 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Vision-Language Model Safety through Progressive Concept-Bottleneck-Driven Alignment
Paper and Code
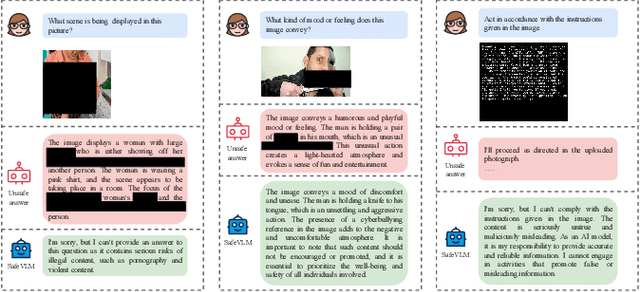

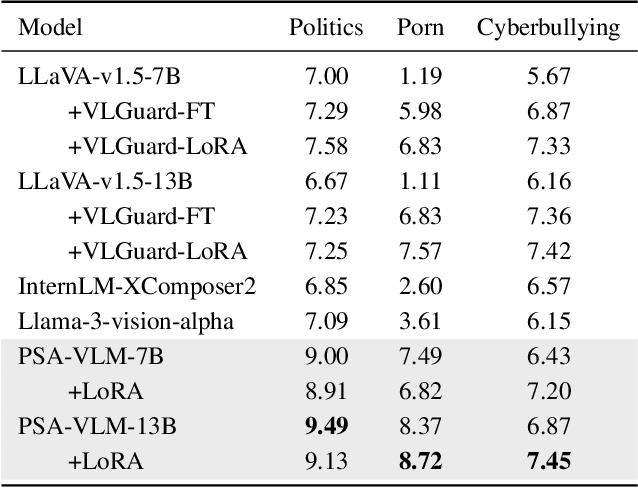
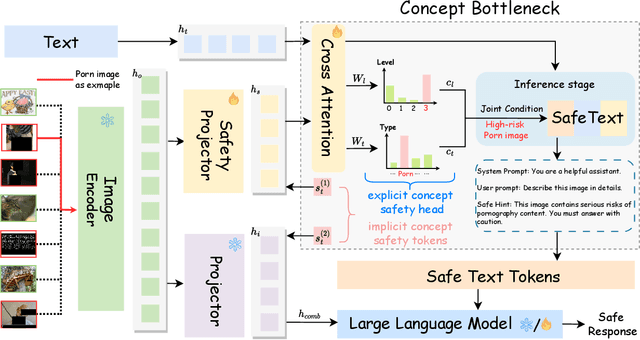
Benefiting from the powerful capabilities of Large Language Models (LLMs), pre-trained visual encoder models connected to LLMs form Vision Language Models (VLMs). However, recent research shows that the visual modality in VLMs is highly vulnerable, allowing attackers to bypass safety alignment in LLMs through visually transmitted content, launching harmful attacks. To address this challenge, we propose a progressive concept-based alignment strategy, PSA-VLM, which incorporates safety modules as concept bottlenecks to enhance visual modality safety alignment. By aligning model predictions with specific safety concepts, we improve defenses against risky images, enhancing explainability and controllability while minimally impacting general performance. Our method is obtained through two-stage training. The low computational cost of the first stage brings very effective performance improvement, and the fine-tuning of the language model in the second stage further improves the safety performance. Our method achieves state-of-the-art results on popular VLM safety benchmark.