 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMKU-Bench: A Multimodal Update Benchmark for Diverse Visual Knowledge
Mar 16, 2026As real-world knowledge continues to evolve, the parametric knowledge acquired by multimodal models during pretraining becomes increasingly difficult to remain consistent with real-world knowledge. Existing research on multimodal knowledge updating focuses only on learning previously unknown knowledge, while overlooking the need to update knowledge that the model has already mastered but that later changes; moreover, evaluation is limited to the same modality, lacking a systematic analysis of cross-modal consistency. To address these issues, this paper proposes MMKU-Bench, a comprehensive evaluation benchmark for multimodal knowledge updating, which contains over 25k knowledge instances and more than 49k images, covering two scenarios, updated knowledge and unknown knowledge, thereby enabling comparative analysis of learning across different knowledge types. On this benchmark, we evaluate a variety of representative approaches, including supervised fine-tuning (SFT), reinforcement learning from human feedback (RLHF), and knowledge editing (KE). Experimental results show that SFT and RLHF are prone to catastrophic forgetting, while KE better preserve general capabilities but exhibit clear limitations in continual updating. Overall, MMKU-Bench provides a reliable and comprehensive evaluation benchmark for multimodal knowledge updating, advancing progress in this field.
Membership Inference Attacks Against Fine-tuned Diffusion Language Models
Jan 27, 2026Diffusion Language Models (DLMs) represent a promising alternative to autoregressive language models, using bidirectional masked token prediction. Yet their susceptibility to privacy leakage via Membership Inference Attacks (MIA) remains critically underexplored. This paper presents the first systematic investigation of MIA vulnerabilities in DLMs. Unlike the autoregressive models' single fixed prediction pattern, DLMs' multiple maskable configurations exponentially increase attack opportunities. This ability to probe many independent masks dramatically improves detection chances. To exploit this, we introduce SAMA (Subset-Aggregated Membership Attack), which addresses the sparse signal challenge through robust aggregation. SAMA samples masked subsets across progressive densities and applies sign-based statistics that remain effective despite heavy-tailed noise. Through inverse-weighted aggregation prioritizing sparse masks' cleaner signals, SAMA transforms sparse memorization detection into a robust voting mechanism. Experiments on nine datasets show SAMA achieves 30% relative AUC improvement over the best baseline, with up to 8 times improvement at low false positive rates. These findings reveal significant, previously unknown vulnerabilities in DLMs, necessitating the development of tailored privacy defenses.
Window-based Membership Inference Attacks Against Fine-tuned Large Language Models
Jan 06, 2026Most membership inference attacks (MIAs) against Large Language Models (LLMs) rely on global signals, like average loss, to identify training data. This approach, however, dilutes the subtle, localized signals of memorization, reducing attack effectiveness. We challenge this global-averaging paradigm, positing that membership signals are more pronounced within localized contexts. We introduce WBC (Window-Based Comparison), which exploits this insight through a sliding window approach with sign-based aggregation. Our method slides windows of varying sizes across text sequences, with each window casting a binary vote on membership based on loss comparisons between target and reference models. By ensembling votes across geometrically spaced window sizes, we capture memorization patterns from token-level artifacts to phrase-level structures. Extensive experiments across eleven datasets demonstrate that WBC substantially outperforms established baselines, achieving higher AUC scores and 2-3 times improvements in detection rates at low false positive thresholds. Our findings reveal that aggregating localized evidence is fundamentally more effective than global averaging, exposing critical privacy vulnerabilities in fine-tuned LLMs.
M3MAD-Bench: Are Multi-Agent Debates Really Effective Across Domains and Modalities?
Jan 06, 2026As an agent-level reasoning and coordination paradigm, Multi-Agent Debate (MAD) orchestrates multiple agents through structured debate to improve answer quality and support complex reasoning. However, existing research on MAD suffers from two fundamental limitations: evaluations are conducted under fragmented and inconsistent settings, hindering fair comparison, and are largely restricted to single-modality scenarios that rely on textual inputs only. To address these gaps, we introduce M3MAD-Bench, a unified and extensible benchmark for evaluating MAD methods across Multi-domain tasks, Multi-modal inputs, and Multi-dimensional metrics. M3MAD-Bench establishes standardized protocols over five core task domains: Knowledge, Mathematics, Medicine, Natural Sciences, and Complex Reasoning, and systematically covers both pure text and vision-language datasets, enabling controlled cross-modality comparison. We evaluate MAD methods on nine base models spanning different architectures, scales, and modality capabilities. Beyond accuracy, M3MAD-Bench incorporates efficiency-oriented metrics such as token consumption and inference time, providing a holistic view of performance--cost trade-offs. Extensive experiments yield systematic insights into the effectiveness, robustness, and efficiency of MAD across text-only and multimodal scenarios. We believe M3MAD-Bench offers a reliable foundation for future research on standardized MAD evaluation. The code is available at http://github.com/liaolea/M3MAD-Bench.
KORE: Enhancing Knowledge Injection for Large Multimodal Models via Knowledge-Oriented Augmentations and Constraints
Oct 22, 2025Large Multimodal Models encode extensive factual knowledge in their pre-trained weights. However, its knowledge remains static and limited, unable to keep pace with real-world developments, which hinders continuous knowledge acquisition. Effective knowledge injection thus becomes critical, involving two goals: knowledge adaptation (injecting new knowledge) and knowledge retention (preserving old knowledge). Existing methods often struggle to learn new knowledge and suffer from catastrophic forgetting. To address this, we propose KORE, a synergistic method of KnOwledge-oRientEd augmentations and constraints for injecting new knowledge into large multimodal models while preserving old knowledge. Unlike general text or image data augmentation, KORE automatically converts individual knowledge items into structured and comprehensive knowledge to ensure that the model accurately learns new knowledge, enabling accurate adaptation. Meanwhile, KORE stores previous knowledge in the covariance matrix of LMM's linear layer activations and initializes the adapter by projecting the original weights into the matrix's null space, defining a fine-tuning direction that minimizes interference with previous knowledge, enabling powerful retention. Extensive experiments on various LMMs, including LLaVA-v1.5-7B, LLaVA-v1.5-13B, and Qwen2.5-VL-7B, show that KORE achieves superior new knowledge injection performance and effectively mitigates catastrophic forgetting.
GitTaskBench: A Benchmark for Code Agents Solving Real-World Tasks Through Code Repository Leveraging
Aug 26, 2025

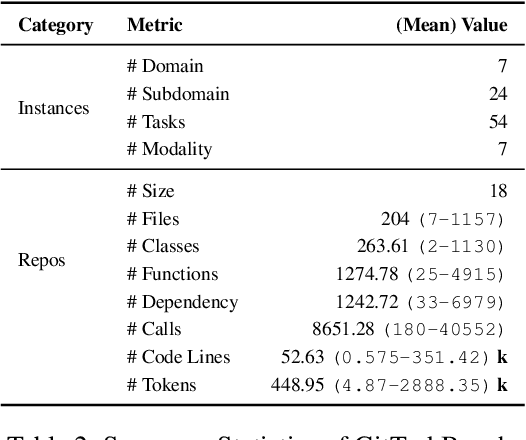
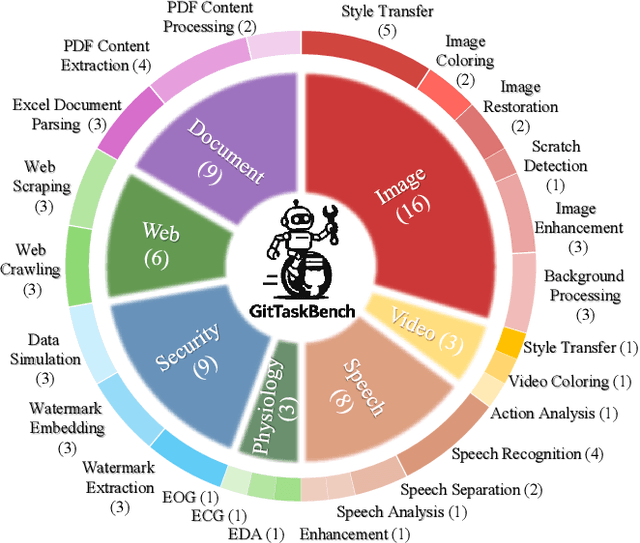
Beyond scratch coding, exploiting large-scale code repositories (e.g., GitHub) for practical tasks is vital in real-world software development, yet current benchmarks rarely evaluate code agents in such authentic, workflow-driven scenarios. To bridge this gap, we introduce GitTaskBench, a benchmark designed to systematically assess this capability via 54 realistic tasks across 7 modalities and 7 domains. Each task pairs a relevant repository with an automated, human-curated evaluation harness specifying practical success criteria. Beyond measuring execution and task success, we also propose the alpha-value metric to quantify the economic benefit of agent performance, which integrates task success rates, token cost, and average developer salaries. Experiments across three state-of-the-art agent frameworks with multiple advanced LLMs show that leveraging code repositories for complex task solving remains challenging: even the best-performing system, OpenHands+Claude 3.7, solves only 48.15% of tasks. Error analysis attributes over half of failures to seemingly mundane yet critical steps like environment setup and dependency resolution, highlighting the need for more robust workflow management and increased timeout preparedness. By releasing GitTaskBench, we aim to drive progress and attention toward repository-aware code reasoning, execution, and deployment -- moving agents closer to solving complex, end-to-end real-world tasks. The benchmark and code are open-sourced at https://github.com/QuantaAlpha/GitTaskBench.
MV-Debate: Multi-view Agent Debate with Dynamic Reflection Gating for Multimodal Harmful Content Detection in Social Media
Aug 07, 2025Social media has evolved into a complex multimodal environment where text, images, and other signals interact to shape nuanced meanings, often concealing harmful intent. Identifying such intent, whether sarcasm, hate speech, or misinformation, remains challenging due to cross-modal contradictions, rapid cultural shifts, and subtle pragmatic cues. To address these challenges, we propose MV-Debate, a multi-view agent debate framework with dynamic reflection gating for unified multimodal harmful content detection. MV-Debate assembles four complementary debate agents, a surface analyst, a deep reasoner, a modality contrast, and a social contextualist, to analyze content from diverse interpretive perspectives. Through iterative debate and reflection, the agents refine responses under a reflection-gain criterion, ensuring both accuracy and efficiency. Experiments on three benchmark datasets demonstrate that MV-Debate significantly outperforms strong single-model and existing multi-agent debate baselines. This work highlights the promise of multi-agent debate in advancing reliable social intent detection in safety-critical online contexts.
SOFT: Selective Data Obfuscation for Protecting LLM Fine-tuning against Membership Inference Attacks
Jun 12, 2025



Large language models (LLMs) have achieved remarkable success and are widely adopted for diverse applications. However, fine-tuning these models often involves private or sensitive information, raising critical privacy concerns. In this work, we conduct the first comprehensive study evaluating the vulnerability of fine-tuned LLMs to membership inference attacks (MIAs). Our empirical analysis demonstrates that MIAs exploit the loss reduction during fine-tuning, making them highly effective in revealing membership information. These findings motivate the development of our defense. We propose SOFT (\textbf{S}elective data \textbf{O}bfuscation in LLM \textbf{F}ine-\textbf{T}uning), a novel defense technique that mitigates privacy leakage by leveraging influential data selection with an adjustable parameter to balance utility preservation and privacy protection. Our extensive experiments span six diverse domains and multiple LLM architectures and scales. Results show that SOFT effectively reduces privacy risks while maintaining competitive model performance, offering a practical and scalable solution to safeguard sensitive information in fine-tuned LLMs.
When Large Multimodal Models Confront Evolving Knowledge:Challenges and Pathways
May 30, 2025Large language/multimodal models (LLMs/LMMs) store extensive pre-trained knowledge but struggle to maintain consistency with real-world updates, making it difficult to avoid catastrophic forgetting while acquiring evolving knowledge. Previous work focused on constructing textual knowledge datasets and exploring knowledge injection in LLMs, lacking exploration of multimodal evolving knowledge injection in LMMs. To address this, we propose the EVOKE benchmark to evaluate LMMs' ability to inject multimodal evolving knowledge in real-world scenarios. Meanwhile, a comprehensive evaluation of multimodal evolving knowledge injection revealed two challenges: (1) Existing knowledge injection methods perform terribly on evolving knowledge. (2) Supervised fine-tuning causes catastrophic forgetting, particularly instruction following ability is severely compromised. Additionally, we provide pathways and find that: (1) Text knowledge augmentation during the training phase improves performance, while image augmentation cannot achieve it. (2) Continual learning methods, especially Replay and MoELoRA, effectively mitigate forgetting. Our findings indicate that current knowledge injection methods have many limitations on evolving knowledge, which motivates further research on more efficient and stable knowledge injection methods.
RepoMaster: Autonomous Exploration and Understanding of GitHub Repositories for Complex Task Solving
May 27, 2025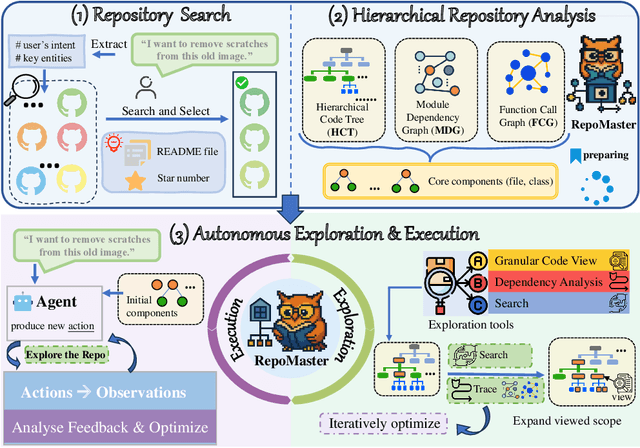
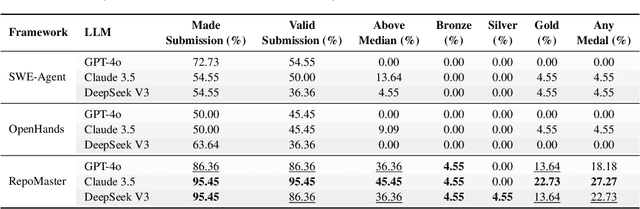
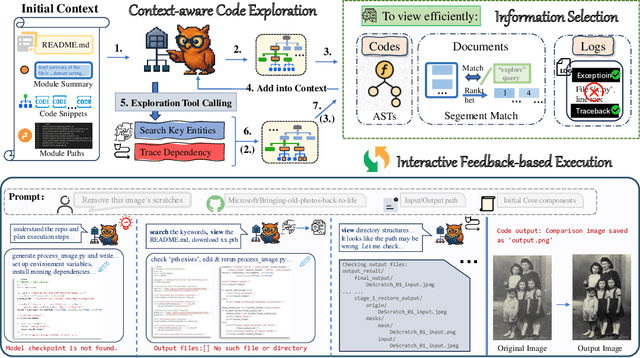
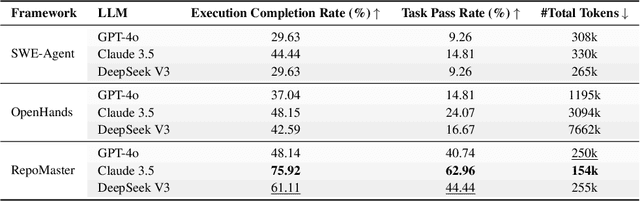
The ultimate goal of code agents is to solve complex tasks autonomously. Although large language models (LLMs) have made substantial progress in code generation, real-world tasks typically demand full-fledged code repositories rather than simple scripts. Building such repositories from scratch remains a major challenge. Fortunately, GitHub hosts a vast, evolving collection of open-source repositories, which developers frequently reuse as modular components for complex tasks. Yet, existing frameworks like OpenHands and SWE-Agent still struggle to effectively leverage these valuable resources. Relying solely on README files provides insufficient guidance, and deeper exploration reveals two core obstacles: overwhelming information and tangled dependencies of repositories, both constrained by the limited context windows of current LLMs. To tackle these issues, we propose RepoMaster, an autonomous agent framework designed to explore and reuse GitHub repositories for solving complex tasks. For efficient understanding, RepoMaster constructs function-call graphs, module-dependency graphs, and hierarchical code trees to identify essential components, providing only identified core elements to the LLMs rather than the entire repository. During autonomous execution, it progressively explores related components using our exploration tools and prunes information to optimize context usage. Evaluated on the adjusted MLE-bench, RepoMaster achieves a 110% relative boost in valid submissions over the strongest baseline OpenHands. On our newly released GitTaskBench, RepoMaster lifts the task-pass rate from 24.1% to 62.9% while reducing token usage by 95%. Our code and demonstration materials are publicly available at https://github.com/wanghuacan/RepoMaster.