 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit neural representation of textures
Feb 02, 2026Implicit neural representation (INR) has proven to be accurate and efficient in various domains. In this work, we explore how different neural networks can be designed as a new texture INR, which operates in a continuous manner rather than a discrete one over the input UV coordinate space. Through thorough experiments, we demonstrate that these INRs perform well in terms of image quality, with considerable memory usage and rendering inference time. We analyze the balance between these objectives. In addition, we investigate various related applications in real-time rendering and down-stream tasks, e.g. mipmap fitting and INR-space generation.
Do image and video quality metrics model low-level human vision?
Mar 20, 2025Image and video quality metrics, such as SSIM, LPIPS, and VMAF, are aimed to predict the perceived quality of the evaluated content and are often claimed to be "perceptual". Yet, few metrics directly model human visual perception, and most rely on hand-crafted formulas or training datasets to achieve alignment with perceptual data. In this paper, we propose a set of tests for full-reference quality metrics that examine their ability to model several aspects of low-level human vision: contrast sensitivity, contrast masking, and contrast matching. The tests are meant to provide additional scrutiny for newly proposed metrics. We use our tests to analyze 33 existing image and video quality metrics and find their strengths and weaknesses, such as the ability of LPIPS and MS-SSIM to predict contrast masking and poor performance of VMAF in this task. We further find that the popular SSIM metric overemphasizes differences in high spatial frequencies, but its multi-scale counterpart, MS-SSIM, addresses this shortcoming. Such findings cannot be easily made using existing evaluation protocols.
Do computer vision foundation models learn the low-level characteristics of the human visual system?
Feb 27, 2025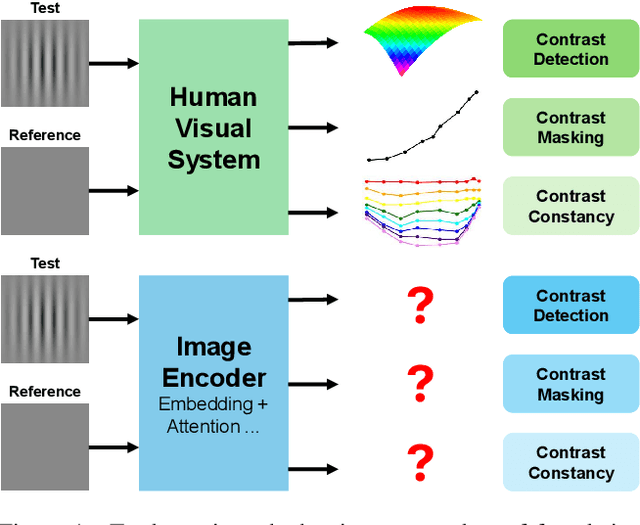
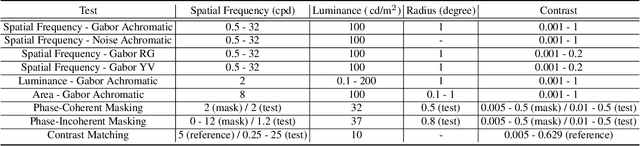
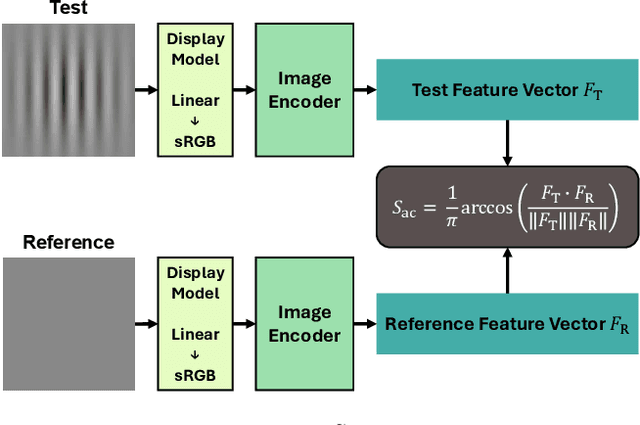
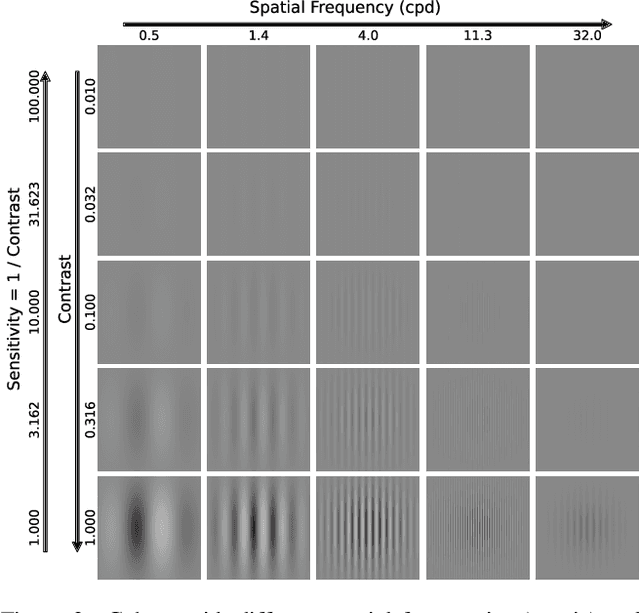
Computer vision foundation models, such as DINO or OpenCLIP, are trained in a self-supervised manner on large image datasets. Analogously, substantial evidence suggests that the human visual system (HVS) is influenced by the statistical distribution of colors and patterns in the natural world, characteristics also present in the training data of foundation models. The question we address in this paper is whether foundation models trained on natural images mimic some of the low-level characteristics of the human visual system, such as contrast detection, contrast masking, and contrast constancy. Specifically, we designed a protocol comprising nine test types to evaluate the image encoders of 45 foundation and generative models. Our results indicate that some foundation models (e.g., DINO, DINOv2, and OpenCLIP), share some of the characteristics of human vision, but other models show little resemblance. Foundation models tend to show smaller sensitivity to low contrast and rather irregular responses to contrast across frequencies. The foundation models show the best agreement with human data in terms of contrast masking. Our findings suggest that human vision and computer vision may take both similar and different paths when learning to interpret images of the real world. Overall, while differences remain, foundation models trained on vision tasks start to align with low-level human vision, with DINOv2 showing the closest resemblance.
HDR-VDP-3: A multi-metric for predicting image differences, quality and contrast distortions in high dynamic range and regular content
Apr 26, 2023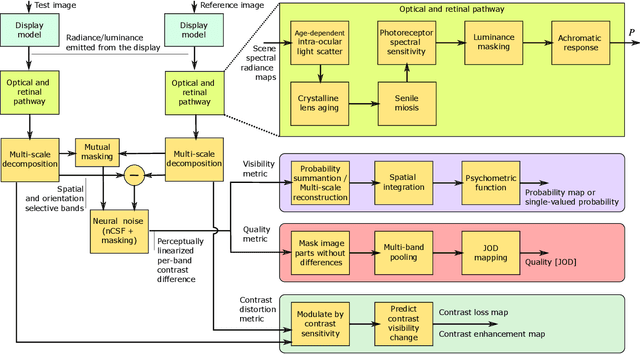
High-Dynamic-Range Visual-Difference-Predictor version 3, or HDR-VDP-3, is a visual metric that can fulfill several tasks, such as full-reference image/video quality assessment, prediction of visual differences between a pair of images, or prediction of contrast distortions. Here we present a high-level overview of the metric, position it with respect to related work, explain the main differences compared to version 2.2, and describe how the metric was adapted for the HDR Video Quality Measurement Grand Challenge 2023.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021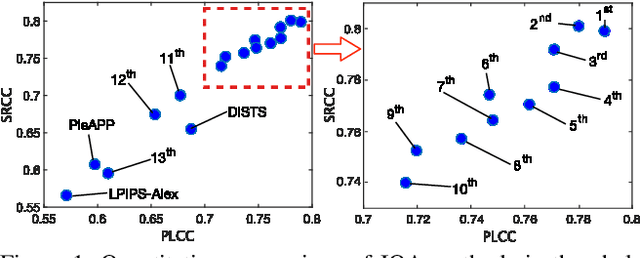
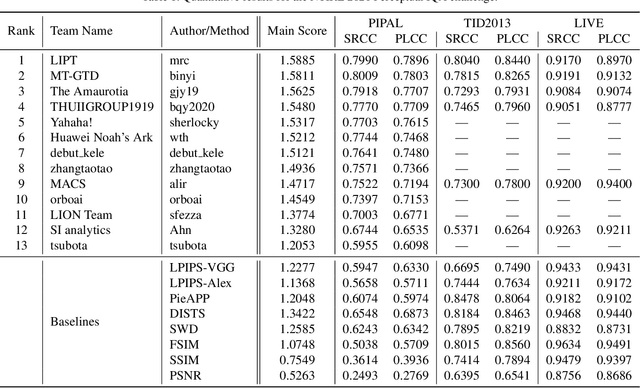

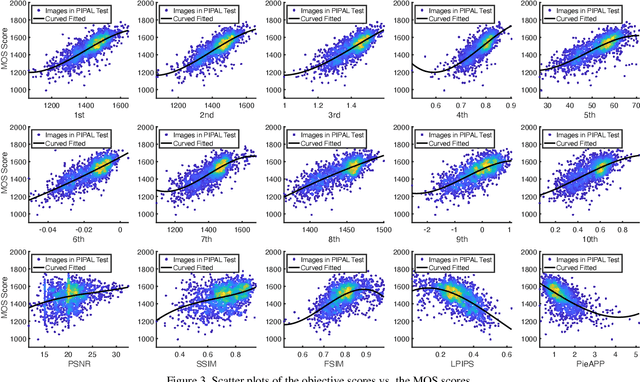
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.