 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcise Geometric Description as a Bridge: Unleashing the Potential of LLM for Plane Geometry Problem Solving
Jan 29, 2026Plane Geometry Problem Solving (PGPS) is a multimodal reasoning task that aims to solve a plane geometric problem based on a geometric diagram and problem textual descriptions. Although Large Language Models (LLMs) possess strong reasoning skills, their direct application to PGPS is hindered by their inability to process visual diagrams. Existing works typically fine-tune Multimodal LLMs (MLLMs) end-to-end on large-scale PGPS data to enhance visual understanding and reasoning simultaneously. However, such joint optimization may compromise base LLMs' inherent reasoning capability. In this work, we observe that LLM itself is potentially a powerful PGPS solver when appropriately formulating visual information as textual descriptions. We propose to train a MLLM Interpreter to generate geometric descriptions for the visual diagram, and an off-the-shelf LLM is utilized to perform reasoning. Specifically, we choose Conditional Declaration Language (CDL) as the geometric description as its conciseness eases the MLLM Interpreter training. The MLLM Interpreter is fine-tuned via CoT (Chain-of-Thought)-augmented SFT followed by GRPO to generate CDL. Instead of using a conventional solution-based reward that compares the reasoning result with the ground-truth answer, we design CDL matching rewards to facilitate more effective GRPO training, which provides more direct and denser guidance for CDL generation. To support training, we construct a new dataset, Formalgeo7k-Rec-CoT, by manually reviewing Formalgeo7k v2 and incorporating CoT annotations. Extensive experiments on Formalgeo7k-Rec-CoT, Unigeo, and MathVista show our method (finetuned on only 5.5k data) performs favorably against leading open-source and closed-source MLLMs.
CrossVid: A Comprehensive Benchmark for Evaluating Cross-Video Reasoning in Multimodal Large Language Models
Nov 15, 2025Cross-Video Reasoning (CVR) presents a significant challenge in video understanding, which requires simultaneous understanding of multiple videos to aggregate and compare information across groups of videos. Most existing video understanding benchmarks focus on single-video analysis, failing to assess the ability of multimodal large language models (MLLMs) to simultaneously reason over various videos. Recent benchmarks evaluate MLLMs' capabilities on multi-view videos that capture different perspectives of the same scene. However, their limited tasks hinder a thorough assessment of MLLMs in diverse real-world CVR scenarios. To this end, we introduce CrossVid, the first benchmark designed to comprehensively evaluate MLLMs' spatial-temporal reasoning ability in cross-video contexts. Firstly, CrossVid encompasses a wide spectrum of hierarchical tasks, comprising four high-level dimensions and ten specific tasks, thereby closely reflecting the complex and varied nature of real-world video understanding. Secondly, CrossVid provides 5,331 videos, along with 9,015 challenging question-answering pairs, spanning single-choice, multiple-choice, and open-ended question formats. Through extensive experiments on various open-source and closed-source MLLMs, we observe that Gemini-2.5-Pro performs best on CrossVid, achieving an average accuracy of 50.4%. Notably, our in-depth case study demonstrates that most current MLLMs struggle with CVR tasks, primarily due to their inability to integrate or compare evidence distributed across multiple videos for reasoning. These insights highlight the potential of CrossVid to guide future advancements in enhancing MLLMs' CVR capabilities.
GeoSense: Evaluating Identification and Application of Geometric Principles in Multimodal Reasoning
Apr 17, 2025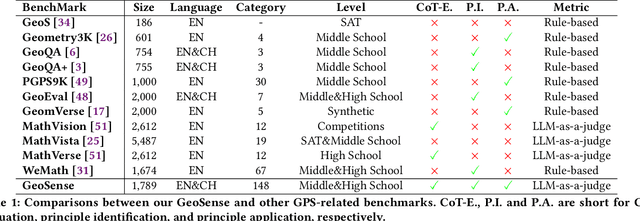
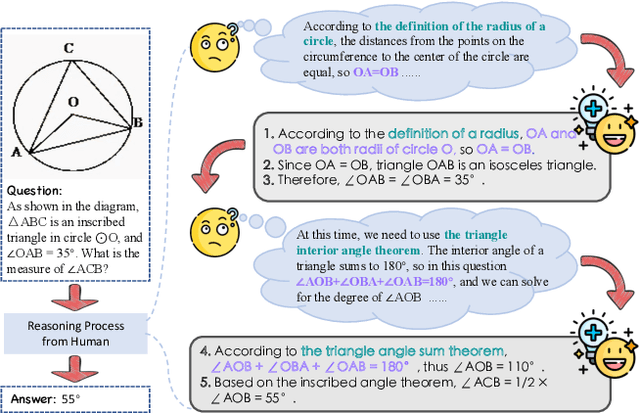
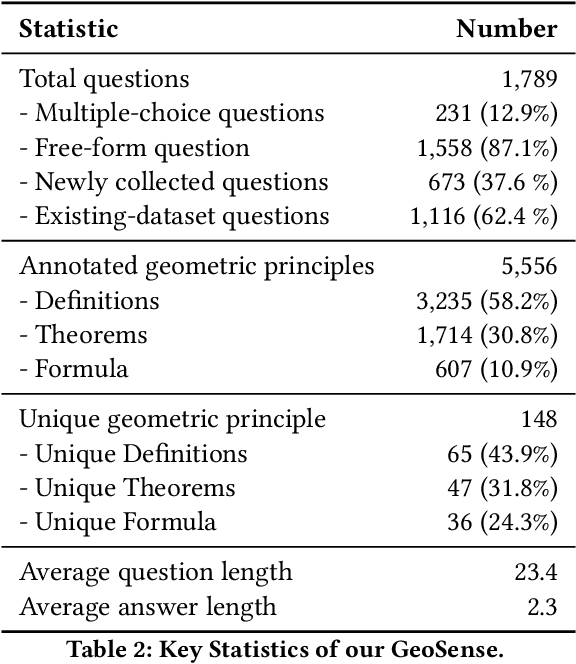
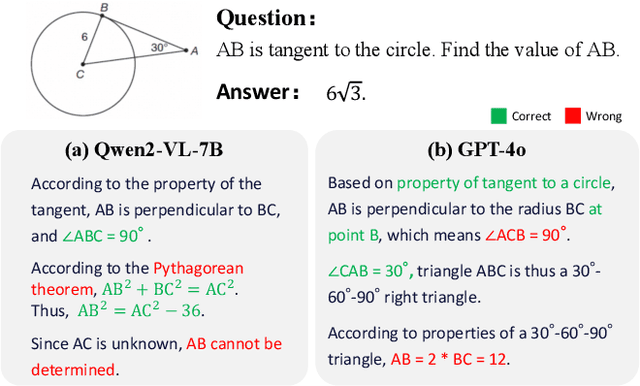
Geometry problem-solving (GPS), a challenging task requiring both visual comprehension and symbolic reasoning, effectively measures the reasoning capabilities of multimodal large language models (MLLMs). Humans exhibit strong reasoning ability in this task through accurate identification and adaptive application of geometric principles within visual contexts. However, existing benchmarks fail to jointly assess both dimensions of the human-like geometric reasoning mechanism in MLLMs, remaining a critical gap in assessing their ability to tackle GPS. To this end, we introduce GeoSense, the first comprehensive bilingual benchmark designed to systematically evaluate the geometric reasoning abilities of MLLMs through the lens of geometric principles. GeoSense features a five-level hierarchical framework of geometric principles spanning plane and solid geometry, an intricately annotated dataset of 1,789 problems, and an innovative evaluation strategy. Through extensive experiments on GeoSense with various open-source and closed-source MLLMs, we observe that Gemini-2.0-pro-flash performs best, achieving an overall score of $65.3$. Our in-depth analysis reveals that the identification and application of geometric principles remain a bottleneck for leading MLLMs, jointly hindering their reasoning abilities. These findings underscore GeoSense's potential to guide future advancements in MLLMs' geometric reasoning capabilities, paving the way for more robust and human-like reasoning in artificial intelligence.
Separate Motion from Appearance: Customizing Motion via Customizing Text-to-Video Diffusion Models
Jan 28, 2025Motion customization aims to adapt the diffusion model (DM) to generate videos with the motion specified by a set of video clips with the same motion concept. To realize this goal, the adaptation of DM should be possible to model the specified motion concept, without compromising the ability to generate diverse appearances. Thus, the key to solving this problem lies in how to separate the motion concept from the appearance in the adaptation process of DM. Typical previous works explore different ways to represent and insert a motion concept into large-scale pretrained text-to-video diffusion models, e.g., learning a motion LoRA, using latent noise residuals, etc. While those methods can encode the motion concept, they also inevitably encode the appearance in the reference videos, resulting in weakened appearance generation capability. In this paper, we follow the typical way to learn a motion LoRA to encode the motion concept, but propose two novel strategies to enhance motion-appearance separation, including temporal attention purification (TAP) and appearance highway (AH). Specifically, we assume that in the temporal attention module, the pretrained Value embeddings are sufficient to serve as basic components needed by producing a new motion. Thus, in TAP, we choose only to reshape the temporal attention with motion LoRAs so that Value embeddings can be reorganized to produce a new motion. Further, in AH, we alter the starting point of each skip connection in U-Net from the output of each temporal attention module to the output of each spatial attention module. Extensive experiments demonstrate that compared to previous works, our method can generate videos with appearance more aligned with the text descriptions and motion more consistent with the reference videos.
Efficient and Accurate Prompt Optimization: the Benefit of Memory in Exemplar-Guided Reflection
Nov 12, 2024



Automatic prompt engineering aims to enhance the generation quality of large language models (LLMs). Recent works utilize feedbacks generated from erroneous cases to guide the prompt optimization. During inference, they may further retrieve several semantically-related exemplars and concatenate them to the optimized prompts to improve the performance. However, those works only utilize the feedback at the current step, ignoring historical and unseleccted feedbacks which are potentially beneficial. Moreover, the selection of exemplars only considers the general semantic relationship and may not be optimal in terms of task performance and matching with the optimized prompt. In this work, we propose an Exemplar-Guided Reflection with Memory mechanism (ERM) to realize more efficient and accurate prompt optimization. Specifically, we design an exemplar-guided reflection mechanism where the feedback generation is additionally guided by the generated exemplars. We further build two kinds of memory to fully utilize the historical feedback information and support more effective exemplar retrieval. Empirical evaluations show our method surpasses previous state-of-the-arts with less optimization steps, i.e., improving F1 score by 10.1 on LIAR dataset, and reducing half of the optimization steps on ProTeGi.
ReCLIP++: Learn to Rectify the Bias of CLIP for Unsupervised Semantic Segmentation
Aug 13, 2024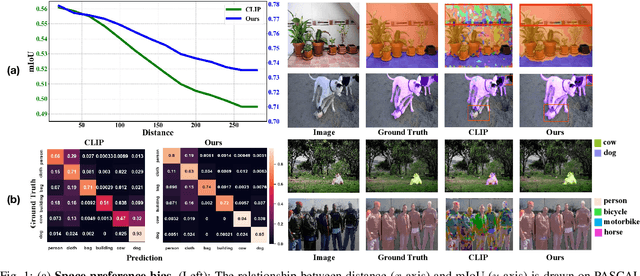
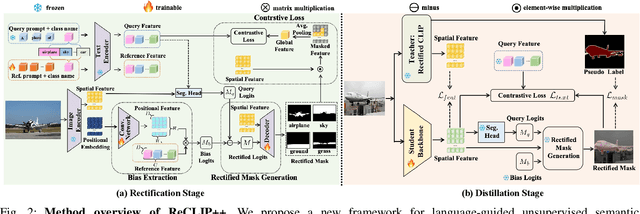
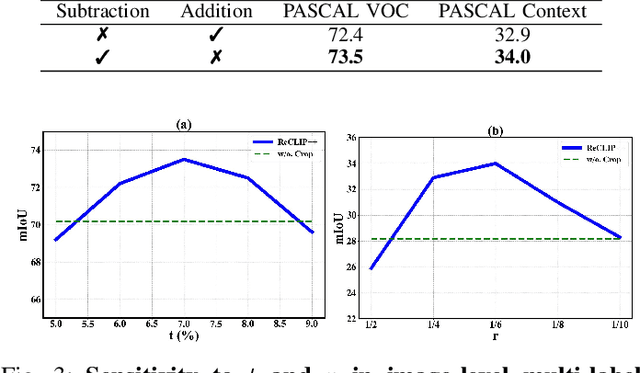

Recent works utilize CLIP to perform the challenging unsupervised semantic segmentation task where only images without annotations are available. However, we observe that when adopting CLIP to such a pixel-level understanding task, unexpected bias (including class-preference bias and space-preference bias) occurs. Previous works don't explicitly model the bias, which largely constrains the segmentation performance. In this paper, we propose to explicitly model and rectify the bias existing in CLIP to facilitate the unsupervised semantic segmentation task. Specifically, we design a learnable ''Reference'' prompt to encode class-preference bias and a projection of the positional embedding in vision transformer to encode space-preference bias respectively. To avoid interference, two kinds of biases are firstly independently encoded into the Reference feature and the positional feature. Via a matrix multiplication between two features, a bias logit map is generated to explicitly represent two kinds of biases. Then we rectify the logits of CLIP via a simple element-wise subtraction. To make the rectified results smoother and more contextual, we design a mask decoder which takes the feature of CLIP and rectified logits as input and outputs a rectified segmentation mask with the help of Gumbel-Softmax operation. To make the bias modeling and rectification process meaningful and effective, a contrastive loss based on masked visual features and the text features of different classes is imposed. To further improve the segmentation, we distill the knowledge from the rectified CLIP to the advanced segmentation architecture via minimizing our designed mask-guided, feature-guided and text-guided loss terms. Extensive experiments on various benchmarks demonstrate that ReCLIP++ performs favorably against previous SOTAs. The implementation is available at: https://github.com/dogehhh/ReCLIP.