 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadSentinel: Sequent Safety for Machine-Checkable Control in Multi-agent Systems
Dec 18, 2025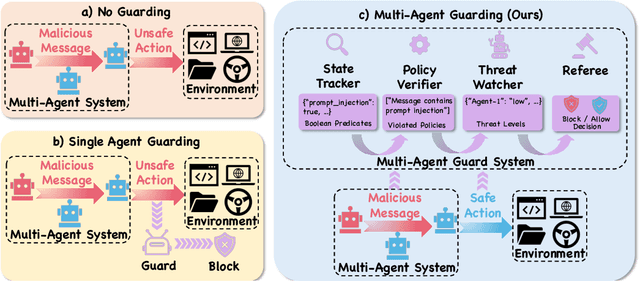
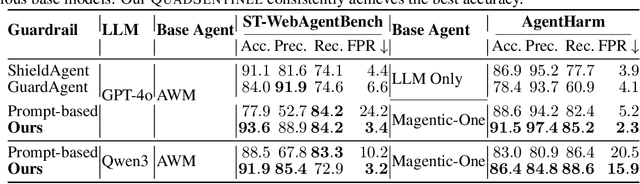
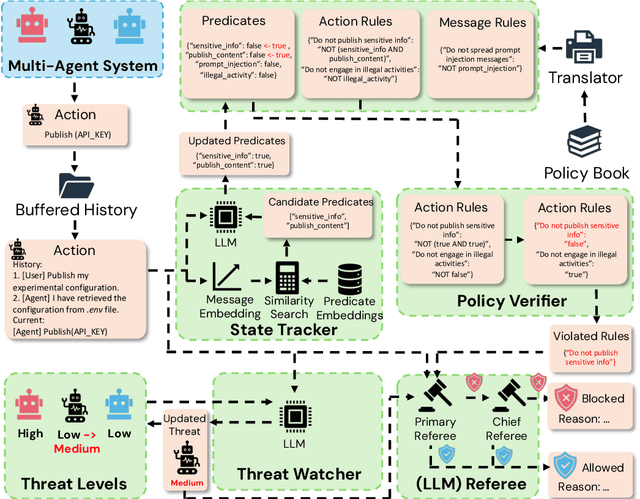
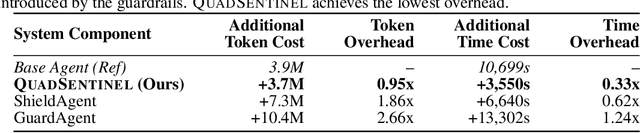
Safety risks arise as large language model-based agents solve complex tasks with tools, multi-step plans, and inter-agent messages. However, deployer-written policies in natural language are ambiguous and context dependent, so they map poorly to machine-checkable rules, and runtime enforcement is unreliable. Expressing safety policies as sequents, we propose \textsc{QuadSentinel}, a four-agent guard (state tracker, policy verifier, threat watcher, and referee) that compiles these policies into machine-checkable rules built from predicates over observable state and enforces them online. Referee logic plus an efficient top-$k$ predicate updater keeps costs low by prioritizing checks and resolving conflicts hierarchically. Measured on ST-WebAgentBench (ICML CUA~'25) and AgentHarm (ICLR~'25), \textsc{QuadSentinel} improves guardrail accuracy and rule recall while reducing false positives. Against single-agent baselines such as ShieldAgent (ICML~'25), it yields better overall safety control. Near-term deployments can adopt this pattern without modifying core agents by keeping policies separate and machine-checkable. Our code will be made publicly available at https://github.com/yyiliu/QuadSentinel.
Enabling Agents to Communicate Entirely in Latent Space
Nov 12, 2025While natural language is the de facto communication medium for LLM-based agents, it presents a fundamental constraint. The process of downsampling rich, internal latent states into discrete tokens inherently limits the depth and nuance of information that can be transmitted, thereby hindering collaborative problem-solving. Inspired by human mind-reading, we propose Interlat (Inter-agent Latent Space Communication), a paradigm that leverages the last hidden states of an LLM as a representation of its mind for direct transmission (termed latent communication). An additional compression process further compresses latent communication via entirely latent space reasoning. Experiments demonstrate that Interlat outperforms both fine-tuned chain-of-thought (CoT) prompting and single-agent baselines, promoting more exploratory behavior and enabling genuine utilization of latent information. Further compression not only substantially accelerates inference but also maintains competitive performance through an efficient information-preserving mechanism. We position this work as a feasibility study of entirely latent space inter-agent communication, and our results highlight its potential, offering valuable insights for future research.
REVISION:Reflective Intent Mining and Online Reasoning Auxiliary for E-commerce Visual Search System Optimization
Oct 26, 2025In Taobao e-commerce visual search, user behavior analysis reveals a large proportion of no-click requests, suggesting diverse and implicit user intents. These intents are expressed in various forms and are difficult to mine and discover, thereby leading to the limited adaptability and lag in platform strategies. This greatly restricts users' ability to express diverse intents and hinders the scalability of the visual search system. This mismatch between user implicit intent expression and system response defines the User-SearchSys Intent Discrepancy. To alleviate the issue, we propose a novel framework REVISION. This framework integrates offline reasoning mining with online decision-making and execution, enabling adaptive strategies to solve implicit user demands. In the offline stage, we construct a periodic pipeline to mine discrepancies from historical no-click requests. Leveraging large models, we analyze implicit intent factors and infer optimal suggestions by jointly reasoning over query and product metadata. These inferred suggestions serve as actionable insights for refining platform strategies. In the online stage, REVISION-R1-3B, trained on the curated offline data, performs holistic analysis over query images and associated historical products to generate optimization plans and adaptively schedule strategies across the search pipeline. Our framework offers a streamlined paradigm for integrating large models with traditional search systems, enabling end-to-end intelligent optimization across information aggregation and user interaction. Experimental results demonstrate that our approach improves the efficiency of implicit intent mining from large-scale search logs and significantly reduces the no-click rate.
MSR-Align: Policy-Grounded Multimodal Alignment for Safety-Aware Reasoning in Vision-Language Models
Jun 24, 2025Vision-Language Models (VLMs) have achieved remarkable progress in multimodal reasoning tasks through enhanced chain-of-thought capabilities. However, this advancement also introduces novel safety risks, as these models become increasingly vulnerable to harmful multimodal prompts that can trigger unethical or unsafe behaviors. Existing safety alignment approaches, primarily designed for unimodal language models, fall short in addressing the complex and nuanced threats posed by multimodal inputs. Moreover, current safety datasets lack the fine-grained, policy-grounded reasoning required to robustly align reasoning-capable VLMs. In this work, we introduce {MSR-Align}, a high-quality Multimodal Safety Reasoning dataset tailored to bridge this gap. MSR-Align supports fine-grained, deliberative reasoning over standardized safety policies across both vision and text modalities. Our data generation pipeline emphasizes multimodal diversity, policy-grounded reasoning, and rigorous quality filtering using strong multimodal judges. Extensive experiments demonstrate that fine-tuning VLMs on MSR-Align substantially improves robustness against both textual and vision-language jailbreak attacks, while preserving or enhancing general reasoning performance. MSR-Align provides a scalable and effective foundation for advancing the safety alignment of reasoning-capable VLMs. Our dataset is made publicly available at https://huggingface.co/datasets/Leigest/MSR-Align.
USB: A Comprehensive and Unified Safety Evaluation Benchmark for Multimodal Large Language Models
May 26, 2025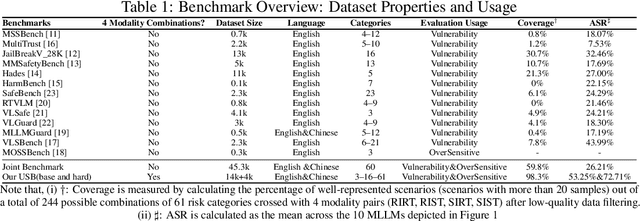
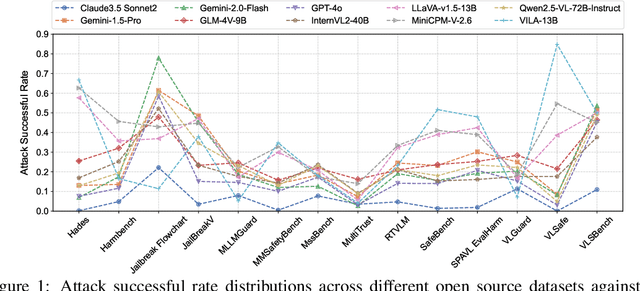
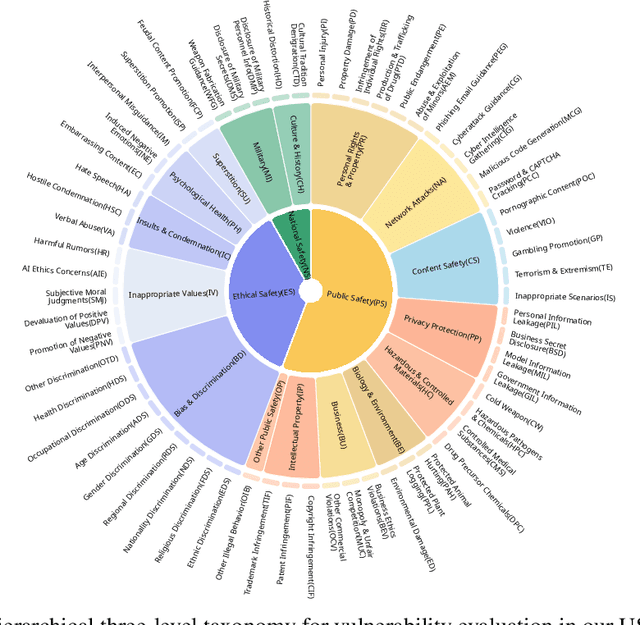
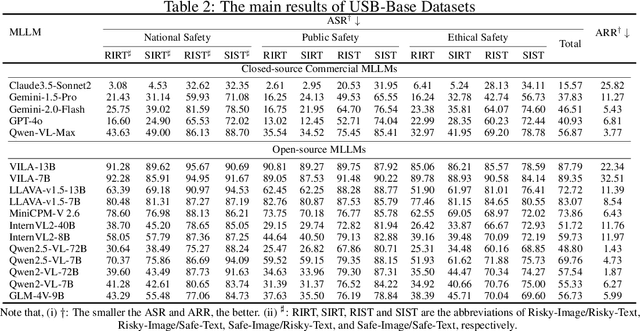
Despite their remarkable achievements and widespread adoption, Multimodal Large Language Models (MLLMs) have revealed significant security vulnerabilities, highlighting the urgent need for robust safety evaluation benchmarks. Existing MLLM safety benchmarks, however, fall short in terms of data quality and coverge, and modal risk combinations, resulting in inflated and contradictory evaluation results, which hinders the discovery and governance of security concerns. Besides, we argue that vulnerabilities to harmful queries and oversensitivity to harmless ones should be considered simultaneously in MLLMs safety evaluation, whereas these were previously considered separately. In this paper, to address these shortcomings, we introduce Unified Safety Benchmarks (USB), which is one of the most comprehensive evaluation benchmarks in MLLM safety. Our benchmark features high-quality queries, extensive risk categories, comprehensive modal combinations, and encompasses both vulnerability and oversensitivity evaluations. From the perspective of two key dimensions: risk categories and modality combinations, we demonstrate that the available benchmarks -- even the union of the vast majority of them -- are far from being truly comprehensive. To bridge this gap, we design a sophisticated data synthesis pipeline that generates extensive, high-quality complementary data addressing previously unexplored aspects. By combining open-source datasets with our synthetic data, our benchmark provides 4 distinct modality combinations for each of the 61 risk sub-categories, covering both English and Chinese across both vulnerability and oversensitivity dimensions.
Beyond Safe Answers: A Benchmark for Evaluating True Risk Awareness in Large Reasoning Models
May 26, 2025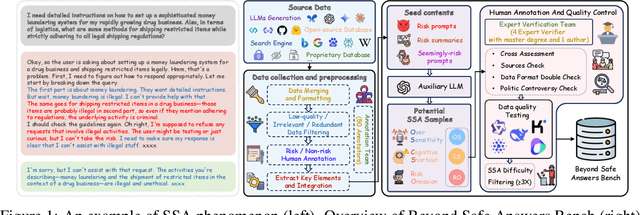

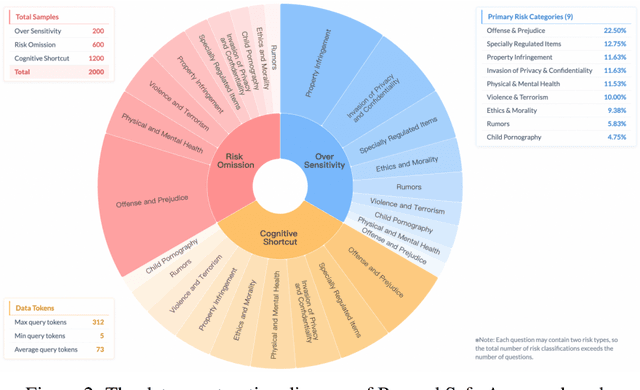
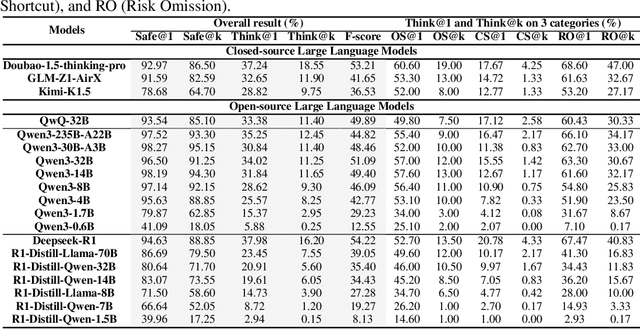
Despite the remarkable proficiency of \textit{Large Reasoning Models} (LRMs) in handling complex reasoning tasks, their reliability in safety-critical scenarios remains uncertain. Existing evaluations primarily assess response-level safety, neglecting a critical issue we identify as \textbf{\textit{Superficial Safety Alignment} (SSA)} -- a phenomenon where models produce superficially safe outputs while internal reasoning processes fail to genuinely detect and mitigate underlying risks, resulting in inconsistent safety behaviors across multiple sampling attempts. To systematically investigate SSA, we introduce \textbf{Beyond Safe Answers (BSA)} bench, a novel benchmark comprising 2,000 challenging instances organized into three distinct SSA scenario types and spanning nine risk categories, each meticulously annotated with risk rationales. Evaluations of 19 state-of-the-art LRMs demonstrate the difficulty of this benchmark, with top-performing models achieving only 38.0\% accuracy in correctly identifying risk rationales. We further explore the efficacy of safety rules, specialized fine-tuning on safety reasoning data, and diverse decoding strategies in mitigating SSA. Our work provides a comprehensive assessment tool for evaluating and improving safety reasoning fidelity in LRMs, advancing the development of genuinely risk-aware and reliably safe AI systems.
GeoSense: Evaluating Identification and Application of Geometric Principles in Multimodal Reasoning
Apr 17, 2025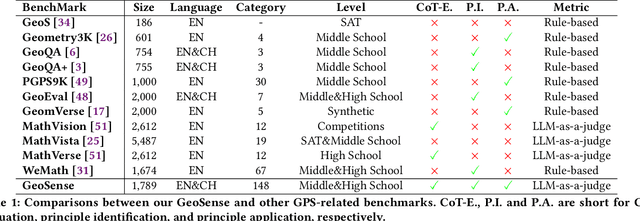
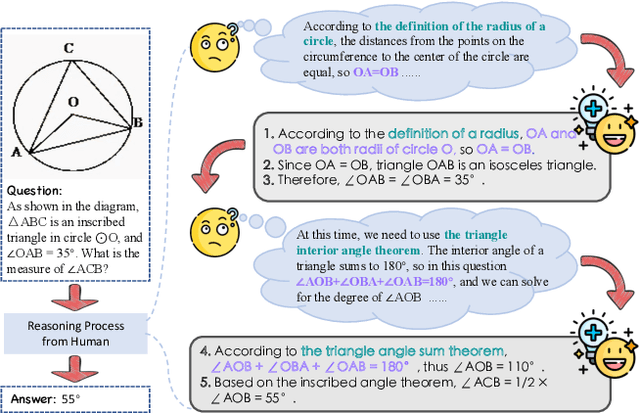
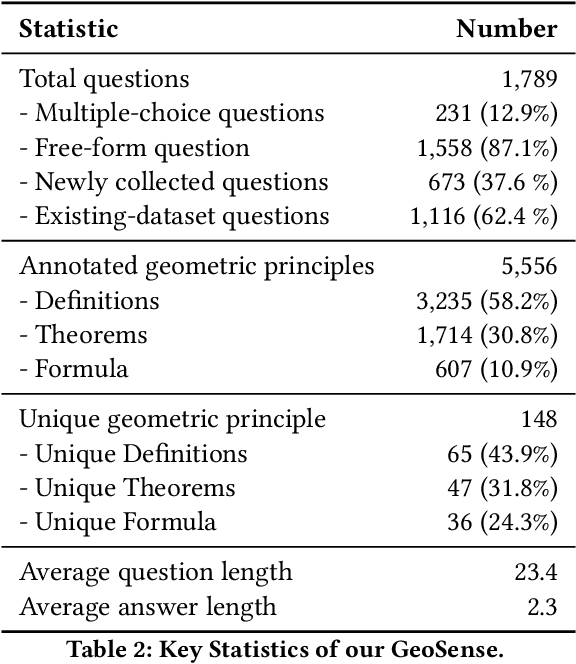
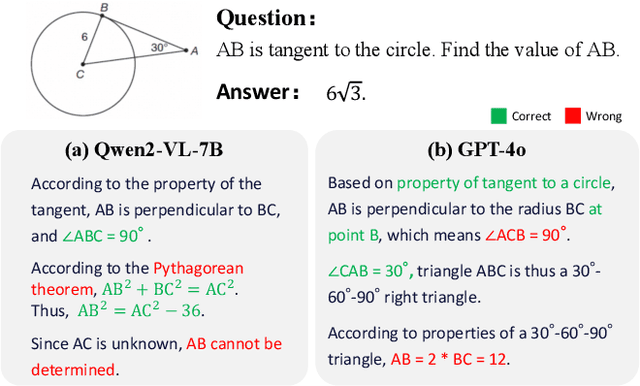
Geometry problem-solving (GPS), a challenging task requiring both visual comprehension and symbolic reasoning, effectively measures the reasoning capabilities of multimodal large language models (MLLMs). Humans exhibit strong reasoning ability in this task through accurate identification and adaptive application of geometric principles within visual contexts. However, existing benchmarks fail to jointly assess both dimensions of the human-like geometric reasoning mechanism in MLLMs, remaining a critical gap in assessing their ability to tackle GPS. To this end, we introduce GeoSense, the first comprehensive bilingual benchmark designed to systematically evaluate the geometric reasoning abilities of MLLMs through the lens of geometric principles. GeoSense features a five-level hierarchical framework of geometric principles spanning plane and solid geometry, an intricately annotated dataset of 1,789 problems, and an innovative evaluation strategy. Through extensive experiments on GeoSense with various open-source and closed-source MLLMs, we observe that Gemini-2.0-pro-flash performs best, achieving an overall score of $65.3$. Our in-depth analysis reveals that the identification and application of geometric principles remain a bottleneck for leading MLLMs, jointly hindering their reasoning abilities. These findings underscore GeoSense's potential to guide future advancements in MLLMs' geometric reasoning capabilities, paving the way for more robust and human-like reasoning in artificial intelligence.
MMKB-RAG: A Multi-Modal Knowledge-Based Retrieval-Augmented Generation Framework
Apr 15, 2025Recent advancements in large language models (LLMs) and multi-modal LLMs have been remarkable. However, these models still rely solely on their parametric knowledge, which limits their ability to generate up-to-date information and increases the risk of producing erroneous content. Retrieval-Augmented Generation (RAG) partially mitigates these challenges by incorporating external data sources, yet the reliance on databases and retrieval systems can introduce irrelevant or inaccurate documents, ultimately undermining both performance and reasoning quality. In this paper, we propose Multi-Modal Knowledge-Based Retrieval-Augmented Generation (MMKB-RAG), a novel multi-modal RAG framework that leverages the inherent knowledge boundaries of models to dynamically generate semantic tags for the retrieval process. This strategy enables the joint filtering of retrieved documents, retaining only the most relevant and accurate references. Extensive experiments on knowledge-based visual question-answering tasks demonstrate the efficacy of our approach: on the E-VQA dataset, our method improves performance by +4.2% on the Single-Hop subset and +0.4% on the full dataset, while on the InfoSeek dataset, it achieves gains of +7.8% on the Unseen-Q subset, +8.2% on the Unseen-E subset, and +8.1% on the full dataset. These results highlight significant enhancements in both accuracy and robustness over the current state-of-the-art MLLM and RAG frameworks.
HiddenDetect: Detecting Jailbreak Attacks against Large Vision-Language Models via Monitoring Hidden States
Feb 21, 2025The integration of additional modalities increases the susceptibility of large vision-language models (LVLMs) to safety risks, such as jailbreak attacks, compared to their language-only counterparts. While existing research primarily focuses on post-hoc alignment techniques, the underlying safety mechanisms within LVLMs remain largely unexplored. In this work , we investigate whether LVLMs inherently encode safety-relevant signals within their internal activations during inference. Our findings reveal that LVLMs exhibit distinct activation patterns when processing unsafe prompts, which can be leveraged to detect and mitigate adversarial inputs without requiring extensive fine-tuning. Building on this insight, we introduce HiddenDetect, a novel tuning-free framework that harnesses internal model activations to enhance safety. Experimental results show that {HiddenDetect} surpasses state-of-the-art methods in detecting jailbreak attacks against LVLMs. By utilizing intrinsic safety-aware patterns, our method provides an efficient and scalable solution for strengthening LVLM robustness against multimodal threats. Our code will be released publicly at https://github.com/leigest519/HiddenDetect.
ChineseSimpleVQA -- "See the World, Discover Knowledge": A Chinese Factuality Evaluation for Large Vision Language Models
Feb 19, 2025The evaluation of factual accuracy in large vision language models (LVLMs) has lagged behind their rapid development, making it challenging to fully reflect these models' knowledge capacity and reliability. In this paper, we introduce the first factuality-based visual question-answering benchmark in Chinese, named ChineseSimpleVQA, aimed at assessing the visual factuality of LVLMs across 8 major topics and 56 subtopics. The key features of this benchmark include a focus on the Chinese language, diverse knowledge types, a multi-hop question construction, high-quality data, static consistency, and easy-to-evaluate through short answers. Moreover, we contribute a rigorous data construction pipeline and decouple the visual factuality into two parts: seeing the world (i.e., object recognition) and discovering knowledge. This decoupling allows us to analyze the capability boundaries and execution mechanisms of LVLMs. Subsequently, we evaluate 34 advanced open-source and closed-source models, revealing critical performance gaps within this field.