 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodiedBrain: Expanding Performance Boundaries of Task Planning for Embodied Intelligence
Oct 23, 2025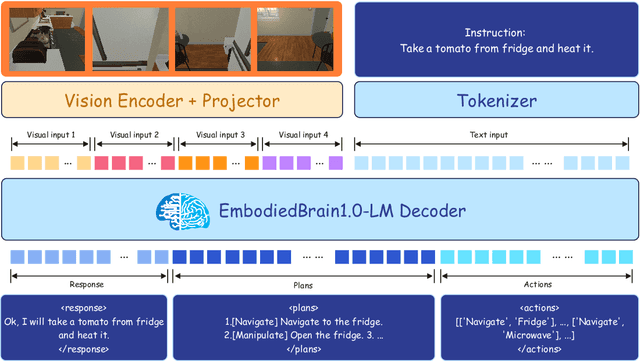
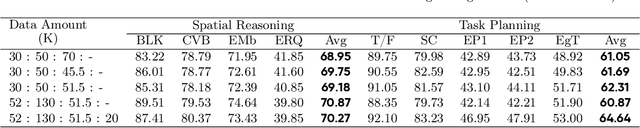

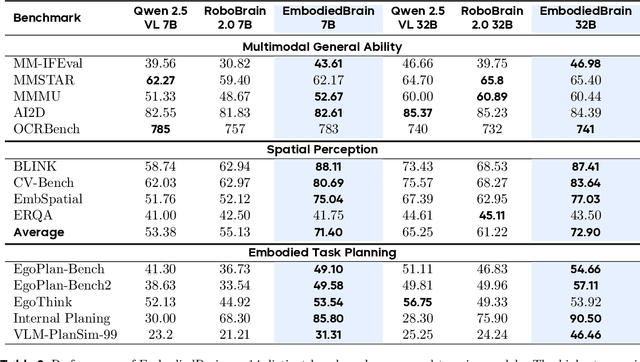
The realization of Artificial General Intelligence (AGI) necessitates Embodied AI agents capable of robust spatial perception, effective task planning, and adaptive execution in physical environments. However, current large language models (LLMs) and multimodal LLMs (MLLMs) for embodied tasks suffer from key limitations, including a significant gap between model design and agent requirements, an unavoidable trade-off between real-time latency and performance, and the use of unauthentic, offline evaluation metrics. To address these challenges, we propose EmbodiedBrain, a novel vision-language foundation model available in both 7B and 32B parameter sizes. Our framework features an agent-aligned data structure and employs a powerful training methodology that integrates large-scale Supervised Fine-Tuning (SFT) with Step-Augumented Group Relative Policy Optimization (Step-GRPO), which boosts long-horizon task success by integrating preceding steps as Guided Precursors. Furthermore, we incorporate a comprehensive reward system, including a Generative Reward Model (GRM) accelerated at the infrastructure level, to improve training efficiency. For enable thorough validation, we establish a three-part evaluation system encompassing General, Planning, and End-to-End Simulation Benchmarks, highlighted by the proposal and open-sourcing of a novel, challenging simulation environment. Experimental results demonstrate that EmbodiedBrain achieves superior performance across all metrics, establishing a new state-of-the-art for embodied foundation models. Towards paving the way for the next generation of generalist embodied agents, we open-source all of our data, model weight, and evaluating methods, which are available at https://zterobot.github.io/EmbodiedBrain.github.io.
GeoSense: Evaluating Identification and Application of Geometric Principles in Multimodal Reasoning
Apr 17, 2025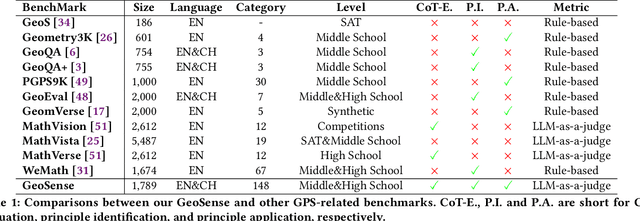
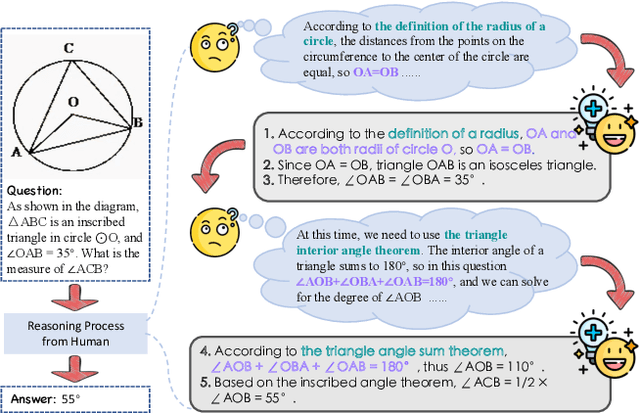
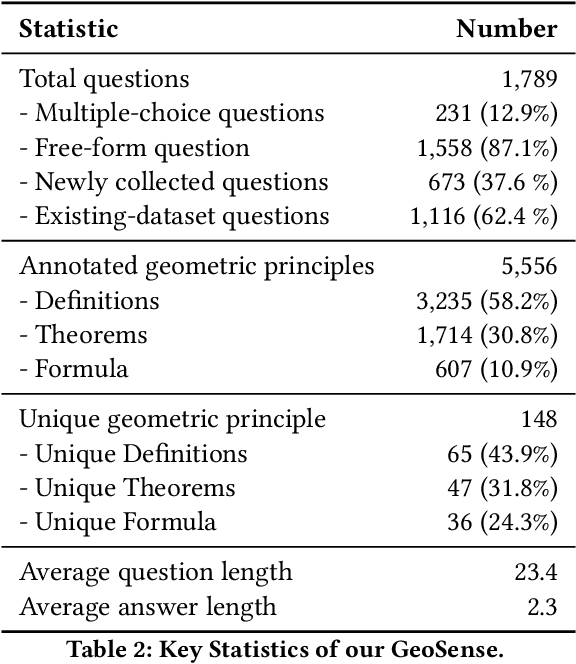
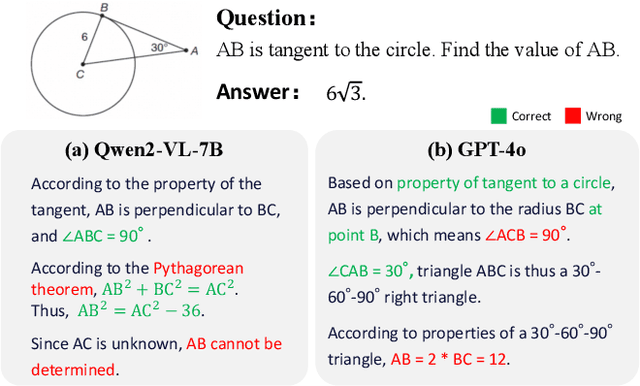
Geometry problem-solving (GPS), a challenging task requiring both visual comprehension and symbolic reasoning, effectively measures the reasoning capabilities of multimodal large language models (MLLMs). Humans exhibit strong reasoning ability in this task through accurate identification and adaptive application of geometric principles within visual contexts. However, existing benchmarks fail to jointly assess both dimensions of the human-like geometric reasoning mechanism in MLLMs, remaining a critical gap in assessing their ability to tackle GPS. To this end, we introduce GeoSense, the first comprehensive bilingual benchmark designed to systematically evaluate the geometric reasoning abilities of MLLMs through the lens of geometric principles. GeoSense features a five-level hierarchical framework of geometric principles spanning plane and solid geometry, an intricately annotated dataset of 1,789 problems, and an innovative evaluation strategy. Through extensive experiments on GeoSense with various open-source and closed-source MLLMs, we observe that Gemini-2.0-pro-flash performs best, achieving an overall score of $65.3$. Our in-depth analysis reveals that the identification and application of geometric principles remain a bottleneck for leading MLLMs, jointly hindering their reasoning abilities. These findings underscore GeoSense's potential to guide future advancements in MLLMs' geometric reasoning capabilities, paving the way for more robust and human-like reasoning in artificial intelligence.
Hybrid Training for Enhanced Multi-task Generalization in Multi-agent Reinforcement Learning
Aug 24, 2024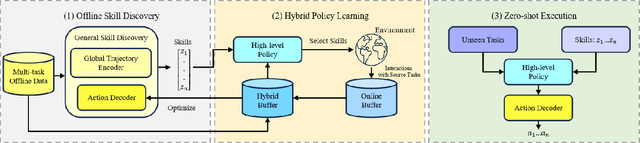
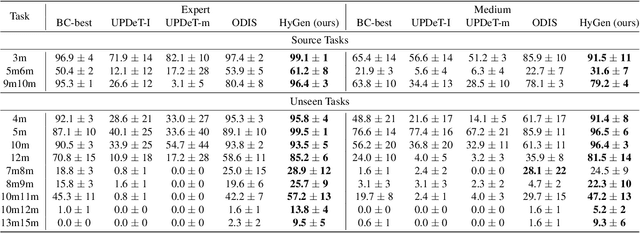
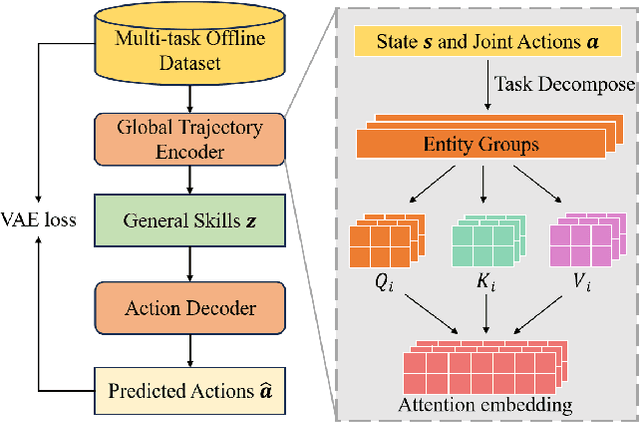
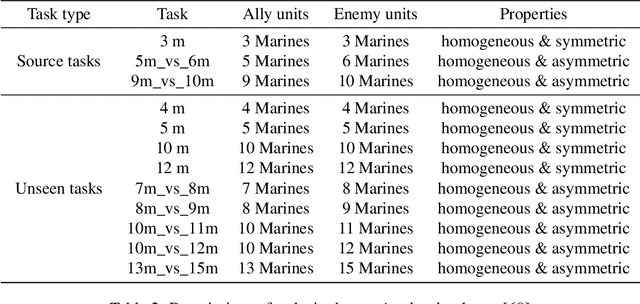
In multi-agent reinforcement learning (MARL), achieving multi-task generalization to diverse agents and objectives presents significant challenges. Existing online MARL algorithms primarily focus on single-task performance, but their lack of multi-task generalization capabilities typically results in substantial computational waste and limited real-life applicability. Meanwhile, existing offline multi-task MARL approaches are heavily dependent on data quality, often resulting in poor performance on unseen tasks. In this paper, we introduce HyGen, a novel hybrid MARL framework, Hybrid Training for Enhanced Multi-Task Generalization, which integrates online and offline learning to ensure both multi-task generalization and training efficiency. Specifically, our framework extracts potential general skills from offline multi-task datasets. We then train policies to select the optimal skills under the centralized training and decentralized execution paradigm (CTDE). During this stage, we utilize a replay buffer that integrates both offline data and online interactions. We empirically demonstrate that our framework effectively extracts and refines general skills, yielding impressive generalization to unseen tasks. Comparative analyses on the StarCraft multi-agent challenge show that HyGen outperforms a wide range of existing solely online and offline methods.
GeoEval: Benchmark for Evaluating LLMs and Multi-Modal Models on Geometry Problem-Solving
Feb 15, 2024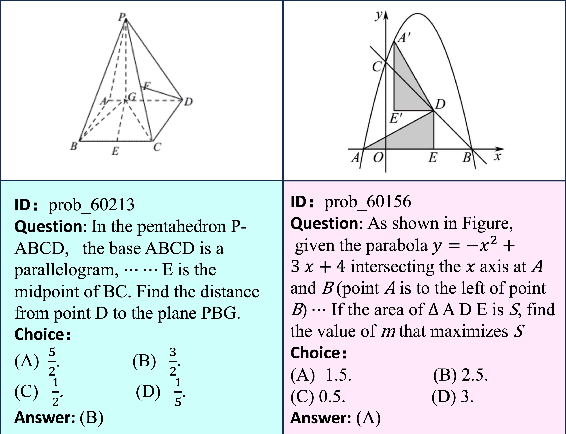
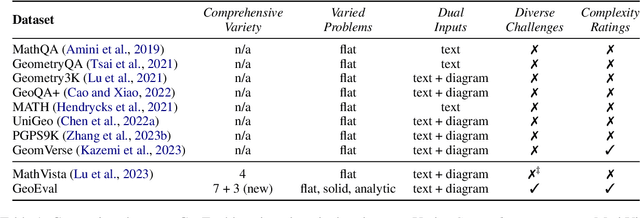
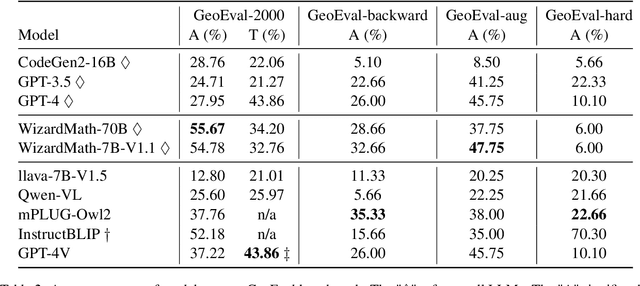
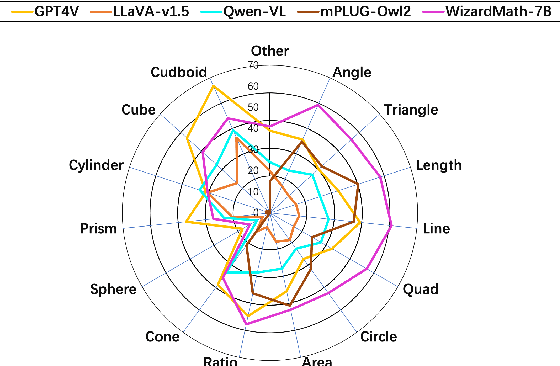
Recent advancements in Large Language Models (LLMs) and Multi-Modal Models (MMs) have demonstrated their remarkable capabilities in problem-solving. Yet, their proficiency in tackling geometry math problems, which necessitates an integrated understanding of both textual and visual information, has not been thoroughly evaluated. To address this gap, we introduce the GeoEval benchmark, a comprehensive collection that includes a main subset of 2000 problems, a 750 problem subset focusing on backward reasoning, an augmented subset of 2000 problems, and a hard subset of 300 problems. This benchmark facilitates a deeper investigation into the performance of LLMs and MMs on solving geometry math problems. Our evaluation of ten LLMs and MMs across these varied subsets reveals that the WizardMath model excels, achieving a 55.67\% accuracy rate on the main subset but only a 6.00\% accuracy on the challenging subset. This highlights the critical need for testing models against datasets on which they have not been pre-trained. Additionally, our findings indicate that GPT-series models perform more effectively on problems they have rephrased, suggesting a promising method for enhancing model capabilities.
WeLayout: WeChat Layout Analysis System for the ICDAR 2023 Competition on Robust Layout Segmentation in Corporate Documents
May 11, 2023



In this paper, we introduce WeLayout, a novel system for segmenting the layout of corporate documents, which stands for WeChat Layout Analysis System. Our approach utilizes a sophisticated ensemble of DINO and YOLO models, specifically developed for the ICDAR 2023 Competition on Robust Layout Segmentation. Our method significantly surpasses the baseline, securing a top position on the leaderboard with a mAP of 70.0. To achieve this performance, we concentrated on enhancing various aspects of the task, such as dataset augmentation, model architecture, bounding box refinement, and model ensemble techniques. Additionally, we trained the data separately for each document category to ensure a higher mean submission score. We also developed an algorithm for cell matching to further improve our performance. To identify the optimal weights and IoU thresholds for our model ensemble, we employed a Bayesian optimization algorithm called the Tree-Structured Parzen Estimator. Our approach effectively demonstrates the benefits of combining query-based and anchor-free models for achieving robust layout segmentation in corporate documents.
Convolution-enhanced Evolving Attention Networks
Dec 16, 2022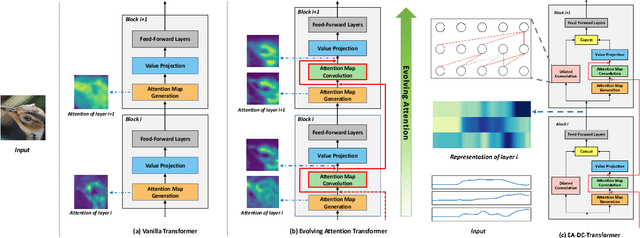

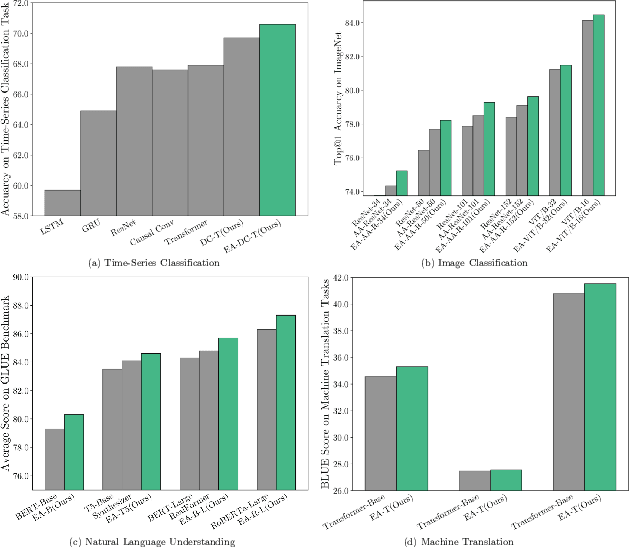
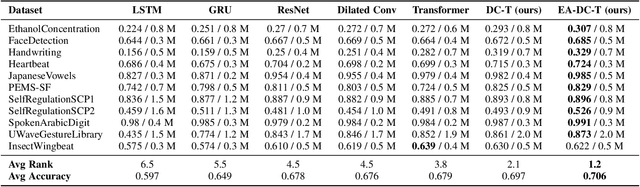
Attention-based neural networks, such as Transformers, have become ubiquitous in numerous applications, including computer vision, natural language processing, and time-series analysis. In all kinds of attention networks, the attention maps are crucial as they encode semantic dependencies between input tokens. However, most existing attention networks perform modeling or reasoning based on representations, wherein the attention maps of different layers are learned separately without explicit interactions. In this paper, we propose a novel and generic evolving attention mechanism, which directly models the evolution of inter-token relationships through a chain of residual convolutional modules. The major motivations are twofold. On the one hand, the attention maps in different layers share transferable knowledge, thus adding a residual connection can facilitate the information flow of inter-token relationships across layers. On the other hand, there is naturally an evolutionary trend among attention maps at different abstraction levels, so it is beneficial to exploit a dedicated convolution-based module to capture this process. Equipped with the proposed mechanism, the convolution-enhanced evolving attention networks achieve superior performance in various applications, including time-series representation, natural language understanding, machine translation, and image classification. Especially on time-series representation tasks, Evolving Attention-enhanced Dilated Convolutional (EA-DC-) Transformer outperforms state-of-the-art models significantly, achieving an average of 17% improvement compared to the best SOTA. To the best of our knowledge, this is the first work that explicitly models the layer-wise evolution of attention maps. Our implementation is available at https://github.com/pkuyym/EvolvingAttention
PGDP5K: A Diagram Parsing Dataset for Plane Geometry Problems
May 20, 2022
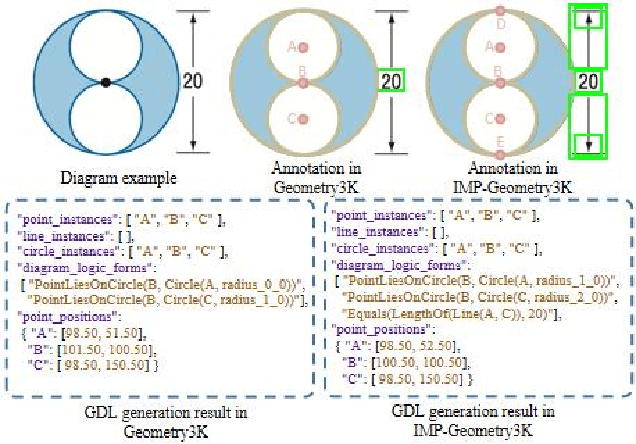
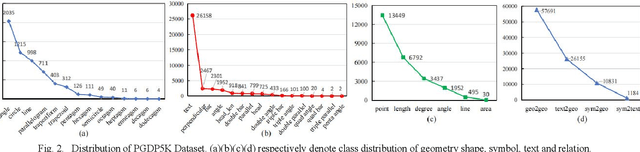
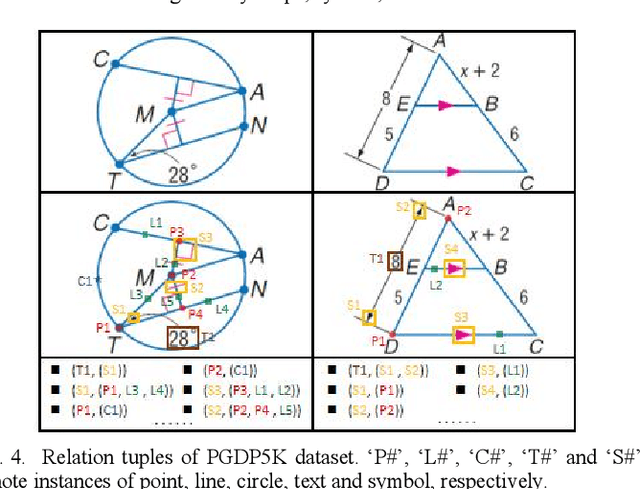
Diagram parsing is an important foundation for geometry problem solving, attracting increasing attention in the field of intelligent education and document image understanding. Due to the complex layout and between-primitive relationship, plane geometry diagram parsing (PGDP) is still a challenging task deserving further research and exploration. An appropriate dataset is critical for the research of PGDP. Although some datasets with rough annotations have been proposed to solve geometric problems, they are either small in scale or not publicly available. The rough annotations also make them not very useful. Thus, we propose a new large-scale geometry diagram dataset named PGDP5K and a novel annotation method. Our dataset consists of 5000 diagram samples composed of 16 shapes, covering 5 positional relations, 22 symbol types and 6 text types. Different from previous datasets, our PGDP5K dataset is labeled with more fine-grained annotations at primitive level, including primitive classes, locations and relationships. What is more, combined with above annotations and geometric prior knowledge, it can generate intelligible geometric propositions automatically and uniquely. We performed experiments on PGDP5K and IMP-Geometry3K datasets reveal that the state-of-the-art (SOTA) method achieves only 66.07% F1 value. This shows that PGDP5K presents a challenge for future research. Our dataset is available at http://www.nlpr.ia.ac.cn/databases/CASIA-PGDP5K/.
Competence-based Curriculum Learning for Multilingual Machine Translation
Sep 09, 2021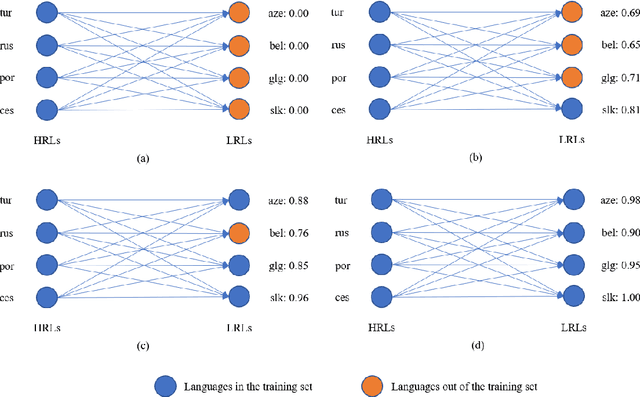
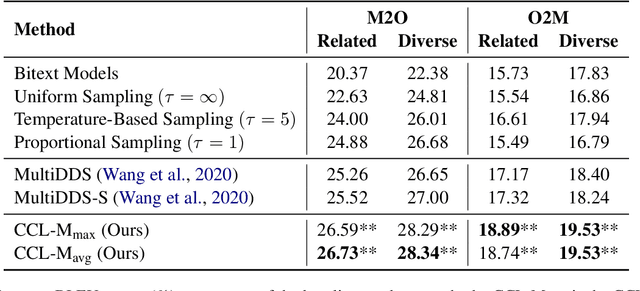
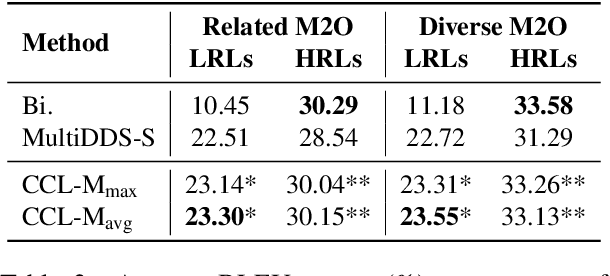
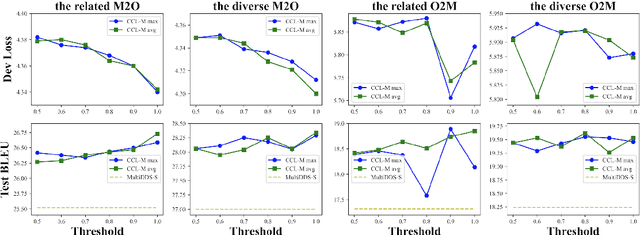
Currently, multilingual machine translation is receiving more and more attention since it brings better performance for low resource languages (LRLs) and saves more space. However, existing multilingual machine translation models face a severe challenge: imbalance. As a result, the translation performance of different languages in multilingual translation models are quite different. We argue that this imbalance problem stems from the different learning competencies of different languages. Therefore, we focus on balancing the learning competencies of different languages and propose Competence-based Curriculum Learning for Multilingual Machine Translation, named CCL-M. Specifically, we firstly define two competencies to help schedule the high resource languages (HRLs) and the low resource languages: 1) Self-evaluated Competence, evaluating how well the language itself has been learned; and 2) HRLs-evaluated Competence, evaluating whether an LRL is ready to be learned according to HRLs' Self-evaluated Competence. Based on the above competencies, we utilize the proposed CCL-M algorithm to gradually add new languages into the training set in a curriculum learning manner. Furthermore, we propose a novel competenceaware dynamic balancing sampling strategy for better selecting training samples in multilingual training. Experimental results show that our approach has achieved a steady and significant performance gain compared to the previous state-of-the-art approach on the TED talks dataset.
Evolving Attention with Residual Convolutions
Feb 20, 2021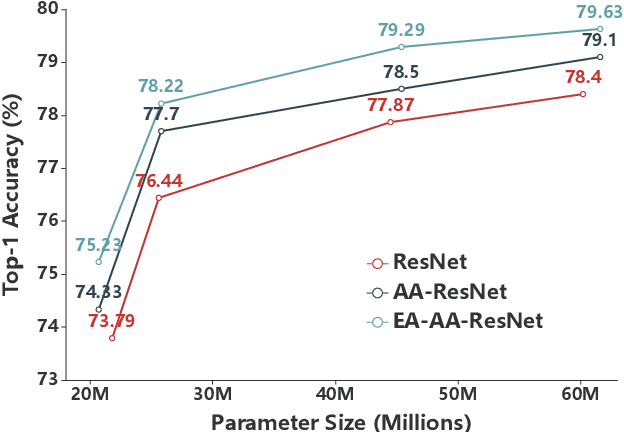
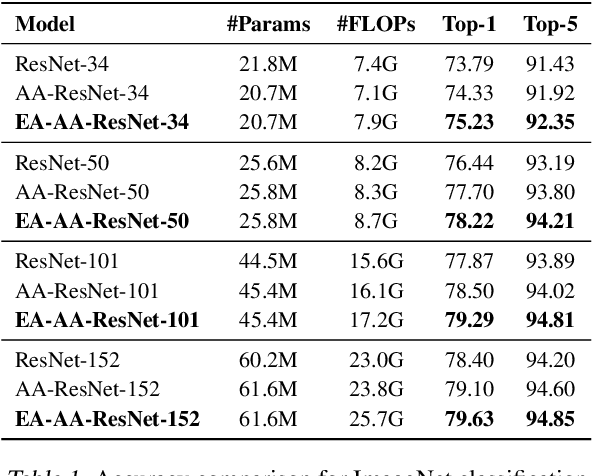
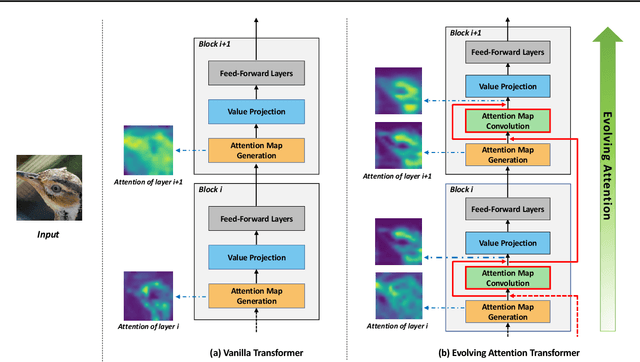
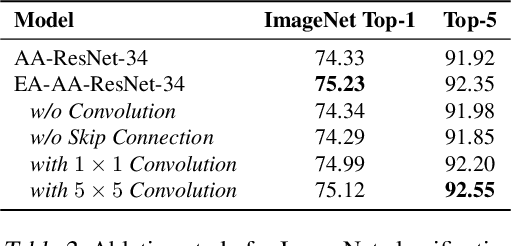
Transformer is a ubiquitous model for natural language processing and has attracted wide attentions in computer vision. The attention maps are indispensable for a transformer model to encode the dependencies among input tokens. However, they are learned independently in each layer and sometimes fail to capture precise patterns. In this paper, we propose a novel and generic mechanism based on evolving attention to improve the performance of transformers. On one hand, the attention maps in different layers share common knowledge, thus the ones in preceding layers can instruct the attention in succeeding layers through residual connections. On the other hand, low-level and high-level attentions vary in the level of abstraction, so we adopt convolutional layers to model the evolutionary process of attention maps. The proposed evolving attention mechanism achieves significant performance improvement over various state-of-the-art models for multiple tasks, including image classification, natural language understanding and machine translation.