 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMPBench: A Paired Multi-Modal Pan-Cancer Benchmark for Medical Image Synthesis
Jan 22, 2026Contrast medium plays a pivotal role in radiological imaging, as it amplifies lesion conspicuity and improves detection for the diagnosis of tumor-related diseases. However, depending on the patient's health condition or the medical resources available, the use of contrast medium is not always feasible. Recent work has explored AI-based image translation to synthesize contrast-enhanced images directly from non-contrast scans, aims to reduce side effects and streamlines clinical workflows. Progress in this direction has been constrained by data limitations: (1) existing public datasets focus almost exclusively on brain-related paired MR modalities; (2) other collections include partially paired data but suffer from missing modalities/timestamps and imperfect spatial alignment; (3) explicit labeling of CT vs. CTC or DCE phases is often absent; (4) substantial resources remain private. To bridge this gap, we introduce the first public, fully paired, pan-cancer medical imaging dataset spanning 11 human organs. The MR data include complete dynamic contrast-enhanced (DCE) sequences covering all three phases (DCE1-DCE3), while the CT data provide paired non-contrast and contrast-enhanced acquisitions (CTC). The dataset is curated for anatomical correspondence, enabling rigorous evaluation of 1-to-1, N-to-1, and N-to-N translation settings (e.g., predicting DCE phases from non-contrast inputs). Built upon this resource, we establish a comprehensive benchmark. We report results from representative baselines of contemporary image-to-image translation. We release the dataset and benchmark to catalyze research on safe, effective contrast synthesis, with direct relevance to multi-organ oncology imaging workflows. Our code and dataset are publicly available at https://github.com/YifanChen02/PMPBench.
Online Handwritten Signature Verification Based on Temporal-Spatial Graph Attention Transformer
Oct 22, 2025Handwritten signature verification is a crucial aspect of identity authentication, with applications in various domains such as finance and e-commerce. However, achieving high accuracy in signature verification remains challenging due to intra-user variability and the risk of forgery. This paper introduces a novel approach for dynamic signature verification: the Temporal-Spatial Graph Attention Transformer (TS-GATR). TS-GATR combines the Graph Attention Network (GAT) and the Gated Recurrent Unit (GRU) to model both spatial and temporal dependencies in signature data. TS-GATR enhances verification performance by representing signatures as graphs, where each node captures dynamic features (e.g. position, velocity, pressure), and by using attention mechanisms to model their complex relationships. The proposed method further employs a Dual-Graph Attention Transformer (DGATR) module, which utilizes k-step and k-nearest neighbor adjacency graphs to model local and global spatial features, respectively. To capture long-term temporal dependencies, the model integrates GRU, thereby enhancing its ability to learn dynamic features during signature verification. Comprehensive experiments conducted on benchmark datasets such as MSDS and DeepSignDB show that TS-GATR surpasses current state-of-the-art approaches, consistently achieving lower Equal Error Rates (EER) across various scenarios.
FaceCraft4D: Animated 3D Facial Avatar Generation from a Single Image
Apr 21, 2025We present a novel framework for generating high-quality, animatable 4D avatar from a single image. While recent advances have shown promising results in 4D avatar creation, existing methods either require extensive multiview data or struggle with shape accuracy and identity consistency. To address these limitations, we propose a comprehensive system that leverages shape, image, and video priors to create full-view, animatable avatars. Our approach first obtains initial coarse shape through 3D-GAN inversion. Then, it enhances multiview textures using depth-guided warping signals for cross-view consistency with the help of the image diffusion model. To handle expression animation, we incorporate a video prior with synchronized driving signals across viewpoints. We further introduce a Consistent-Inconsistent training to effectively handle data inconsistencies during 4D reconstruction. Experimental results demonstrate that our method achieves superior quality compared to the prior art, while maintaining consistency across different viewpoints and expressions.
DocSAM: Unified Document Image Segmentation via Query Decomposition and Heterogeneous Mixed Learning
Apr 05, 2025Document image segmentation is crucial for document analysis and recognition but remains challenging due to the diversity of document formats and segmentation tasks. Existing methods often address these tasks separately, resulting in limited generalization and resource wastage. This paper introduces DocSAM, a transformer-based unified framework designed for various document image segmentation tasks, such as document layout analysis, multi-granularity text segmentation, and table structure recognition, by modelling these tasks as a combination of instance and semantic segmentation. Specifically, DocSAM employs Sentence-BERT to map category names from each dataset into semantic queries that match the dimensionality of instance queries. These two sets of queries interact through an attention mechanism and are cross-attended with image features to predict instance and semantic segmentation masks. Instance categories are predicted by computing the dot product between instance and semantic queries, followed by softmax normalization of scores. Consequently, DocSAM can be jointly trained on heterogeneous datasets, enhancing robustness and generalization while reducing computational and storage resources. Comprehensive evaluations show that DocSAM surpasses existing methods in accuracy, efficiency, and adaptability, highlighting its potential for advancing document image understanding and segmentation across various applications. Codes are available at https://github.com/xhli-git/DocSAM.
MV-MATH: Evaluating Multimodal Math Reasoning in Multi-Visual Contexts
Feb 28, 2025



Multimodal Large Language Models (MLLMs) have shown promising capabilities in mathematical reasoning within visual contexts across various datasets. However, most existing multimodal math benchmarks are limited to single-visual contexts, which diverges from the multi-visual scenarios commonly encountered in real-world mathematical applications. To address this gap, we introduce MV-MATH: a meticulously curated dataset of 2,009 high-quality mathematical problems. Each problem integrates multiple images interleaved with text, derived from authentic K-12 scenarios, and enriched with detailed annotations. MV-MATH includes multiple-choice, free-form, and multi-step questions, covering 11 subject areas across 3 difficulty levels, and serves as a comprehensive and rigorous benchmark for assessing MLLMs' mathematical reasoning in multi-visual contexts. Through extensive experimentation, we observe that MLLMs encounter substantial challenges in multi-visual math tasks, with a considerable performance gap relative to human capabilities on MV-MATH. Furthermore, we analyze the performance and error patterns of various models, providing insights into MLLMs' mathematical reasoning capabilities within multi-visual settings.
Do computer vision foundation models learn the low-level characteristics of the human visual system?
Feb 27, 2025
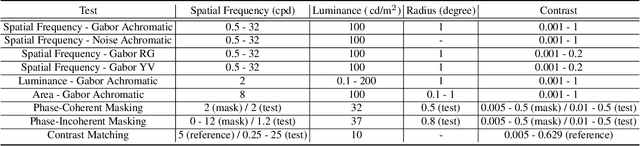
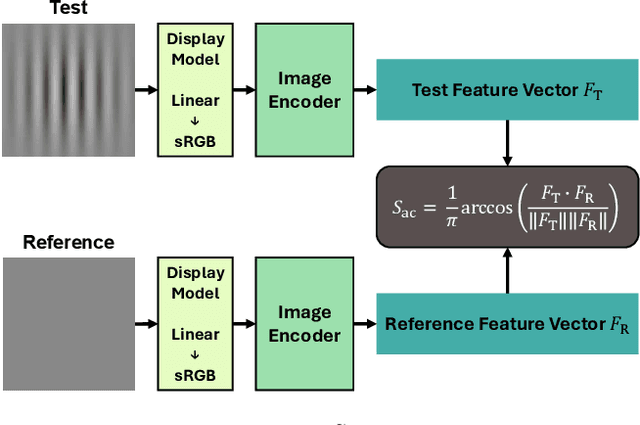
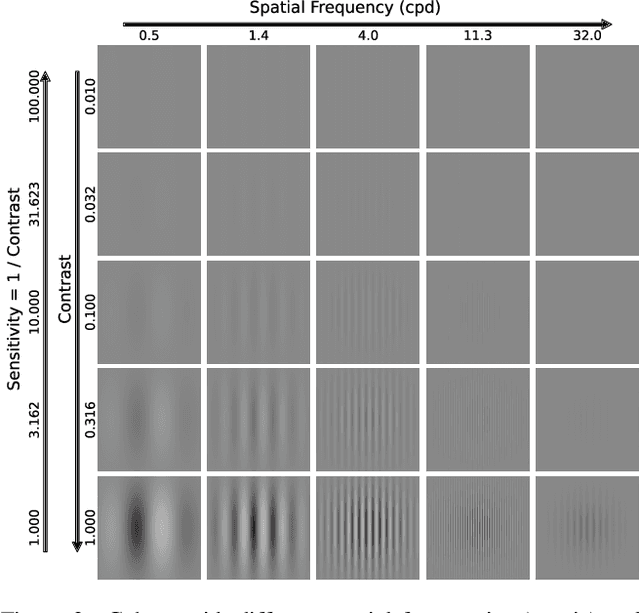
Computer vision foundation models, such as DINO or OpenCLIP, are trained in a self-supervised manner on large image datasets. Analogously, substantial evidence suggests that the human visual system (HVS) is influenced by the statistical distribution of colors and patterns in the natural world, characteristics also present in the training data of foundation models. The question we address in this paper is whether foundation models trained on natural images mimic some of the low-level characteristics of the human visual system, such as contrast detection, contrast masking, and contrast constancy. Specifically, we designed a protocol comprising nine test types to evaluate the image encoders of 45 foundation and generative models. Our results indicate that some foundation models (e.g., DINO, DINOv2, and OpenCLIP), share some of the characteristics of human vision, but other models show little resemblance. Foundation models tend to show smaller sensitivity to low contrast and rather irregular responses to contrast across frequencies. The foundation models show the best agreement with human data in terms of contrast masking. Our findings suggest that human vision and computer vision may take both similar and different paths when learning to interpret images of the real world. Overall, while differences remain, foundation models trained on vision tasks start to align with low-level human vision, with DINOv2 showing the closest resemblance.
From System 1 to System 2: A Survey of Reasoning Large Language Models
Feb 25, 2025Achieving human-level intelligence requires refining the transition from the fast, intuitive System 1 to the slower, more deliberate System 2 reasoning. While System 1 excels in quick, heuristic decisions, System 2 relies on logical reasoning for more accurate judgments and reduced biases. Foundational Large Language Models (LLMs) excel at fast decision-making but lack the depth for complex reasoning, as they have not yet fully embraced the step-by-step analysis characteristic of true System 2 thinking. Recently, reasoning LLMs like OpenAI's o1/o3 and DeepSeek's R1 have demonstrated expert-level performance in fields such as mathematics and coding, closely mimicking the deliberate reasoning of System 2 and showcasing human-like cognitive abilities. This survey begins with a brief overview of the progress in foundational LLMs and the early development of System 2 technologies, exploring how their combination has paved the way for reasoning LLMs. Next, we discuss how to construct reasoning LLMs, analyzing their features, the core methods enabling advanced reasoning, and the evolution of various reasoning LLMs. Additionally, we provide an overview of reasoning benchmarks, offering an in-depth comparison of the performance of representative reasoning LLMs. Finally, we explore promising directions for advancing reasoning LLMs and maintain a real-time \href{https://github.com/zzli2022/Awesome-Slow-Reason-System}{GitHub Repository} to track the latest developments. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this rapidly evolving field.
Fuse, Reason and Verify: Geometry Problem Solving with Parsed Clauses from Diagram
Jul 10, 2024Geometry problem solving (GPS) requires capacities of multi-modal understanding, multi-hop reasoning and theorem knowledge application. In this paper, we propose a neural-symbolic model for plane geometry problem solving (PGPS), named PGPSNet-v2, with three key steps: modal fusion, reasoning process and knowledge verification. In modal fusion, we leverage textual clauses to express fine-grained structural and semantic content of geometry diagram, and fuse diagram with textual problem efficiently through structural-semantic pre-training. For reasoning, we design an explicable solution program to describe the geometric reasoning process, and employ a self-limited decoder to generate solution program autoregressively. To reduce solution errors, a multi-level theorem verifier is proposed to eliminate solutions that do not match geometric principles, alleviating the hallucination of the neural model. We also construct a large-scale geometry problem dataset called PGPS9K, containing fine-grained annotations of textual clauses, solution program and involved knowledge tuples. Extensive experiments on datasets Geometry3K and PGPS9K show that our PGPSNet solver outperforms existing symbolic and neural solvers in GPS performance, while maintaining good explainability and reliability, and the solver components (fusion, reasoning, verification) are all justified effective.
Ensemble Quadratic Assignment Network for Graph Matching
Mar 11, 2024Graph matching is a commonly used technique in computer vision and pattern recognition. Recent data-driven approaches have improved the graph matching accuracy remarkably, whereas some traditional algorithm-based methods are more robust to feature noises, outlier nodes, and global transformation (e.g.~rotation). In this paper, we propose a graph neural network (GNN) based approach to combine the advantages of data-driven and traditional methods. In the GNN framework, we transform traditional graph-matching solvers as single-channel GNNs on the association graph and extend the single-channel architecture to the multi-channel network. The proposed model can be seen as an ensemble method that fuses multiple algorithms at every iteration. Instead of averaging the estimates at the end of the ensemble, in our approach, the independent iterations of the ensembled algorithms exchange their information after each iteration via a 1x1 channel-wise convolution layer. Experiments show that our model improves the performance of traditional algorithms significantly. In addition, we propose a random sampling strategy to reduce the computational complexity and GPU memory usage, so the model applies to matching graphs with thousands of nodes. We evaluate the performance of our method on three tasks: geometric graph matching, semantic feature matching, and few-shot 3D shape classification. The proposed model performs comparably or outperforms the best existing GNN-based methods.
GeoEval: Benchmark for Evaluating LLMs and Multi-Modal Models on Geometry Problem-Solving
Feb 15, 2024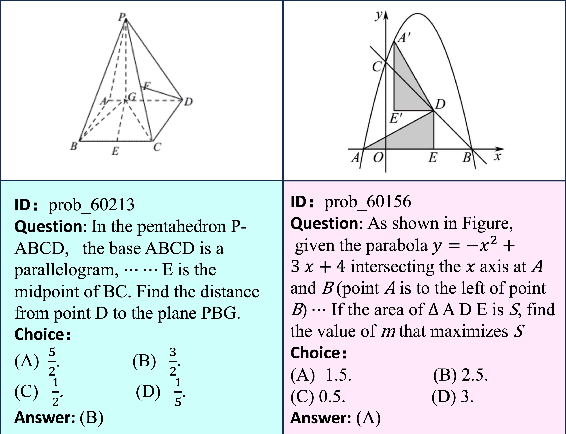
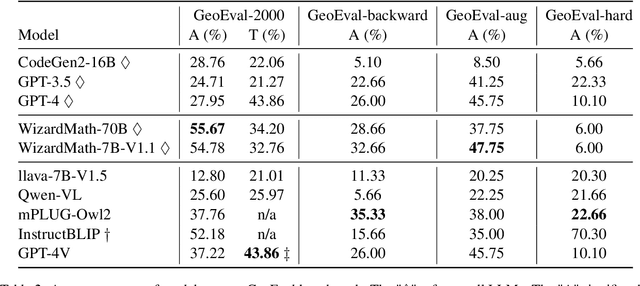
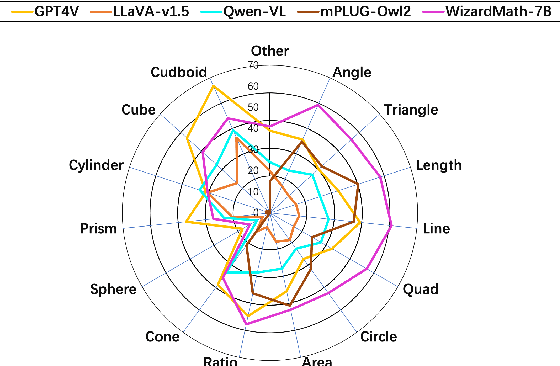
Recent advancements in Large Language Models (LLMs) and Multi-Modal Models (MMs) have demonstrated their remarkable capabilities in problem-solving. Yet, their proficiency in tackling geometry math problems, which necessitates an integrated understanding of both textual and visual information, has not been thoroughly evaluated. To address this gap, we introduce the GeoEval benchmark, a comprehensive collection that includes a main subset of 2000 problems, a 750 problem subset focusing on backward reasoning, an augmented subset of 2000 problems, and a hard subset of 300 problems. This benchmark facilitates a deeper investigation into the performance of LLMs and MMs on solving geometry math problems. Our evaluation of ten LLMs and MMs across these varied subsets reveals that the WizardMath model excels, achieving a 55.67\% accuracy rate on the main subset but only a 6.00\% accuracy on the challenging subset. This highlights the critical need for testing models against datasets on which they have not been pre-trained. Additionally, our findings indicate that GPT-series models perform more effectively on problems they have rephrased, suggesting a promising method for enhancing model capabilities.