 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
Jan 31, 2025



Large language models (LLMs) are vulnerable to universal jailbreaks-prompting strategies that systematically bypass model safeguards and enable users to carry out harmful processes that require many model interactions, like manufacturing illegal substances at scale. To defend against these attacks, we introduce Constitutional Classifiers: safeguards trained on synthetic data, generated by prompting LLMs with natural language rules (i.e., a constitution) specifying permitted and restricted content. In over 3,000 estimated hours of red teaming, no red teamer found a universal jailbreak that could extract information from an early classifier-guarded LLM at a similar level of detail to an unguarded model across most target queries. On automated evaluations, enhanced classifiers demonstrated robust defense against held-out domain-specific jailbreaks. These classifiers also maintain deployment viability, with an absolute 0.38% increase in production-traffic refusals and a 23.7% inference overhead. Our work demonstrates that defending against universal jailbreaks while maintaining practical deployment viability is tractable.
Towards Generating Informative Textual Description for Neurons in Language Models
Jan 30, 2024Recent developments in transformer-based language models have allowed them to capture a wide variety of world knowledge that can be adapted to downstream tasks with limited resources. However, what pieces of information are understood in these models is unclear, and neuron-level contributions in identifying them are largely unknown. Conventional approaches in neuron explainability either depend on a finite set of pre-defined descriptors or require manual annotations for training a secondary model that can then explain the neurons of the primary model. In this paper, we take BERT as an example and we try to remove these constraints and propose a novel and scalable framework that ties textual descriptions to neurons. We leverage the potential of generative language models to discover human-interpretable descriptors present in a dataset and use an unsupervised approach to explain neurons with these descriptors. Through various qualitative and quantitative analyses, we demonstrate the effectiveness of this framework in generating useful data-specific descriptors with little human involvement in identifying the neurons that encode these descriptors. In particular, our experiment shows that the proposed approach achieves 75% precision@2, and 50% recall@2
URET: Universal Robustness Evaluation Toolkit (for Evasion)
Aug 03, 2023
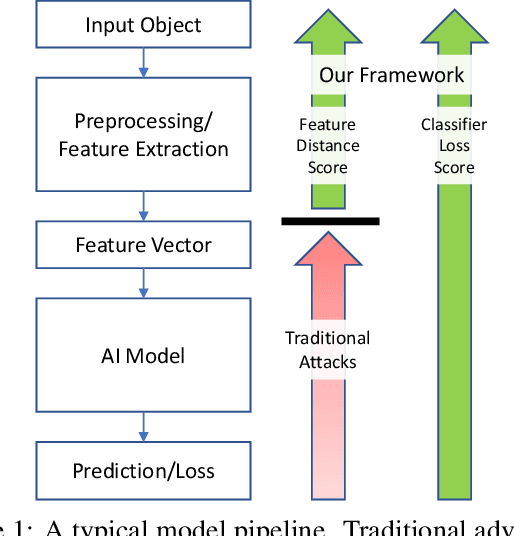

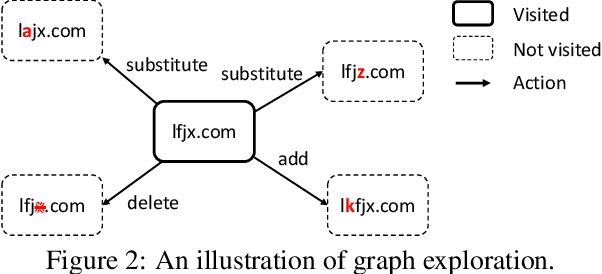
Machine learning models are known to be vulnerable to adversarial evasion attacks as illustrated by image classification models. Thoroughly understanding such attacks is critical in order to ensure the safety and robustness of critical AI tasks. However, most evasion attacks are difficult to deploy against a majority of AI systems because they have focused on image domain with only few constraints. An image is composed of homogeneous, numerical, continuous, and independent features, unlike many other input types to AI systems used in practice. Furthermore, some input types include additional semantic and functional constraints that must be observed to generate realistic adversarial inputs. In this work, we propose a new framework to enable the generation of adversarial inputs irrespective of the input type and task domain. Given an input and a set of pre-defined input transformations, our framework discovers a sequence of transformations that result in a semantically correct and functional adversarial input. We demonstrate the generality of our approach on several diverse machine learning tasks with various input representations. We also show the importance of generating adversarial examples as they enable the deployment of mitigation techniques.
Matching Pairs: Attributing Fine-Tuned Models to their Pre-Trained Large Language Models
Jun 15, 2023The wide applicability and adaptability of generative large language models (LLMs) has enabled their rapid adoption. While the pre-trained models can perform many tasks, such models are often fine-tuned to improve their performance on various downstream applications. However, this leads to issues over violation of model licenses, model theft, and copyright infringement. Moreover, recent advances show that generative technology is capable of producing harmful content which exacerbates the problems of accountability within model supply chains. Thus, we need a method to investigate how a model was trained or a piece of text was generated and what their pre-trained base model was. In this paper we take the first step to address this open problem by tracing back the origin of a given fine-tuned LLM to its corresponding pre-trained base model. We consider different knowledge levels and attribution strategies, and find that we can correctly trace back 8 out of the 10 fine tuned models with our best method.
Robustness of Explanation Methods for NLP Models
Jun 24, 2022



Explanation methods have emerged as an important tool to highlight the features responsible for the predictions of neural networks. There is mounting evidence that many explanation methods are rather unreliable and susceptible to malicious manipulations. In this paper, we particularly aim to understand the robustness of explanation methods in the context of text modality. We provide initial insights and results towards devising a successful adversarial attack against text explanations. To our knowledge, this is the first attempt to evaluate the adversarial robustness of an explanation method. Our experiments show the explanation method can be largely disturbed for up to 86% of the tested samples with small changes in the input sentence and its semantics.
Adaptive Verifiable Training Using Pairwise Class Similarity
Dec 14, 2020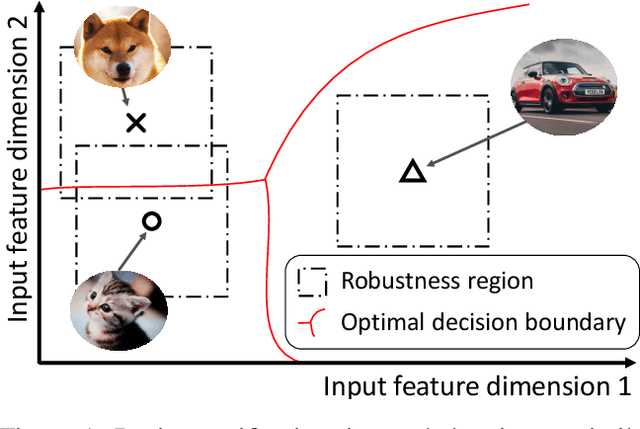
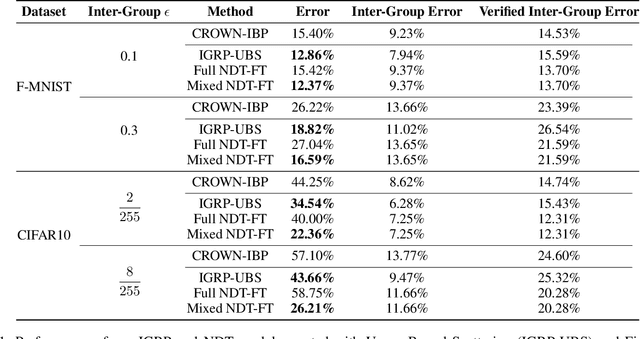
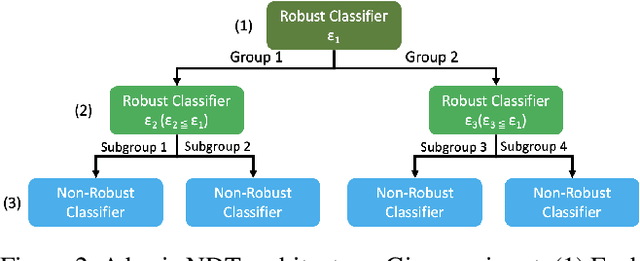
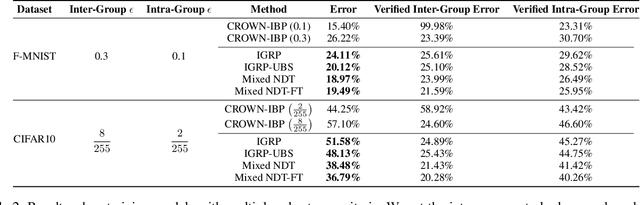
Verifiable training has shown success in creating neural networks that are provably robust to a given amount of noise. However, despite only enforcing a single robustness criterion, its performance scales poorly with dataset complexity. On CIFAR10, a non-robust LeNet model has a 21.63% error rate, while a model created using verifiable training and a L-infinity robustness criterion of 8/255, has an error rate of 57.10%. Upon examination, we find that when labeling visually similar classes, the model's error rate is as high as 61.65%. We attribute the loss in performance to inter-class similarity. Similar classes (i.e., close in the feature space) increase the difficulty of learning a robust model. While it's desirable to train a robust model for a large robustness region, pairwise class similarities limit the potential gains. Also, consideration must be made regarding the relative cost of mistaking similar classes. In security or safety critical tasks, similar classes are likely to belong to the same group, and thus are equally sensitive. In this work, we propose a new approach that utilizes inter-class similarity to improve the performance of verifiable training and create robust models with respect to multiple adversarial criteria. First, we use agglomerate clustering to group similar classes and assign robustness criteria based on the similarity between clusters. Next, we propose two methods to apply our approach: (1) Inter-Group Robustness Prioritization, which uses a custom loss term to create a single model with multiple robustness guarantees and (2) neural decision trees, which trains multiple sub-classifiers with different robustness guarantees and combines them in a decision tree architecture. On Fashion-MNIST and CIFAR10, our approach improves clean performance by 9.63% and 30.89% respectively. On CIFAR100, our approach improves clean performance by 26.32%.
A new measure for overfitting and its implications for backdooring of deep learning
Jun 18, 2020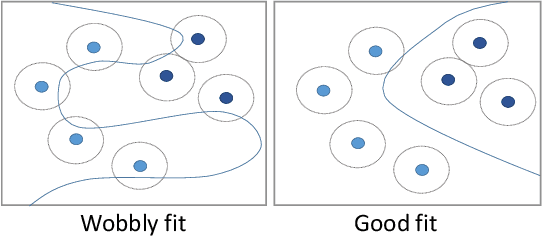
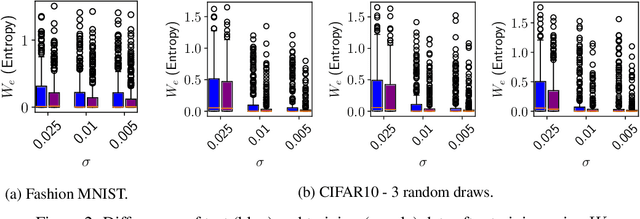
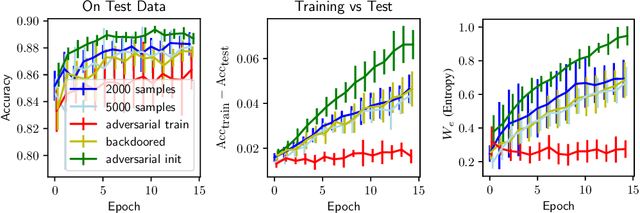
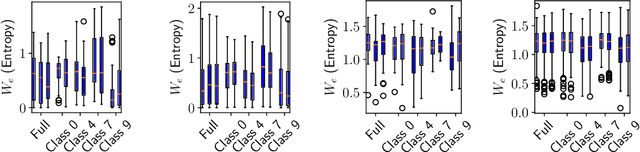
Overfitting describes the phenomenon that a machine learning model fits the given data instead of learning the underlying distribution. Existing approaches are computationally expensive, require large amounts of labeled data, consider overfitting global phenomenon, and often compute a single measurement. Instead, we propose a local measurement around a small number of unlabeled test points to obtain features of overfitting. Our extensive evaluation shows that the measure can reflect the model's different fit of training and test data, identify changes of the fit during training, and even suggest different fit among classes. We further apply our method to verify if backdoors rely on overfitting, a common claim in security of deep learning. Instead, we find that backdoors rely on underfitting. Our findings also provide evidence that even unbackdoored neural networks contain patterns similar to backdoors that are reliably classified as one class.
Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering
Nov 09, 2018

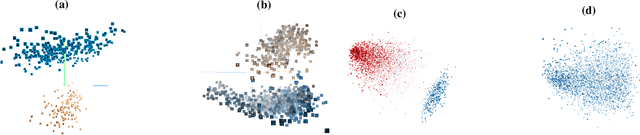

While machine learning (ML) models are being increasingly trusted to make decisions in different and varying areas, the safety of systems using such models has become an increasing concern. In particular, ML models are often trained on data from potentially untrustworthy sources, providing adversaries with the opportunity to manipulate them by inserting carefully crafted samples into the training set. Recent work has shown that this type of attack, called a poisoning attack, allows adversaries to insert backdoors or trojans into the model, enabling malicious behavior with simple external backdoor triggers at inference time and only a blackbox perspective of the model itself. Detecting this type of attack is challenging because the unexpected behavior occurs only when a backdoor trigger, which is known only to the adversary, is present. Model users, either direct users of training data or users of pre-trained model from a catalog, may not guarantee the safe operation of their ML-based system. In this paper, we propose a novel approach to backdoor detection and removal for neural networks. Through extensive experimental results, we demonstrate its effectiveness for neural networks classifying text and images. To the best of our knowledge, this is the first methodology capable of detecting poisonous data crafted to insert backdoors and repairing the model that does not require a verified and trusted dataset.
Defending Against Model Stealing Attacks Using Deceptive Perturbations
Sep 19, 2018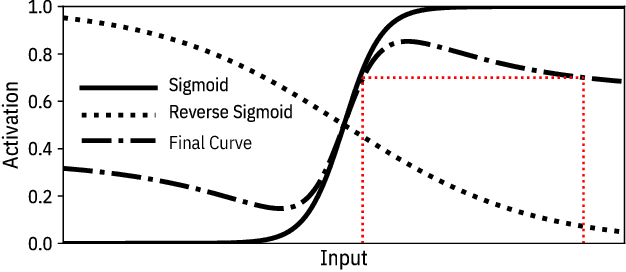
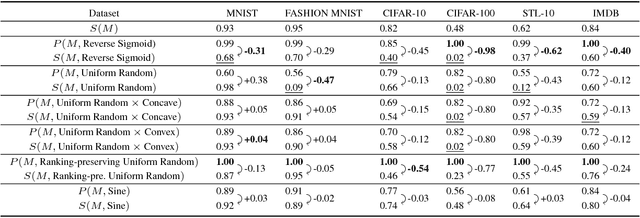
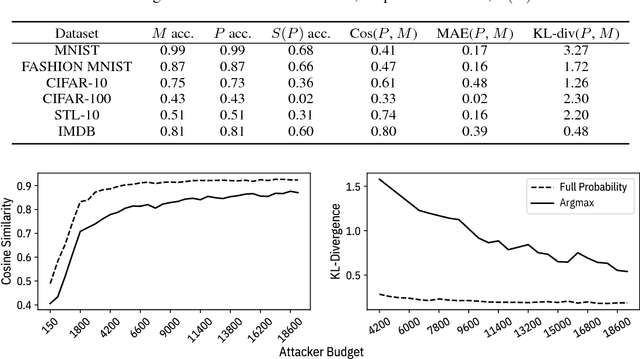
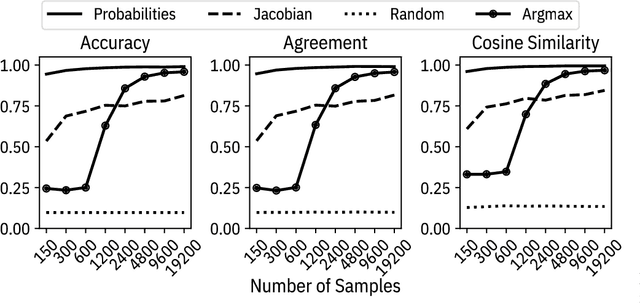
Machine learning models are vulnerable to simple model stealing attacks if the adversary can obtain output labels for chosen inputs. To protect against these attacks, it has been proposed to limit the information provided to the adversary by omitting probability scores, significantly impacting the utility of the provided service. In this work, we illustrate how a service provider can still provide useful, albeit misleading, class probability information, while significantly limiting the success of the attack. Our defense forces the adversary to discard the class probabilities, requiring significantly more queries before they can train a model with comparable performance. We evaluate several attack strategies, model architectures, and hyperparameters under varying adversarial models, and evaluate the efficacy of our defense against the strongest adversary. Finally, we quantify the amount of noise injected into the class probabilities to mesure the loss in utility, e.g., adding 1.26 nats per query on CIFAR-10 and 3.27 on MNIST. Our evaluation shows our defense can degrade the accuracy of the stolen model at least 20%, or require up to 64 times more queries while keeping the accuracy of the protected model almost intact.