 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Release of Data Streams under both Centralized and Local Differential Privacy
May 24, 2020

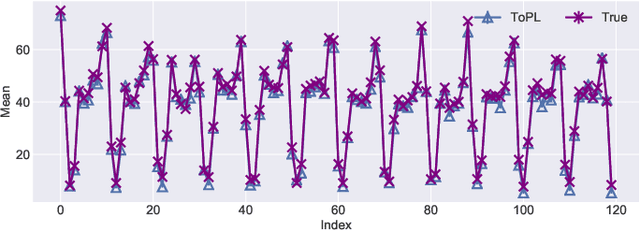
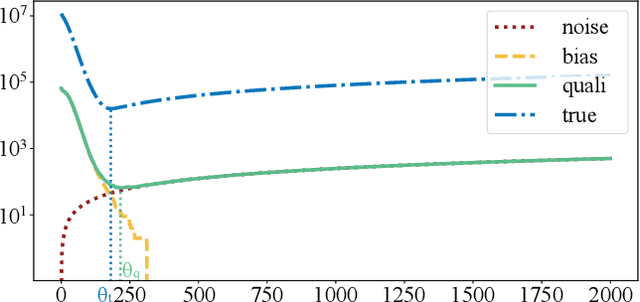
In this paper, we study the problem of publishing a stream of real-valued data satisfying differential privacy (DP). One major challenge is that the maximal possible value can be quite large; thus it is necessary to estimate a threshold so that numbers above it are truncated to reduce the amount of noise that is required to all the data. The estimation must be done based on the data in a private fashion. We develop such a method that uses the Exponential Mechanism with a quality function that approximates well the utility goal while maintaining a low sensitivity. Given the threshold, we then propose a novel online hierarchical method and several post-processing techniques. Building on these ideas, we formalize the steps into a framework for private publishing of stream data. Our framework consists of three components: a threshold optimizer that privately estimates the threshold, a perturber that adds calibrated noises to the stream, and a smoother that improves the result using post-processing. Within our framework, we design an algorithm satisfying the more stringent setting of DP called local DP (LDP). To our knowledge, this is the first LDP algorithm for publishing streaming data. Using four real-world datasets, we demonstrate that our mechanism outperforms the state-of-the-art by a factor of 6-10 orders of magnitude in terms of utility (measured by the mean squared error of answering a random range query).
Reaching Data Confidentiality and Model Accountability on the CalTrain
Dec 07, 2018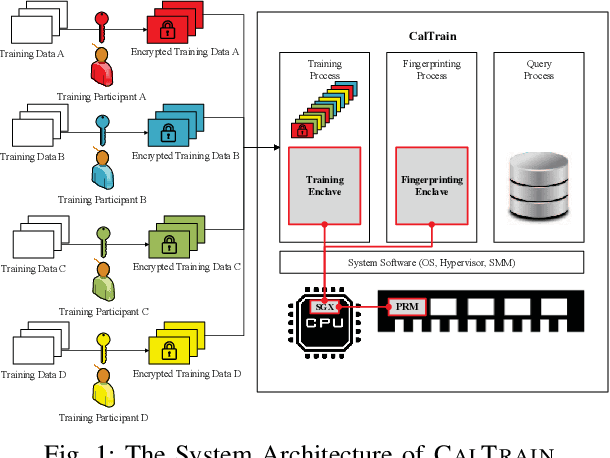
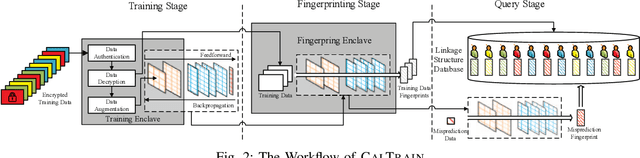

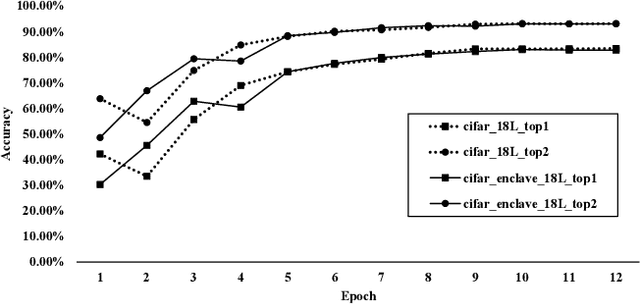
Distributed collaborative learning (DCL) paradigms enable building joint machine learning models from distrusting multi-party participants. Data confidentiality is guaranteed by retaining private training data on each participant's local infrastructure. However, this approach to achieving data confidentiality makes today's DCL designs fundamentally vulnerable to data poisoning and backdoor attacks. It also limits DCL's model accountability, which is key to backtracking the responsible "bad" training data instances/contributors. In this paper, we introduce CALTRAIN, a Trusted Execution Environment (TEE) based centralized multi-party collaborative learning system that simultaneously achieves data confidentiality and model accountability. CALTRAIN enforces isolated computation on centrally aggregated training data to guarantee data confidentiality. To support building accountable learning models, we securely maintain the links between training instances and their corresponding contributors. Our evaluation shows that the models generated from CALTRAIN can achieve the same prediction accuracy when compared to the models trained in non-protected environments. We also demonstrate that when malicious training participants tend to implant backdoors during model training, CALTRAIN can accurately and precisely discover the poisoned and mislabeled training data that lead to the runtime mispredictions.
Defending Against Model Stealing Attacks Using Deceptive Perturbations
Sep 19, 2018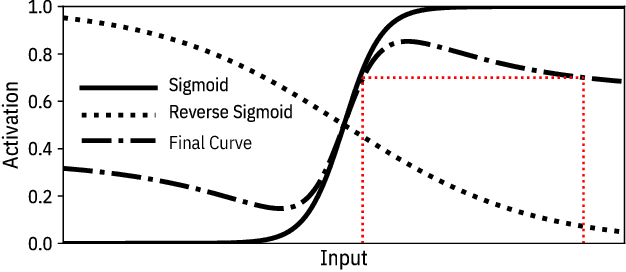
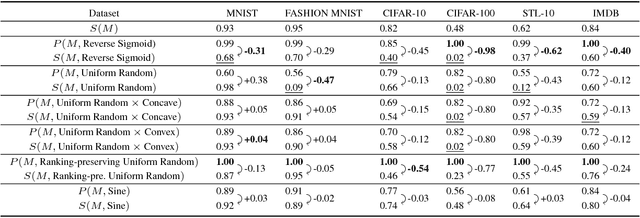
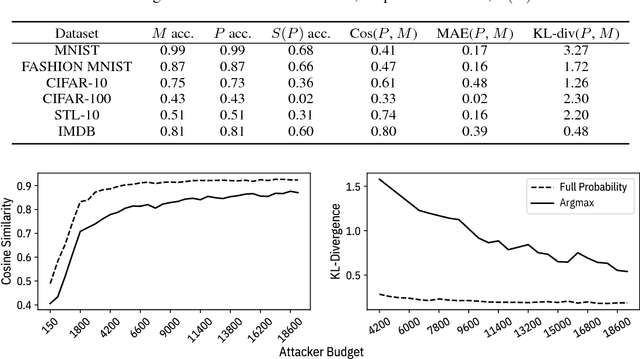
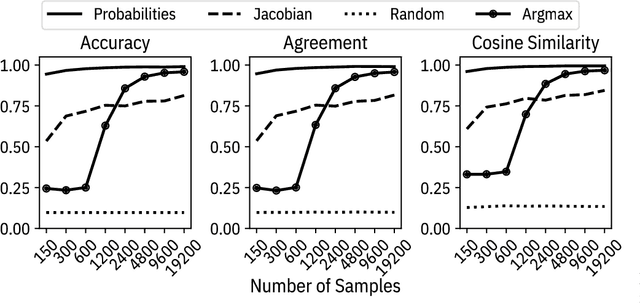
Machine learning models are vulnerable to simple model stealing attacks if the adversary can obtain output labels for chosen inputs. To protect against these attacks, it has been proposed to limit the information provided to the adversary by omitting probability scores, significantly impacting the utility of the provided service. In this work, we illustrate how a service provider can still provide useful, albeit misleading, class probability information, while significantly limiting the success of the attack. Our defense forces the adversary to discard the class probabilities, requiring significantly more queries before they can train a model with comparable performance. We evaluate several attack strategies, model architectures, and hyperparameters under varying adversarial models, and evaluate the efficacy of our defense against the strongest adversary. Finally, we quantify the amount of noise injected into the class probabilities to mesure the loss in utility, e.g., adding 1.26 nats per query on CIFAR-10 and 3.27 on MNIST. Our evaluation shows our defense can degrade the accuracy of the stolen model at least 20%, or require up to 64 times more queries while keeping the accuracy of the protected model almost intact.
Is Robustness the Cost of Accuracy? -- A Comprehensive Study on the Robustness of 18 Deep Image Classification Models
Aug 05, 2018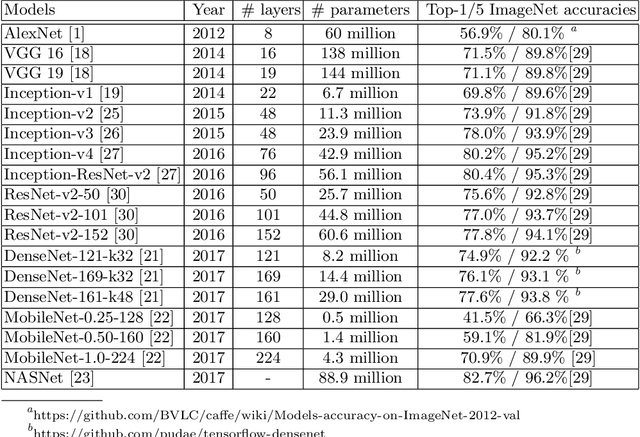
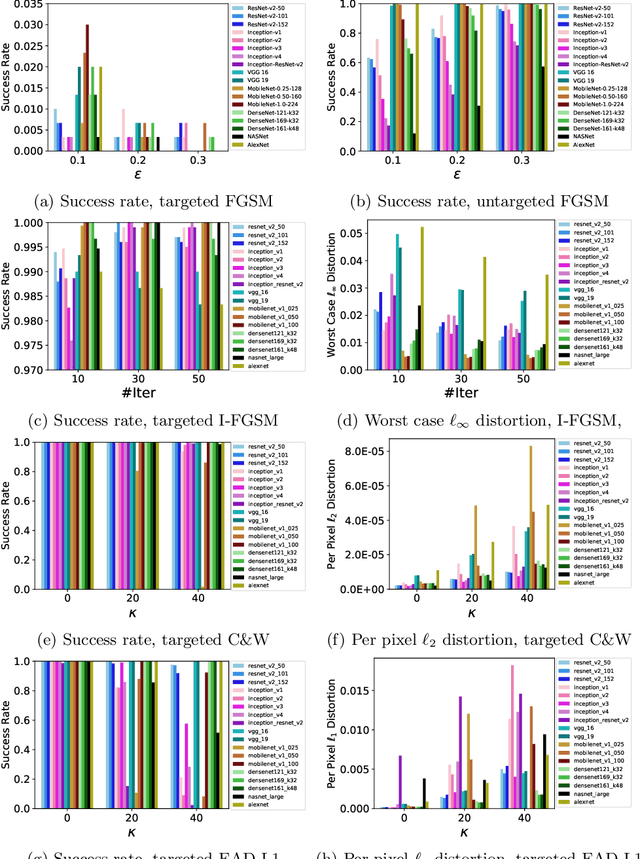
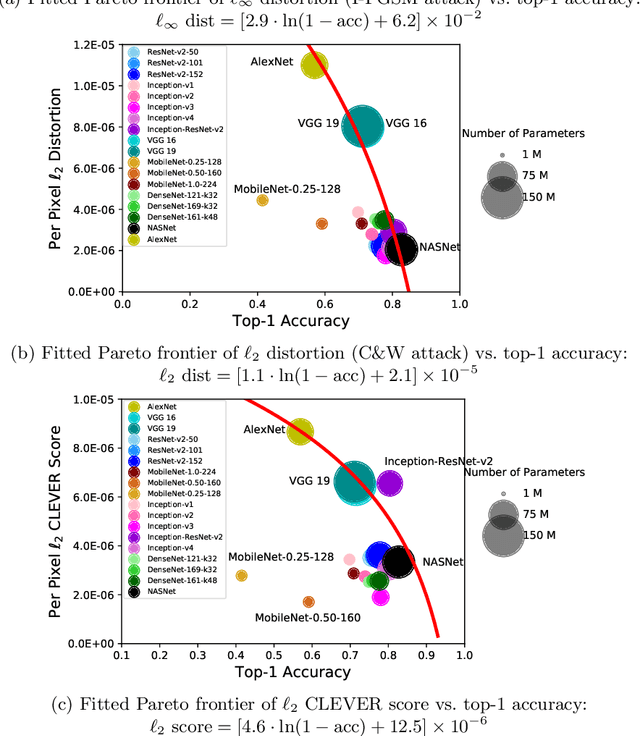
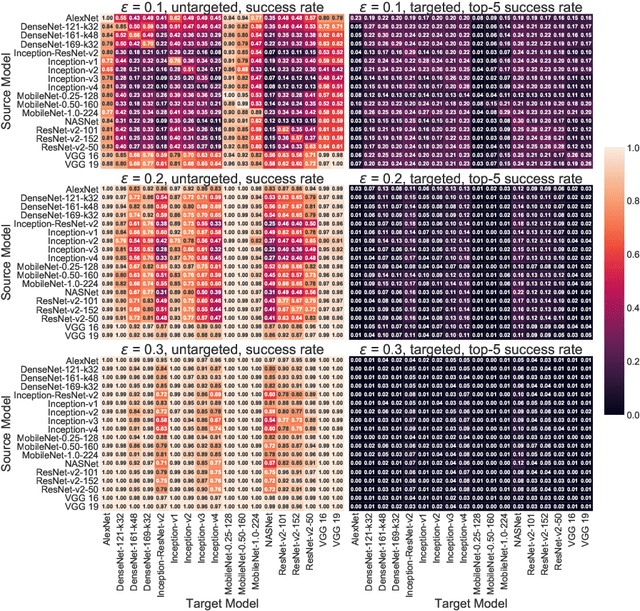
The prediction accuracy has been the long-lasting and sole standard for comparing the performance of different image classification models, including the ImageNet competition. However, recent studies have highlighted the lack of robustness in well-trained deep neural networks to adversarial examples. Visually imperceptible perturbations to natural images can easily be crafted and mislead the image classifiers towards misclassification. To demystify the trade-offs between robustness and accuracy, in this paper we thoroughly benchmark 18 ImageNet models using multiple robustness metrics, including the distortion, success rate and transferability of adversarial examples between 306 pairs of models. Our extensive experimental results reveal several new insights: (1) linear scaling law - the empirical $\ell_2$ and $\ell_\infty$ distortion metrics scale linearly with the logarithm of classification error; (2) model architecture is a more critical factor to robustness than model size, and the disclosed accuracy-robustness Pareto frontier can be used as an evaluation criterion for ImageNet model designers; (3) for a similar network architecture, increasing network depth slightly improves robustness in $\ell_\infty$ distortion; (4) there exist models (in VGG family) that exhibit high adversarial transferability, while most adversarial examples crafted from one model can only be transferred within the same family. Experiment code is publicly available at \url{https://github.com/huanzhang12/Adversarial_Survey}.
Evaluating the Robustness of Neural Networks: An Extreme Value Theory Approach
Jan 31, 2018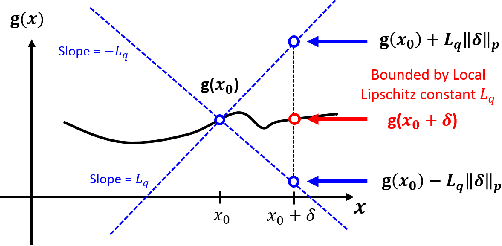
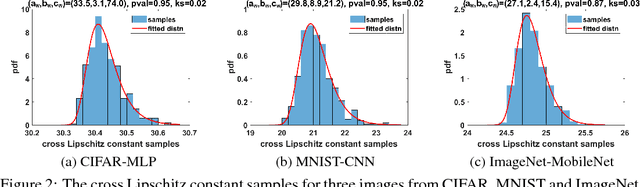
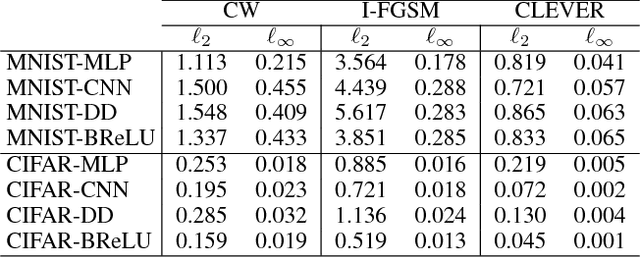
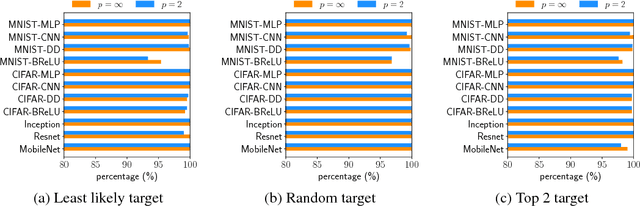
The robustness of neural networks to adversarial examples has received great attention due to security implications. Despite various attack approaches to crafting visually imperceptible adversarial examples, little has been developed towards a comprehensive measure of robustness. In this paper, we provide a theoretical justification for converting robustness analysis into a local Lipschitz constant estimation problem, and propose to use the Extreme Value Theory for efficient evaluation. Our analysis yields a novel robustness metric called CLEVER, which is short for Cross Lipschitz Extreme Value for nEtwork Robustness. The proposed CLEVER score is attack-agnostic and computationally feasible for large neural networks. Experimental results on various networks, including ResNet, Inception-v3 and MobileNet, show that (i) CLEVER is aligned with the robustness indication measured by the $\ell_2$ and $\ell_\infty$ norms of adversarial examples from powerful attacks, and (ii) defended networks using defensive distillation or bounded ReLU indeed achieve better CLEVER scores. To the best of our knowledge, CLEVER is the first attack-independent robustness metric that can be applied to any neural network classifier.