 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoVerifier: An Agentic Automated Verification Framework Using Large Language Models
Apr 03, 2026Scientific and Technical Intelligence (S&TI) analysis requires verifying complex technical claims across rapidly growing literature, where existing approaches fail to bridge the verification gap between surface-level accuracy and deeper methodological validity. We present AutoVerifier, an LLM-based agentic framework that automates end-to-end verification of technical claims without requiring domain expertise. AutoVerifier decomposes every technical assertion into structured claim triples of the form (Subject, Predicate, Object), constructing knowledge graphs that enable structured reasoning across six progressively enriching layers: corpus construction and ingestion, entity and claim extraction, intra-document verification, cross-source verification, external signal corroboration, and final hypothesis matrix generation. We demonstrate AutoVerifier on a contested quantum computing claim, where the framework, operated by analysts with no quantum expertise, automatically identified overclaims and metric inconsistencies within the target paper, traced cross-source contradictions, uncovered undisclosed commercial conflicts of interest, and produced a final assessment. These results show that structured LLM verification can reliably evaluate the validity and maturity of emerging technologies, turning raw technical documents into traceable, evidence-backed intelligence assessments.
Security Considerations for Artificial Intelligence Agents
Mar 12, 2026This article, a lightly adapted version of Perplexity's response to NIST/CAISI Request for Information 2025-0035, details our observations and recommendations concerning the security of frontier AI agents. These insights are informed by Perplexity's experience operating general-purpose agentic systems used by millions of users and thousands of enterprises in both controlled and open-world environments. Agent architectures change core assumptions around code-data separation, authority boundaries, and execution predictability, creating new confidentiality, integrity, and availability failure modes. We map principal attack surfaces across tools, connectors, hosting boundaries, and multi-agent coordination, with particular emphasis on indirect prompt injection, confused-deputy behavior, and cascading failures in long-running workflows. We then assess current defenses as a layered stack: input-level and model-level mitigations, sandboxed execution, and deterministic policy enforcement for high-consequence actions. Finally, we identify standards and research gaps, including adaptive security benchmarks, policy models for delegation and privilege control, and guidance for secure multi-agent system design aligned with NIST risk management principles.
Membership Inference Attacks Against Fine-tuned Diffusion Language Models
Jan 27, 2026Diffusion Language Models (DLMs) represent a promising alternative to autoregressive language models, using bidirectional masked token prediction. Yet their susceptibility to privacy leakage via Membership Inference Attacks (MIA) remains critically underexplored. This paper presents the first systematic investigation of MIA vulnerabilities in DLMs. Unlike the autoregressive models' single fixed prediction pattern, DLMs' multiple maskable configurations exponentially increase attack opportunities. This ability to probe many independent masks dramatically improves detection chances. To exploit this, we introduce SAMA (Subset-Aggregated Membership Attack), which addresses the sparse signal challenge through robust aggregation. SAMA samples masked subsets across progressive densities and applies sign-based statistics that remain effective despite heavy-tailed noise. Through inverse-weighted aggregation prioritizing sparse masks' cleaner signals, SAMA transforms sparse memorization detection into a robust voting mechanism. Experiments on nine datasets show SAMA achieves 30% relative AUC improvement over the best baseline, with up to 8 times improvement at low false positive rates. These findings reveal significant, previously unknown vulnerabilities in DLMs, necessitating the development of tailored privacy defenses.
Window-based Membership Inference Attacks Against Fine-tuned Large Language Models
Jan 06, 2026Most membership inference attacks (MIAs) against Large Language Models (LLMs) rely on global signals, like average loss, to identify training data. This approach, however, dilutes the subtle, localized signals of memorization, reducing attack effectiveness. We challenge this global-averaging paradigm, positing that membership signals are more pronounced within localized contexts. We introduce WBC (Window-Based Comparison), which exploits this insight through a sliding window approach with sign-based aggregation. Our method slides windows of varying sizes across text sequences, with each window casting a binary vote on membership based on loss comparisons between target and reference models. By ensembling votes across geometrically spaced window sizes, we capture memorization patterns from token-level artifacts to phrase-level structures. Extensive experiments across eleven datasets demonstrate that WBC substantially outperforms established baselines, achieving higher AUC scores and 2-3 times improvements in detection rates at low false positive thresholds. Our findings reveal that aggregating localized evidence is fundamentally more effective than global averaging, exposing critical privacy vulnerabilities in fine-tuned LLMs.
SOFT: Selective Data Obfuscation for Protecting LLM Fine-tuning against Membership Inference Attacks
Jun 12, 2025



Large language models (LLMs) have achieved remarkable success and are widely adopted for diverse applications. However, fine-tuning these models often involves private or sensitive information, raising critical privacy concerns. In this work, we conduct the first comprehensive study evaluating the vulnerability of fine-tuned LLMs to membership inference attacks (MIAs). Our empirical analysis demonstrates that MIAs exploit the loss reduction during fine-tuning, making them highly effective in revealing membership information. These findings motivate the development of our defense. We propose SOFT (\textbf{S}elective data \textbf{O}bfuscation in LLM \textbf{F}ine-\textbf{T}uning), a novel defense technique that mitigates privacy leakage by leveraging influential data selection with an adjustable parameter to balance utility preservation and privacy protection. Our extensive experiments span six diverse domains and multiple LLM architectures and scales. Results show that SOFT effectively reduces privacy risks while maintaining competitive model performance, offering a practical and scalable solution to safeguard sensitive information in fine-tuned LLMs.
LLM Agents Should Employ Security Principles
May 29, 2025Large Language Model (LLM) agents show considerable promise for automating complex tasks using contextual reasoning; however, interactions involving multiple agents and the system's susceptibility to prompt injection and other forms of context manipulation introduce new vulnerabilities related to privacy leakage and system exploitation. This position paper argues that the well-established design principles in information security, which are commonly referred to as security principles, should be employed when deploying LLM agents at scale. Design principles such as defense-in-depth, least privilege, complete mediation, and psychological acceptability have helped guide the design of mechanisms for securing information systems over the last five decades, and we argue that their explicit and conscientious adoption will help secure agentic systems. To illustrate this approach, we introduce AgentSandbox, a conceptual framework embedding these security principles to provide safeguards throughout an agent's life-cycle. We evaluate with state-of-the-art LLMs along three dimensions: benign utility, attack utility, and attack success rate. AgentSandbox maintains high utility for its intended functions under both benign and adversarial evaluations while substantially mitigating privacy risks. By embedding secure design principles as foundational elements within emerging LLM agent protocols, we aim to promote trustworthy agent ecosystems aligned with user privacy expectations and evolving regulatory requirements.
CENSOR: Defense Against Gradient Inversion via Orthogonal Subspace Bayesian Sampling
Jan 27, 2025



Federated learning collaboratively trains a neural network on a global server, where each local client receives the current global model weights and sends back parameter updates (gradients) based on its local private data. The process of sending these model updates may leak client's private data information. Existing gradient inversion attacks can exploit this vulnerability to recover private training instances from a client's gradient vectors. Recently, researchers have proposed advanced gradient inversion techniques that existing defenses struggle to handle effectively. In this work, we present a novel defense tailored for large neural network models. Our defense capitalizes on the high dimensionality of the model parameters to perturb gradients within a subspace orthogonal to the original gradient. By leveraging cold posteriors over orthogonal subspaces, our defense implements a refined gradient update mechanism. This enables the selection of an optimal gradient that not only safeguards against gradient inversion attacks but also maintains model utility. We conduct comprehensive experiments across three different datasets and evaluate our defense against various state-of-the-art attacks and defenses. Code is available at https://censor-gradient.github.io.
Federated Learning Privacy: Attacks, Defenses, Applications, and Policy Landscape - A Survey
May 06, 2024Deep learning has shown incredible potential across a vast array of tasks and accompanying this growth has been an insatiable appetite for data. However, a large amount of data needed for enabling deep learning is stored on personal devices and recent concerns on privacy have further highlighted challenges for accessing such data. As a result, federated learning (FL) has emerged as an important privacy-preserving technology enabling collaborative training of machine learning models without the need to send the raw, potentially sensitive, data to a central server. However, the fundamental premise that sending model updates to a server is privacy-preserving only holds if the updates cannot be "reverse engineered" to infer information about the private training data. It has been shown under a wide variety of settings that this premise for privacy does {\em not} hold. In this survey paper, we provide a comprehensive literature review of the different privacy attacks and defense methods in FL. We identify the current limitations of these attacks and highlight the settings in which FL client privacy can be broken. We dissect some of the successful industry applications of FL and draw lessons for future successful adoption. We survey the emerging landscape of privacy regulation for FL. We conclude with future directions for taking FL toward the cherished goal of generating accurate models while preserving the privacy of the data from its participants.
Towards Principled Assessment of Tabular Data Synthesis Algorithms
Feb 09, 2024
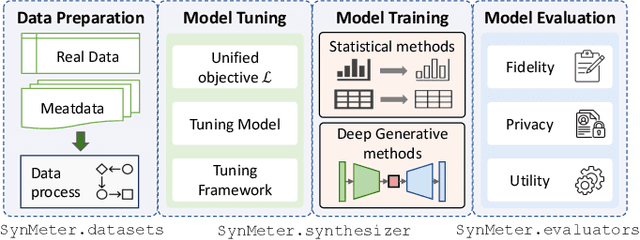
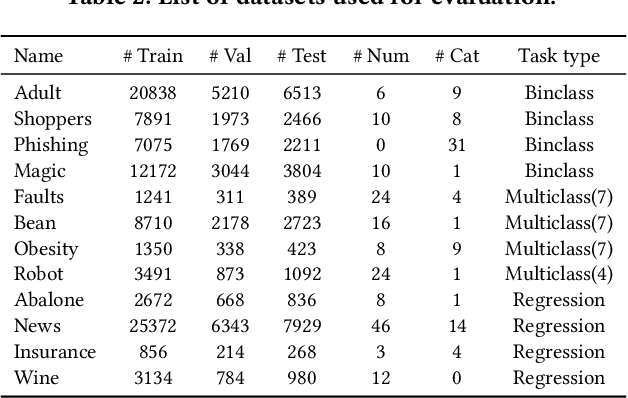

Data synthesis has been advocated as an important approach for utilizing data while protecting data privacy. A large number of tabular data synthesis algorithms (which we call synthesizers) have been proposed. Some synthesizers satisfy Differential Privacy, while others aim to provide privacy in a heuristic fashion. A comprehensive understanding of the strengths and weaknesses of these synthesizers remains elusive due to lacking principled evaluation metrics and missing head-to-head comparisons of newly developed synthesizers that take advantage of diffusion models and large language models with state-of-the-art marginal-based synthesizers. In this paper, we present a principled and systematic evaluation framework for assessing tabular data synthesis algorithms. Specifically, we examine and critique existing evaluation metrics, and introduce a set of new metrics in terms of fidelity, privacy, and utility to address their limitations. Based on the proposed metrics, we also devise a unified objective for tuning, which can consistently improve the quality of synthetic data for all methods. We conducted extensive evaluations of 8 different types of synthesizers on 12 datasets and identified some interesting findings, which offer new directions for privacy-preserving data synthesis.
MIST: Defending Against Membership Inference Attacks Through Membership-Invariant Subspace Training
Nov 02, 2023



In Member Inference (MI) attacks, the adversary try to determine whether an instance is used to train a machine learning (ML) model. MI attacks are a major privacy concern when using private data to train ML models. Most MI attacks in the literature take advantage of the fact that ML models are trained to fit the training data well, and thus have very low loss on training instances. Most defenses against MI attacks therefore try to make the model fit the training data less well. Doing so, however, generally results in lower accuracy. We observe that training instances have different degrees of vulnerability to MI attacks. Most instances will have low loss even when not included in training. For these instances, the model can fit them well without concerns of MI attacks. An effective defense only needs to (possibly implicitly) identify instances that are vulnerable to MI attacks and avoids overfitting them. A major challenge is how to achieve such an effect in an efficient training process. Leveraging two distinct recent advancements in representation learning: counterfactually-invariant representations and subspace learning methods, we introduce a novel Membership-Invariant Subspace Training (MIST) method to defend against MI attacks. MIST avoids overfitting the vulnerable instances without significant impact on other instances. We have conducted extensive experimental studies, comparing MIST with various other state-of-the-art (SOTA) MI defenses against several SOTA MI attacks. We find that MIST outperforms other defenses while resulting in minimal reduction in testing accuracy.