quality (VMAF) level.
Adversarial Video Compression Guided by Soft Edge Detection
Nov 26, 2018
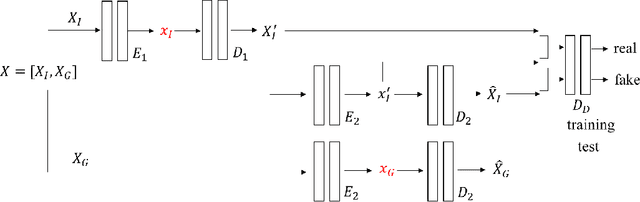
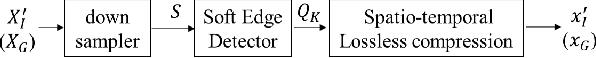
We propose a video compression framework using conditional Generative Adversarial Networks (GANs). We rely on two encoders: one that deploys a standard video codec and another which generates low-level maps via a pipeline of down-sampling, a newly devised soft edge detector, and a novel lossless compression scheme. For decoding, we use a standard video decoder as well as a neural network based one, which is trained using a conditional GAN. Recent "deep" approaches to video compression require multiple videos to pre-train generative networks to conduct interpolation. In contrast to this prior work, our scheme trains a generative decoder on pairs of a very limited number of key frames taken from a single video and corresponding low-level maps. The trained decoder produces reconstructed frames relying on a guidance of low-level maps, without any interpolation. Experiments on a diverse set of 131 videos demonstrate that our proposed GAN-based compression engine achieves much higher quality reconstructions at very low bitrates than prevailing standard codecs such as H.264 or HEVC.