 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaplaceConfidence: a Graph-based Approach for Learning with Noisy Labels
Jul 31, 2023



In real-world applications, perfect labels are rarely available, making it challenging to develop robust machine learning algorithms that can handle noisy labels. Recent methods have focused on filtering noise based on the discrepancy between model predictions and given noisy labels, assuming that samples with small classification losses are clean. This work takes a different approach by leveraging the consistency between the learned model and the entire noisy dataset using the rich representational and topological information in the data. We introduce LaplaceConfidence, a method that to obtain label confidence (i.e., clean probabilities) utilizing the Laplacian energy. Specifically, it first constructs graphs based on the feature representations of all noisy samples and minimizes the Laplacian energy to produce a low-energy graph. Clean labels should fit well into the low-energy graph while noisy ones should not, allowing our method to determine data's clean probabilities. Furthermore, LaplaceConfidence is embedded into a holistic method for robust training, where co-training technique generates unbiased label confidence and label refurbishment technique better utilizes it. We also explore the dimensionality reduction technique to accommodate our method on large-scale noisy datasets. Our experiments demonstrate that LaplaceConfidence outperforms state-of-the-art methods on benchmark datasets under both synthetic and real-world noise.
Semi-Supervised Learning with Multi-Head Co-Training
Jul 10, 2021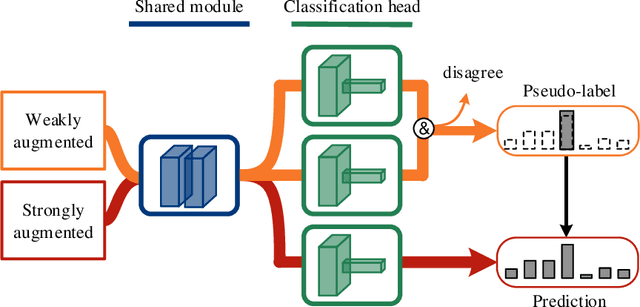


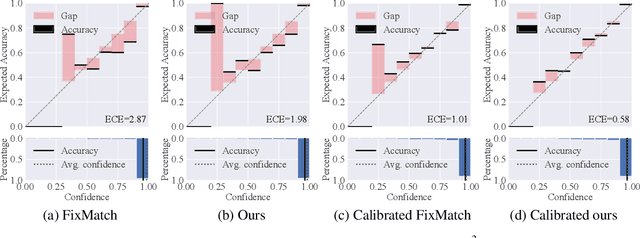
Co-training, extended from self-training, is one of the frameworks for semi-supervised learning. It works at the cost of training extra classifiers, where the algorithm should be delicately designed to prevent individual classifiers from collapsing into each other. In this paper, we present a simple and efficient co-training algorithm, named Multi-Head Co-Training, for semi-supervised image classification. By integrating base learners into a multi-head structure, the model is in a minimal amount of extra parameters. Every classification head in the unified model interacts with its peers through a "Weak and Strong Augmentation" strategy, achieving single-view co-training without promoting diversity explicitly. The effectiveness of Multi-Head Co-Training is demonstrated in an empirical study on standard semi-supervised learning benchmarks.