 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalize Then Propagate: Efficient Homophilous Regularization for Few-shot Semi-Supervised Node Classification
Jan 15, 2025



Graph Neural Networks (GNNs) have demonstrated remarkable ability in semi-supervised node classification. However, most existing GNNs rely heavily on a large amount of labeled data for training, which is labor-intensive and requires extensive domain knowledge. In this paper, we first analyze the restrictions of GNNs generalization from the perspective of supervision signals in the context of few-shot semi-supervised node classification. To address these challenges, we propose a novel algorithm named NormProp, which utilizes the homophily assumption of unlabeled nodes to generate additional supervision signals, thereby enhancing the generalization against label scarcity. The key idea is to efficiently capture both the class information and the consistency of aggregation during message passing, via decoupling the direction and Euclidean norm of node representations. Moreover, we conduct a theoretical analysis to determine the upper bound of Euclidean norm, and then propose homophilous regularization to constraint the consistency of unlabeled nodes. Extensive experiments demonstrate that NormProp achieve state-of-the-art performance under low-label rate scenarios with low computational complexity.
Enhancing Vision-Language Model Safety through Progressive Concept-Bottleneck-Driven Alignment
Nov 18, 2024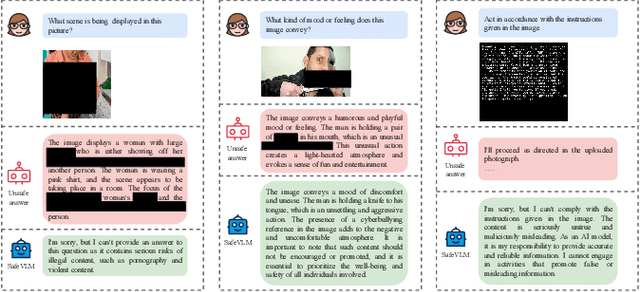

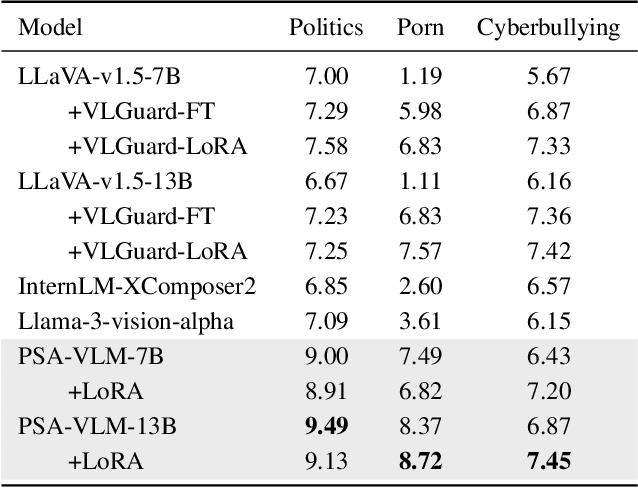
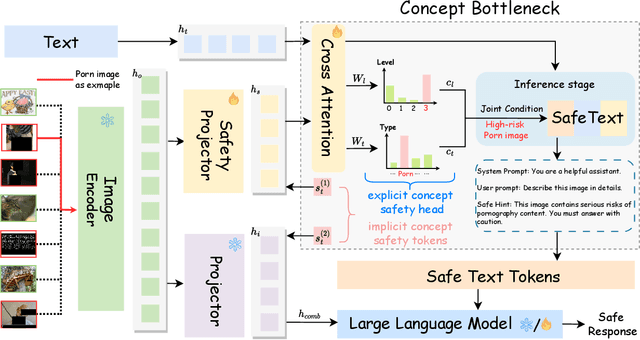
Benefiting from the powerful capabilities of Large Language Models (LLMs), pre-trained visual encoder models connected to LLMs form Vision Language Models (VLMs). However, recent research shows that the visual modality in VLMs is highly vulnerable, allowing attackers to bypass safety alignment in LLMs through visually transmitted content, launching harmful attacks. To address this challenge, we propose a progressive concept-based alignment strategy, PSA-VLM, which incorporates safety modules as concept bottlenecks to enhance visual modality safety alignment. By aligning model predictions with specific safety concepts, we improve defenses against risky images, enhancing explainability and controllability while minimally impacting general performance. Our method is obtained through two-stage training. The low computational cost of the first stage brings very effective performance improvement, and the fine-tuning of the language model in the second stage further improves the safety performance. Our method achieves state-of-the-art results on popular VLM safety benchmark.
GaGSL: Global-augmented Graph Structure Learning via Graph Information Bottleneck
Nov 07, 2024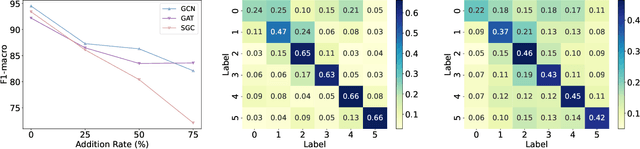
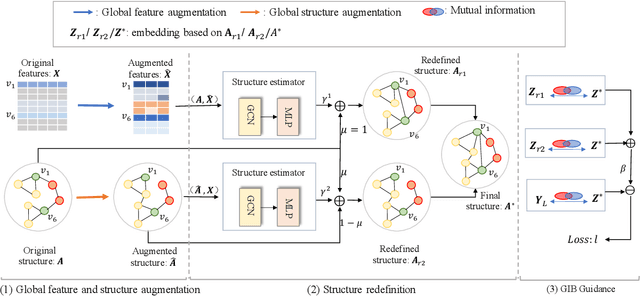
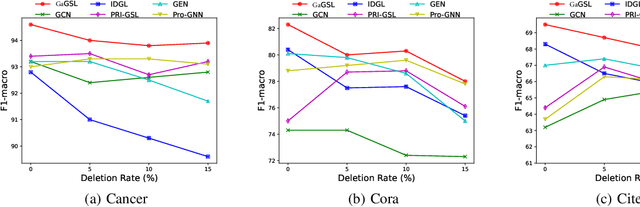
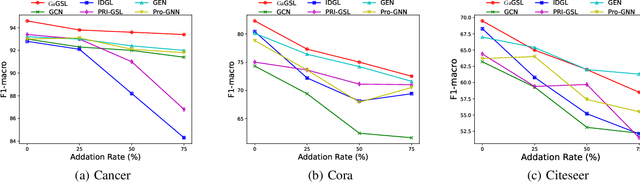
Graph neural networks (GNNs) are prominent for their effectiveness in processing graph data for semi-supervised node classification tasks. Most works of GNNs assume that the observed structure accurately represents the underlying node relationships. However, the graph structure is inevitably noisy or incomplete in reality, which can degrade the quality of graph representations. Therefore, it is imperative to learn a clean graph structure that balances performance and robustness. In this paper, we propose a novel method named \textit{Global-augmented Graph Structure Learning} (GaGSL), guided by the Graph Information Bottleneck (GIB) principle. The key idea behind GaGSL is to learn a compact and informative graph structure for node classification tasks. Specifically, to mitigate the bias caused by relying solely on the original structure, we first obtain augmented features and augmented structure through global feature augmentation and global structure augmentation. We then input the augmented features and augmented structure into a structure estimator with different parameters for optimization and re-definition of the graph structure, respectively. The redefined structures are combined to form the final graph structure. Finally, we employ GIB based on mutual information to guide the optimization of the graph structure to obtain the minimum sufficient graph structure. Comprehensive evaluations across a range of datasets reveal the outstanding performance and robustness of GaGSL compared with the state-of-the-art methods.
Graph Neural Networks with Coarse- and Fine-Grained Division for Mitigating Label Sparsity and Noise
Nov 06, 2024Graph Neural Networks (GNNs) have gained considerable prominence in semi-supervised learning tasks in processing graph-structured data, primarily owing to their message-passing mechanism, which largely relies on the availability of clean labels. However, in real-world scenarios, labels on nodes of graphs are inevitably noisy and sparsely labeled, significantly degrading the performance of GNNs. Exploring robust GNNs for semi-supervised node classification in the presence of noisy and sparse labels remains a critical challenge. Therefore, we propose a novel \textbf{G}raph \textbf{N}eural \textbf{N}etwork with \textbf{C}oarse- and \textbf{F}ine-\textbf{G}rained \textbf{D}ivision for mitigating label sparsity and noise, namely GNN-CFGD. The key idea of GNN-CFGD is reducing the negative impact of noisy labels via coarse- and fine-grained division, along with graph reconstruction. Specifically, we first investigate the effectiveness of linking unlabeled nodes to cleanly labeled nodes, demonstrating that this approach is more effective in combating labeling noise than linking to potentially noisy labeled nodes. Based on this observation, we introduce a Gaussian Mixture Model (GMM) based on the memory effect to perform a coarse-grained division of the given labels into clean and noisy labels. Next, we propose a clean labels oriented link that connects unlabeled nodes to cleanly labeled nodes, aimed at mitigating label sparsity and promoting supervision propagation. Furthermore, to provide refined supervision for noisy labeled nodes and additional supervision for unlabeled nodes, we fine-grain the noisy labeled and unlabeled nodes into two candidate sets based on confidence, respectively. Extensive experiments on various datasets demonstrate the superior effectiveness and robustness of GNN-CFGD.
Parameterize Structure with Differentiable Template for 3D Shape Generation
Oct 15, 2024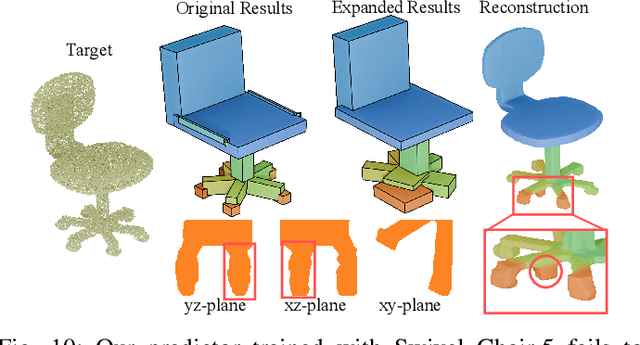
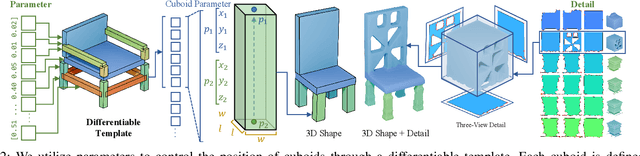

Structural representation is crucial for reconstructing and generating editable 3D shapes with part semantics. Recent 3D shape generation works employ complicated networks and structure definitions relying on hierarchical annotations and pay less attention to the details inside parts. In this paper, we propose the method that parameterizes the shared structure in the same category using a differentiable template and corresponding fixed-length parameters. Specific parameters are fed into the template to calculate cuboids that indicate a concrete shape. We utilize the boundaries of three-view drawings of each cuboid to further describe the inside details. Shapes are represented with the parameters and three-view details inside cuboids, from which the SDF can be calculated to recover the object. Benefiting from our fixed-length parameters and three-view details, our networks for reconstruction and generation are simple and effective to learn the latent space. Our method can reconstruct or generate diverse shapes with complicated details, and interpolate them smoothly. Extensive evaluations demonstrate the superiority of our method on reconstruction from point cloud, generation, and interpolation.
Similarity-Navigated Conformal Prediction for Graph Neural Networks
May 23, 2024



Graph Neural Networks have achieved remarkable accuracy in semi-supervised node classification tasks. However, these results lack reliable uncertainty estimates. Conformal prediction methods provide a theoretical guarantee for node classification tasks, ensuring that the conformal prediction set contains the ground-truth label with a desired probability (e.g., 95%). In this paper, we empirically show that for each node, aggregating the non-conformity scores of nodes with the same label can improve the efficiency of conformal prediction sets. This observation motivates us to propose a novel algorithm named Similarity-Navigated Adaptive Prediction Sets (SNAPS), which aggregates the non-conformity scores based on feature similarity and structural neighborhood. The key idea behind SNAPS is that nodes with high feature similarity or direct connections tend to have the same label. By incorporating adaptive similar nodes information, SNAPS can generate compact prediction sets and increase the singleton hit ratio (correct prediction sets of size one). Moreover, we theoretically provide a finite-sample coverage guarantee of SNAPS. Extensive experiments demonstrate the superiority of SNAPS, improving the efficiency of prediction sets and singleton hit ratio while maintaining valid coverage.
Safety Alignment for Vision Language Models
May 22, 2024Benefiting from the powerful capabilities of Large Language Models (LLMs), pre-trained visual encoder models connected to an LLMs can realize Vision Language Models (VLMs). However, existing research shows that the visual modality of VLMs is vulnerable, with attackers easily bypassing LLMs' safety alignment through visual modality features to launch attacks. To address this issue, we enhance the existing VLMs' visual modality safety alignment by adding safety modules, including a safety projector, safety tokens, and a safety head, through a two-stage training process, effectively improving the model's defense against risky images. For example, building upon the LLaVA-v1.5 model, we achieve a safety score of 8.26, surpassing the GPT-4V on the Red Teaming Visual Language Models (RTVLM) benchmark. Our method boasts ease of use, high flexibility, and strong controllability, and it enhances safety while having minimal impact on the model's general performance. Moreover, our alignment strategy also uncovers some possible risky content within commonly used open-source multimodal datasets. Our code will be open sourced after the anonymous review.
FedCompetitors: Harmonious Collaboration in Federated Learning with Competing Participants
Dec 18, 2023Federated learning (FL) provides a privacy-preserving approach for collaborative training of machine learning models. Given the potential data heterogeneity, it is crucial to select appropriate collaborators for each FL participant (FL-PT) based on data complementarity. Recent studies have addressed this challenge. Similarly, it is imperative to consider the inter-individual relationships among FL-PTs where some FL-PTs engage in competition. Although FL literature has acknowledged the significance of this scenario, practical methods for establishing FL ecosystems remain largely unexplored. In this paper, we extend a principle from the balance theory, namely ``the friend of my enemy is my enemy'', to ensure the absence of conflicting interests within an FL ecosystem. The extended principle and the resulting problem are formulated via graph theory and integer linear programming. A polynomial-time algorithm is proposed to determine the collaborators of each FL-PT. The solution guarantees high scalability, allowing even competing FL-PTs to smoothly join the ecosystem without conflict of interest. The proposed framework jointly considers competition and data heterogeneity. Extensive experiments on real-world and synthetic data demonstrate its efficacy compared to five alternative approaches, and its ability to establish efficient collaboration networks among FL-PTs.
LaplaceConfidence: a Graph-based Approach for Learning with Noisy Labels
Jul 31, 2023



In real-world applications, perfect labels are rarely available, making it challenging to develop robust machine learning algorithms that can handle noisy labels. Recent methods have focused on filtering noise based on the discrepancy between model predictions and given noisy labels, assuming that samples with small classification losses are clean. This work takes a different approach by leveraging the consistency between the learned model and the entire noisy dataset using the rich representational and topological information in the data. We introduce LaplaceConfidence, a method that to obtain label confidence (i.e., clean probabilities) utilizing the Laplacian energy. Specifically, it first constructs graphs based on the feature representations of all noisy samples and minimizes the Laplacian energy to produce a low-energy graph. Clean labels should fit well into the low-energy graph while noisy ones should not, allowing our method to determine data's clean probabilities. Furthermore, LaplaceConfidence is embedded into a holistic method for robust training, where co-training technique generates unbiased label confidence and label refurbishment technique better utilizes it. We also explore the dimensionality reduction technique to accommodate our method on large-scale noisy datasets. Our experiments demonstrate that LaplaceConfidence outperforms state-of-the-art methods on benchmark datasets under both synthetic and real-world noise.
DOS: Diverse Outlier Sampling for Out-of-Distribution Detection
Jun 03, 2023Modern neural networks are known to give overconfident prediction for out-of-distribution inputs when deployed in the open world. It is common practice to leverage a surrogate outlier dataset to regularize the model during training, and recent studies emphasize the role of uncertainty in designing the sampling strategy for outlier dataset. However, the OOD samples selected solely based on predictive uncertainty can be biased towards certain types, which may fail to capture the full outlier distribution. In this work, we empirically show that diversity is critical in sampling outliers for OOD detection performance. Motivated by the observation, we propose a straightforward and novel sampling strategy named DOS (Diverse Outlier Sampling) to select diverse and informative outliers. Specifically, we cluster the normalized features at each iteration, and the most informative outlier from each cluster is selected for model training with absent category loss. With DOS, the sampled outliers efficiently shape a globally compact decision boundary between ID and OOD data. Extensive experiments demonstrate the superiority of DOS, reducing the average FPR95 by up to 25.79% on CIFAR-100 with TI-300K.