 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference Attacks Against Fine-tuned Diffusion Language Models
Jan 27, 2026Diffusion Language Models (DLMs) represent a promising alternative to autoregressive language models, using bidirectional masked token prediction. Yet their susceptibility to privacy leakage via Membership Inference Attacks (MIA) remains critically underexplored. This paper presents the first systematic investigation of MIA vulnerabilities in DLMs. Unlike the autoregressive models' single fixed prediction pattern, DLMs' multiple maskable configurations exponentially increase attack opportunities. This ability to probe many independent masks dramatically improves detection chances. To exploit this, we introduce SAMA (Subset-Aggregated Membership Attack), which addresses the sparse signal challenge through robust aggregation. SAMA samples masked subsets across progressive densities and applies sign-based statistics that remain effective despite heavy-tailed noise. Through inverse-weighted aggregation prioritizing sparse masks' cleaner signals, SAMA transforms sparse memorization detection into a robust voting mechanism. Experiments on nine datasets show SAMA achieves 30% relative AUC improvement over the best baseline, with up to 8 times improvement at low false positive rates. These findings reveal significant, previously unknown vulnerabilities in DLMs, necessitating the development of tailored privacy defenses.
Window-based Membership Inference Attacks Against Fine-tuned Large Language Models
Jan 06, 2026Most membership inference attacks (MIAs) against Large Language Models (LLMs) rely on global signals, like average loss, to identify training data. This approach, however, dilutes the subtle, localized signals of memorization, reducing attack effectiveness. We challenge this global-averaging paradigm, positing that membership signals are more pronounced within localized contexts. We introduce WBC (Window-Based Comparison), which exploits this insight through a sliding window approach with sign-based aggregation. Our method slides windows of varying sizes across text sequences, with each window casting a binary vote on membership based on loss comparisons between target and reference models. By ensembling votes across geometrically spaced window sizes, we capture memorization patterns from token-level artifacts to phrase-level structures. Extensive experiments across eleven datasets demonstrate that WBC substantially outperforms established baselines, achieving higher AUC scores and 2-3 times improvements in detection rates at low false positive thresholds. Our findings reveal that aggregating localized evidence is fundamentally more effective than global averaging, exposing critical privacy vulnerabilities in fine-tuned LLMs.
SOFT: Selective Data Obfuscation for Protecting LLM Fine-tuning against Membership Inference Attacks
Jun 12, 2025



Large language models (LLMs) have achieved remarkable success and are widely adopted for diverse applications. However, fine-tuning these models often involves private or sensitive information, raising critical privacy concerns. In this work, we conduct the first comprehensive study evaluating the vulnerability of fine-tuned LLMs to membership inference attacks (MIAs). Our empirical analysis demonstrates that MIAs exploit the loss reduction during fine-tuning, making them highly effective in revealing membership information. These findings motivate the development of our defense. We propose SOFT (\textbf{S}elective data \textbf{O}bfuscation in LLM \textbf{F}ine-\textbf{T}uning), a novel defense technique that mitigates privacy leakage by leveraging influential data selection with an adjustable parameter to balance utility preservation and privacy protection. Our extensive experiments span six diverse domains and multiple LLM architectures and scales. Results show that SOFT effectively reduces privacy risks while maintaining competitive model performance, offering a practical and scalable solution to safeguard sensitive information in fine-tuned LLMs.
Enhancing Sentiment Analysis Results through Outlier Detection Optimization
Nov 25, 2023When dealing with text data containing subjective labels like speaker emotions, inaccuracies or discrepancies among labelers are not uncommon. Such discrepancies can significantly affect the performance of machine learning algorithms. This study investigates the potential of identifying and addressing outliers in text data with subjective labels, aiming to enhance classification outcomes. We utilized the Deep SVDD algorithm, a one-class classification method, to detect outliers in nine text-based emotion and sentiment analysis datasets. By employing both a small-sized language model (DistilBERT base model with 66 million parameters) and non-deep learning machine learning algorithms (decision tree, KNN, Logistic Regression, and LDA) as the classifier, our findings suggest that the removal of outliers can lead to enhanced results in most cases. Additionally, as outliers in such datasets are not necessarily unlearnable, we experienced utilizing a large language model -- DeBERTa v3 large with 131 million parameters, which can capture very complex patterns in data. We continued to observe performance enhancements across multiple datasets.
Prompt to GPT-3: Step-by-Step Thinking Instructions for Humor Generation
Jun 22, 2023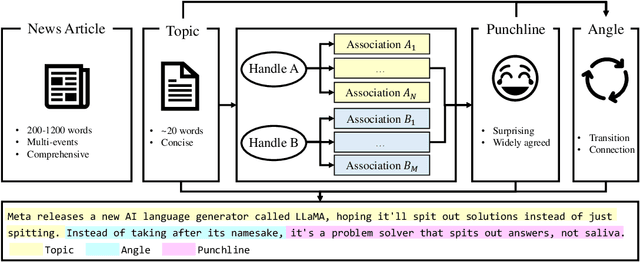
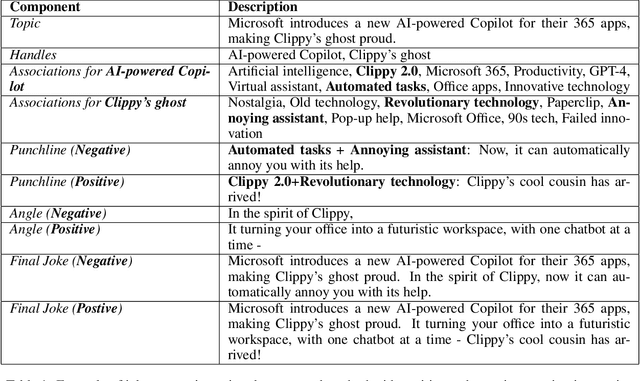
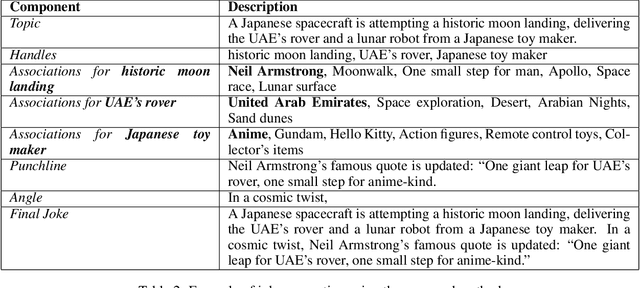
Artificial intelligence has made significant progress in natural language processing, with models like GPT-3 demonstrating impressive capabilities. However, these models still have limitations when it comes to complex tasks that require an understanding of the user, such as mastering human comedy writing strategies. This paper explores humor generation using GPT-3 by modeling human comedy writing theory and leveraging step-by-step thinking instructions. In addition, we explore the role of cognitive distance in creating humor.
Visual Story Generation Based on Emotion and Keywords
Jan 07, 2023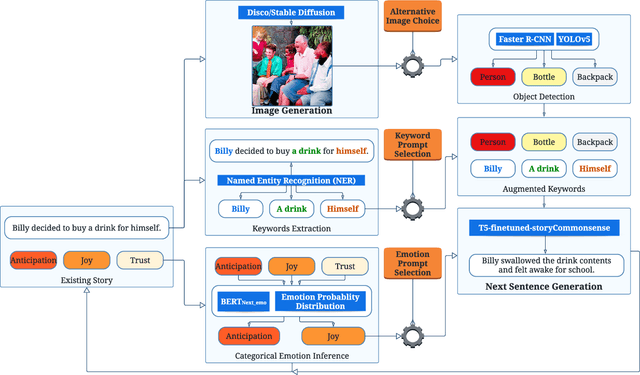

Automated visual story generation aims to produce stories with corresponding illustrations that exhibit coherence, progression, and adherence to characters' emotional development. This work proposes a story generation pipeline to co-create visual stories with the users. The pipeline allows the user to control events and emotions on the generated content. The pipeline includes two parts: narrative and image generation. For narrative generation, the system generates the next sentence using user-specified keywords and emotion labels. For image generation, diffusion models are used to create a visually appealing image corresponding to each generated sentence. Further, object recognition is applied to the generated images to allow objects in these images to be mentioned in future story development.