 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASTRA: Autonomous Spatial-Temporal Red-teaming for AI Software Assistants
Aug 05, 2025AI coding assistants like GitHub Copilot are rapidly transforming software development, but their safety remains deeply uncertain-especially in high-stakes domains like cybersecurity. Current red-teaming tools often rely on fixed benchmarks or unrealistic prompts, missing many real-world vulnerabilities. We present ASTRA, an automated agent system designed to systematically uncover safety flaws in AI-driven code generation and security guidance systems. ASTRA works in three stages: (1) it builds structured domain-specific knowledge graphs that model complex software tasks and known weaknesses; (2) it performs online vulnerability exploration of each target model by adaptively probing both its input space, i.e., the spatial exploration, and its reasoning processes, i.e., the temporal exploration, guided by the knowledge graphs; and (3) it generates high-quality violation-inducing cases to improve model alignment. Unlike prior methods, ASTRA focuses on realistic inputs-requests that developers might actually ask-and uses both offline abstraction guided domain modeling and online domain knowledge graph adaptation to surface corner-case vulnerabilities. Across two major evaluation domains, ASTRA finds 11-66% more issues than existing techniques and produces test cases that lead to 17% more effective alignment training, showing its practical value for building safer AI systems.
SOFT: Selective Data Obfuscation for Protecting LLM Fine-tuning against Membership Inference Attacks
Jun 12, 2025



Large language models (LLMs) have achieved remarkable success and are widely adopted for diverse applications. However, fine-tuning these models often involves private or sensitive information, raising critical privacy concerns. In this work, we conduct the first comprehensive study evaluating the vulnerability of fine-tuned LLMs to membership inference attacks (MIAs). Our empirical analysis demonstrates that MIAs exploit the loss reduction during fine-tuning, making them highly effective in revealing membership information. These findings motivate the development of our defense. We propose SOFT (\textbf{S}elective data \textbf{O}bfuscation in LLM \textbf{F}ine-\textbf{T}uning), a novel defense technique that mitigates privacy leakage by leveraging influential data selection with an adjustable parameter to balance utility preservation and privacy protection. Our extensive experiments span six diverse domains and multiple LLM architectures and scales. Results show that SOFT effectively reduces privacy risks while maintaining competitive model performance, offering a practical and scalable solution to safeguard sensitive information in fine-tuned LLMs.
IntenTest: Stress Testing for Intent Integrity in API-Calling LLM Agents
Jun 09, 2025LLM agents are increasingly deployed to automate real-world tasks by invoking APIs through natural language instructions. While powerful, they often suffer from misinterpretation of user intent, leading to the agent's actions that diverge from the user's intended goal, especially as external toolkits evolve. Traditional software testing assumes structured inputs and thus falls short in handling the ambiguity of natural language. We introduce IntenTest, an API-centric stress testing framework that systematically uncovers intent integrity violations in LLM agents. Unlike prior work focused on fixed benchmarks or adversarial inputs, IntenTest generates realistic tasks based on toolkits' documentation and applies targeted mutations to expose subtle agent errors while preserving user intent. To guide testing, we propose semantic partitioning, which organizes natural language tasks into meaningful categories based on toolkit API parameters and their equivalence classes. Within each partition, seed tasks are mutated and ranked by a lightweight predictor that estimates the likelihood of triggering agent errors. To enhance efficiency, IntenTest maintains a datatype-aware strategy memory that retrieves and adapts effective mutation patterns from past cases. Experiments on 80 toolkit APIs demonstrate that IntenTest effectively uncovers intent integrity violations, significantly outperforming baselines in both error-exposing rate and query efficiency. Moreover, IntenTest generalizes well to stronger target models using smaller LLMs for test generation, and adapts to evolving APIs across domains.
LLM Agents Should Employ Security Principles
May 29, 2025Large Language Model (LLM) agents show considerable promise for automating complex tasks using contextual reasoning; however, interactions involving multiple agents and the system's susceptibility to prompt injection and other forms of context manipulation introduce new vulnerabilities related to privacy leakage and system exploitation. This position paper argues that the well-established design principles in information security, which are commonly referred to as security principles, should be employed when deploying LLM agents at scale. Design principles such as defense-in-depth, least privilege, complete mediation, and psychological acceptability have helped guide the design of mechanisms for securing information systems over the last five decades, and we argue that their explicit and conscientious adoption will help secure agentic systems. To illustrate this approach, we introduce AgentSandbox, a conceptual framework embedding these security principles to provide safeguards throughout an agent's life-cycle. We evaluate with state-of-the-art LLMs along three dimensions: benign utility, attack utility, and attack success rate. AgentSandbox maintains high utility for its intended functions under both benign and adversarial evaluations while substantially mitigating privacy risks. By embedding secure design principles as foundational elements within emerging LLM agent protocols, we aim to promote trustworthy agent ecosystems aligned with user privacy expectations and evolving regulatory requirements.
$μ$KE: Matryoshka Unstructured Knowledge Editing of Large Language Models
Apr 01, 2025



Large language models (LLMs) have emerged as powerful knowledge bases yet are limited by static training data, leading to issues such as hallucinations and safety risks. Editing a model's internal knowledge through the locate-and-edit paradigm has proven a cost-effective alternative to retraining, though current unstructured approaches, especially window-based autoregressive methods, often disrupt the causal dependency between early memory updates and later output tokens. In this work, we first theoretically analyze these limitations and then introduce Matryoshka Unstructured Knowledge Editing ($\mu$KE), a novel memory update mechanism that preserves such dependencies via a Matryoshka-style objective and adaptive loss coefficients. Empirical evaluations on two models across four benchmarks demonstrate that $\mu$KE improves edit efficacy by up to 12.33% over state-of-the-art methods, and remain robust when applied to diverse formatted edits, underscoring its potential for effective unstructured knowledge editing in LLMs.
ProSec: Fortifying Code LLMs with Proactive Security Alignment
Nov 19, 2024



Recent advances in code-specific large language models (LLMs) have greatly enhanced code generation and refinement capabilities. However, the safety of code LLMs remains under-explored, posing potential risks as insecure code generated by these models may introduce vulnerabilities into real-world systems. Previous work proposes to collect security-focused instruction-tuning dataset from real-world vulnerabilities. It is constrained by the data sparsity of vulnerable code, and has limited applicability in the iterative post-training workflows of modern LLMs. In this paper, we propose ProSec, a novel proactive security alignment approach designed to align code LLMs with secure coding practices. ProSec systematically exposes the vulnerabilities in a code LLM by synthesizing error-inducing coding scenarios from Common Weakness Enumerations (CWEs), and generates fixes to vulnerable code snippets, allowing the model to learn secure practices through advanced preference learning objectives. The scenarios synthesized by ProSec triggers 25 times more vulnerable code than a normal instruction-tuning dataset, resulting in a security-focused alignment dataset 7 times larger than the previous work. Experiments show that models trained with ProSec is 29.2% to 35.5% more secure compared to previous work, with a marginal negative effect of less than 2 percentage points on model's utility.
Source Code Foundation Models are Transferable Binary Analysis Knowledge Bases
May 30, 2024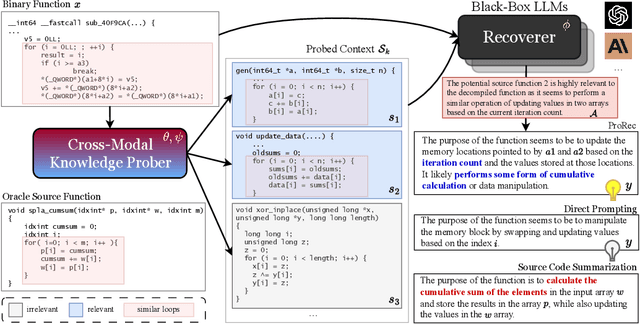
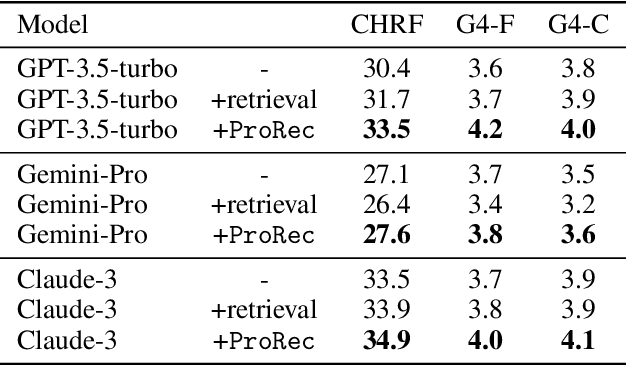
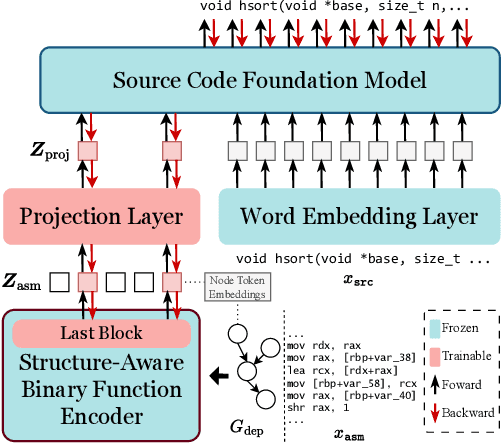
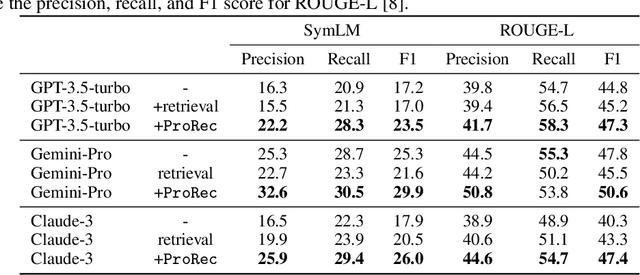
Human-Oriented Binary Reverse Engineering (HOBRE) lies at the intersection of binary and source code, aiming to lift binary code to human-readable content relevant to source code, thereby bridging the binary-source semantic gap. Recent advancements in uni-modal code model pre-training, particularly in generative Source Code Foundation Models (SCFMs) and binary understanding models, have laid the groundwork for transfer learning applicable to HOBRE. However, existing approaches for HOBRE rely heavily on uni-modal models like SCFMs for supervised fine-tuning or general LLMs for prompting, resulting in sub-optimal performance. Inspired by recent progress in large multi-modal models, we propose that it is possible to harness the strengths of uni-modal code models from both sides to bridge the semantic gap effectively. In this paper, we introduce a novel probe-and-recover framework that incorporates a binary-source encoder-decoder model and black-box LLMs for binary analysis. Our approach leverages the pre-trained knowledge within SCFMs to synthesize relevant, symbol-rich code fragments as context. This additional context enables black-box LLMs to enhance recovery accuracy. We demonstrate significant improvements in zero-shot binary summarization and binary function name recovery, with a 10.3% relative gain in CHRF and a 16.7% relative gain in a GPT4-based metric for summarization, as well as a 6.7% and 7.4% absolute increase in token-level precision and recall for name recovery, respectively. These results highlight the effectiveness of our approach in automating and improving binary code analysis.
CodeArt: Better Code Models by Attention Regularization When Symbols Are Lacking
Feb 19, 2024



Transformer based code models have impressive performance in many software engineering tasks. However, their effectiveness degrades when symbols are missing or not informative. The reason is that the model may not learn to pay attention to the right correlations/contexts without the help of symbols. We propose a new method to pre-train general code models when symbols are lacking. We observe that in such cases, programs degenerate to something written in a very primitive language. We hence propose to use program analysis to extract contexts a priori (instead of relying on symbols and masked language modeling as in vanilla models). We then leverage a novel attention masking method to only allow the model attending to these contexts, e.g., bi-directional program dependence transitive closures and token co-occurrences. In the meantime, the inherent self-attention mechanism is utilized to learn which of the allowed attentions are more important compared to others. To realize the idea, we enhance the vanilla tokenization and model architecture of a BERT model, construct and utilize attention masks, and introduce a new pre-training algorithm. We pre-train this BERT-like model from scratch, using a dataset of 26 million stripped binary functions with explicit program dependence information extracted by our tool. We apply the model in three downstream tasks: binary similarity, type inference, and malware family classification. Our pre-trained model can improve the SOTAs in these tasks from 53% to 64%, 49% to 60%, and 74% to 94%, respectively. It also substantially outperforms other general pre-training techniques of code understanding models.
When Dataflow Analysis Meets Large Language Models
Feb 16, 2024


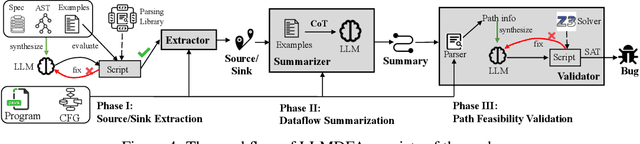
Dataflow analysis is a powerful code analysis technique that reasons dependencies between program values, offering support for code optimization, program comprehension, and bug detection. Existing approaches require the successful compilation of the subject program and customizations for downstream applications. This paper introduces LLMDFA, an LLM-powered dataflow analysis framework that analyzes arbitrary code snippets without requiring a compilation infrastructure and automatically synthesizes downstream applications. Inspired by summary-based dataflow analysis, LLMDFA decomposes the problem into three sub-problems, which are effectively resolved by several essential strategies, including few-shot chain-of-thought prompting and tool synthesis. Our evaluation has shown that the design can mitigate the hallucination and improve the reasoning ability, obtaining high precision and recall in detecting dataflow-related bugs upon benchmark programs, outperforming state-of-the-art (classic) tools, including a very recent industrial analyzer.