 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Stolenly Swear That I Am Up to (No) Good: Design and Evaluation of Model Stealing Attacks
Aug 29, 2025
Model stealing attacks endanger the confidentiality of machine learning models offered as a service. Although these models are kept secret, a malicious party can query a model to label data samples and train their own substitute model, violating intellectual property. While novel attacks in the field are continually being published, their design and evaluations are not standardised, making it challenging to compare prior works and assess progress in the field. This paper is the first to address this gap by providing recommendations for designing and evaluating model stealing attacks. To this end, we study the largest group of attacks that rely on training a substitute model -- those attacking image classification models. We propose the first comprehensive threat model and develop a framework for attack comparison. Further, we analyse attack setups from related works to understand which tasks and models have been studied the most. Based on our findings, we present best practices for attack development before, during, and beyond experiments and derive an extensive list of open research questions regarding the evaluation of model stealing attacks. Our findings and recommendations also transfer to other problem domains, hence establishing the first generic evaluation methodology for model stealing attacks.
Design Patterns for Securing LLM Agents against Prompt Injections
Jun 11, 2025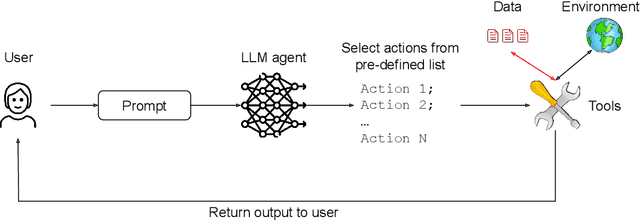
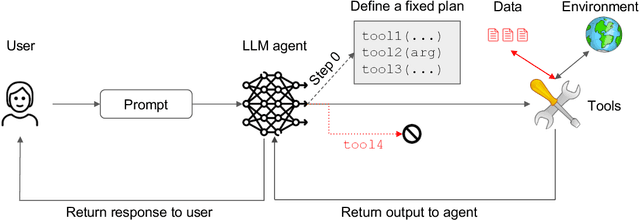
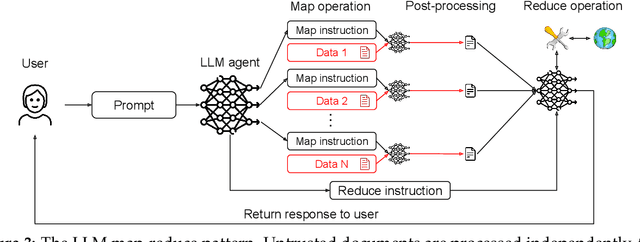
As AI agents powered by Large Language Models (LLMs) become increasingly versatile and capable of addressing a broad spectrum of tasks, ensuring their security has become a critical challenge. Among the most pressing threats are prompt injection attacks, which exploit the agent's resilience on natural language inputs -- an especially dangerous threat when agents are granted tool access or handle sensitive information. In this work, we propose a set of principled design patterns for building AI agents with provable resistance to prompt injection. We systematically analyze these patterns, discuss their trade-offs in terms of utility and security, and illustrate their real-world applicability through a series of case studies.
Manipulating Trajectory Prediction with Backdoors
Jan 03, 2024



Autonomous vehicles ought to predict the surrounding agents' trajectories to allow safe maneuvers in uncertain and complex traffic situations. As companies increasingly apply trajectory prediction in the real world, security becomes a relevant concern. In this paper, we focus on backdoors - a security threat acknowledged in other fields but so far overlooked for trajectory prediction. To this end, we describe and investigate four triggers that could affect trajectory prediction. We then show that these triggers (for example, a braking vehicle), when correlated with a desired output (for example, a curve) during training, cause the desired output of a state-of-the-art trajectory prediction model. In other words, the model has good benign performance but is vulnerable to backdoors. This is the case even if the trigger maneuver is performed by a non-casual agent behind the target vehicle. As a side-effect, our analysis reveals interesting limitations within trajectory prediction models. Finally, we evaluate a range of defenses against backdoors. While some, like simple offroad checks, do not enable detection for all triggers, clustering is a promising candidate to support manual inspection to find backdoors.
Towards more Practical Threat Models in Artificial Intelligence Security
Nov 16, 2023
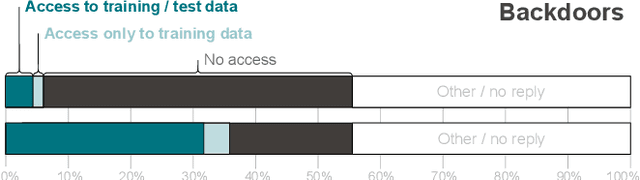


Recent works have identified a gap between research and practice in artificial intelligence security: threats studied in academia do not always reflect the practical use and security risks of AI. For example, while models are often studied in isolation, they form part of larger ML pipelines in practice. Recent works also brought forward that adversarial manipulations introduced by academic attacks are impractical. We take a first step towards describing the full extent of this disparity. To this end, we revisit the threat models of the six most studied attacks in AI security research and match them to AI usage in practice via a survey with \textbf{271} industrial practitioners. On the one hand, we find that all existing threat models are indeed applicable. On the other hand, there are significant mismatches: research is often too generous with the attacker, assuming access to information not frequently available in real-world settings. Our paper is thus a call for action to study more practical threat models in artificial intelligence security.
A Survey on Reinforcement Learning Security with Application to Autonomous Driving
Dec 12, 2022
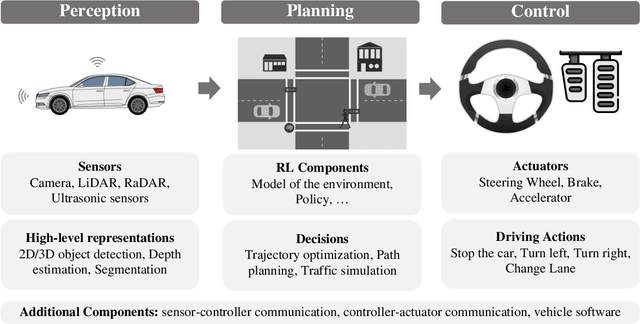


Reinforcement learning allows machines to learn from their own experience. Nowadays, it is used in safety-critical applications, such as autonomous driving, despite being vulnerable to attacks carefully crafted to either prevent that the reinforcement learning algorithm learns an effective and reliable policy, or to induce the trained agent to make a wrong decision. The literature about the security of reinforcement learning is rapidly growing, and some surveys have been proposed to shed light on this field. However, their categorizations are insufficient for choosing an appropriate defense given the kind of system at hand. In our survey, we do not only overcome this limitation by considering a different perspective, but we also discuss the applicability of state-of-the-art attacks and defenses when reinforcement learning algorithms are used in the context of autonomous driving.
"Why do so?" -- A Practical Perspective on Machine Learning Security
Jul 11, 2022
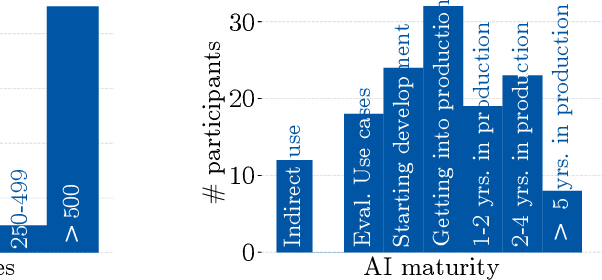

Despite the large body of academic work on machine learning security, little is known about the occurrence of attacks on machine learning systems in the wild. In this paper, we report on a quantitative study with 139 industrial practitioners. We analyze attack occurrence and concern and evaluate statistical hypotheses on factors influencing threat perception and exposure. Our results shed light on real-world attacks on deployed machine learning. On the organizational level, while we find no predictors for threat exposure in our sample, the amount of implement defenses depends on exposure to threats or expected likelihood to become a target. We also provide a detailed analysis of practitioners' replies on the relevance of individual machine learning attacks, unveiling complex concerns like unreliable decision making, business information leakage, and bias introduction into models. Finally, we find that on the individual level, prior knowledge about machine learning security influences threat perception. Our work paves the way for more research about adversarial machine learning in practice, but yields also insights for regulation and auditing.
Wild Patterns Reloaded: A Survey of Machine Learning Security against Training Data Poisoning
May 04, 2022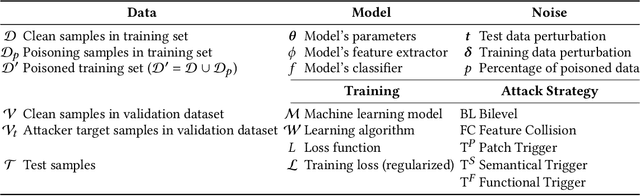
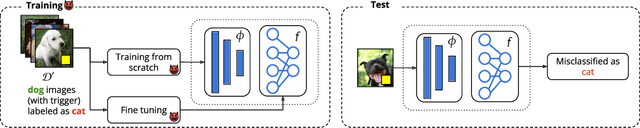

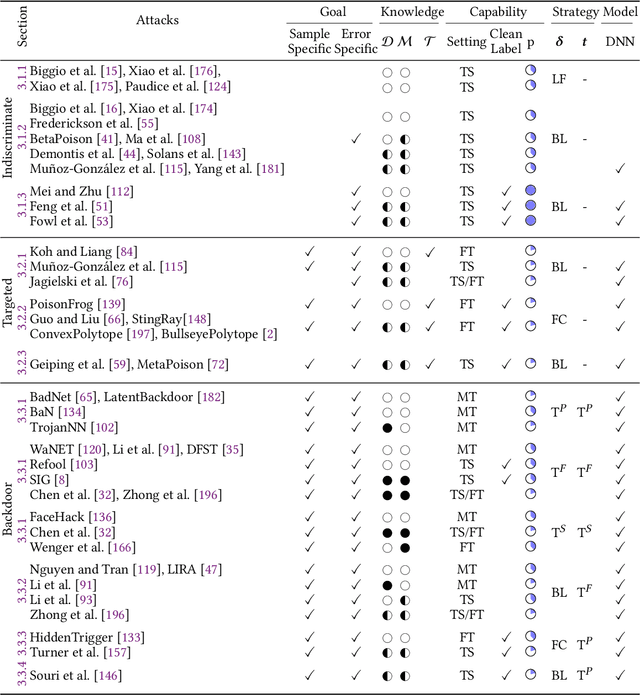
The success of machine learning is fueled by the increasing availability of computing power and large training datasets. The training data is used to learn new models or update existing ones, assuming that it is sufficiently representative of the data that will be encountered at test time. This assumption is challenged by the threat of poisoning, an attack that manipulates the training data to compromise the model's performance at test time. Although poisoning has been acknowledged as a relevant threat in industry applications, and a variety of different attacks and defenses have been proposed so far, a complete systematization and critical review of the field is still missing. In this survey, we provide a comprehensive systematization of poisoning attacks and defenses in machine learning, reviewing more than 200 papers published in the field in the last 15 years. We start by categorizing the current threat models and attacks, and then organize existing defenses accordingly. While we focus mostly on computer-vision applications, we argue that our systematization also encompasses state-of-the-art attacks and defenses for other data modalities. Finally, we discuss existing resources for research in poisoning, and shed light on the current limitations and open research questions in this research field.
Machine Learning Security against Data Poisoning: Are We There Yet?
Apr 12, 2022

The recent success of machine learning has been fueled by the increasing availability of computing power and large amounts of data in many different applications. However, the trustworthiness of the resulting models can be compromised when such data is maliciously manipulated to mislead the learning process. In this article, we first review poisoning attacks that compromise the training data used to learn machine-learning models, including attacks that aim to reduce the overall performance, manipulate the predictions on specific test samples, and even implant backdoors in the model. We then discuss how to mitigate these attacks before, during, and after model training. We conclude our article by formulating some relevant open challenges which are hindering the development of testing methods and benchmarks suitable for assessing and improving the trustworthiness of machine-learning models against data poisoning attacks.
Backdoor Learning Curves: Explaining Backdoor Poisoning Beyond Influence Functions
Jun 14, 2021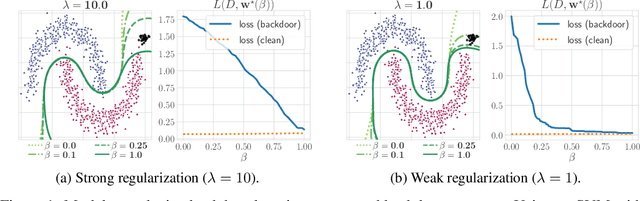
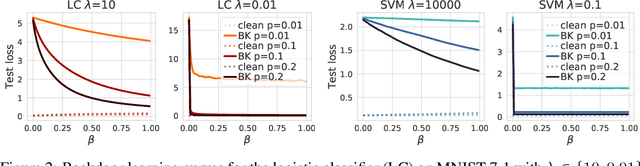
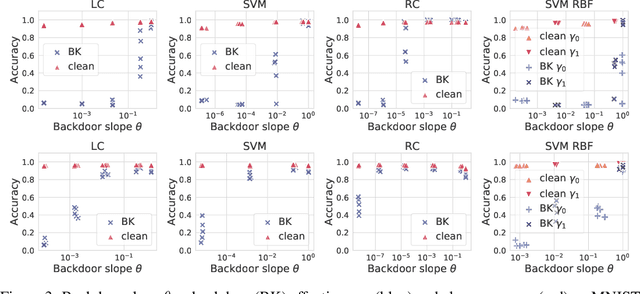
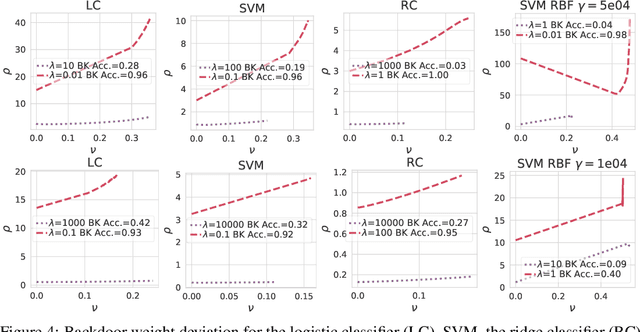
Backdoor attacks inject poisoning samples during training, with the goal of enforcing a machine-learning model to output an attacker-chosen class when presented a specific trigger at test time. Although backdoor attacks have been demonstrated in a variety of settings and against different models, the factors affecting their success are not yet well understood. In this work, we provide a unifying framework to study the process of backdoor learning under the lens of incremental learning and influence functions. We show that the success of backdoor attacks inherently depends on (i) the complexity of the learning algorithm, controlled by its hyperparameters, and (ii) the fraction of backdoor samples injected into the training set. These factors affect how fast a machine-learning model learns to correlate the presence of a backdoor trigger with the target class. Interestingly, our analysis shows that there exists a region in the hyperparameter space in which the accuracy on clean test samples is still high while backdoor attacks become ineffective, thereby suggesting novel criteria to improve existing defenses.
Mental Models of Adversarial Machine Learning
May 08, 2021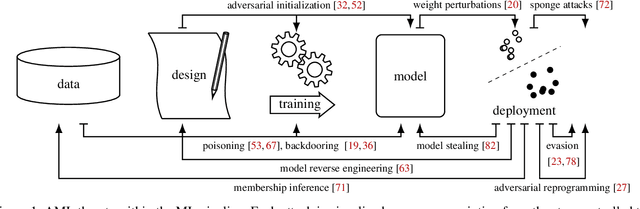
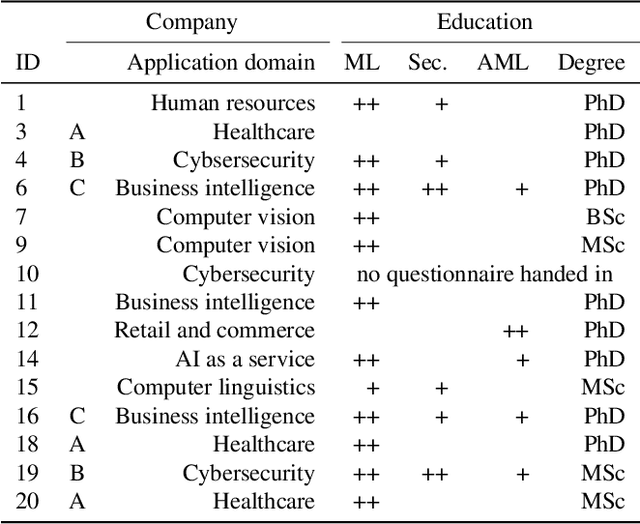
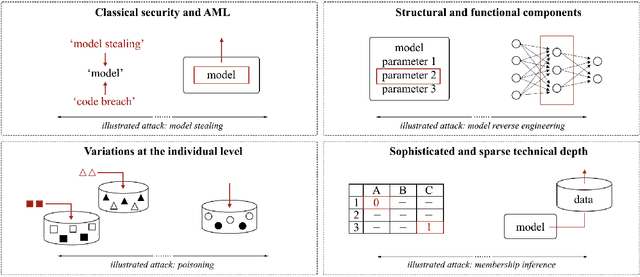
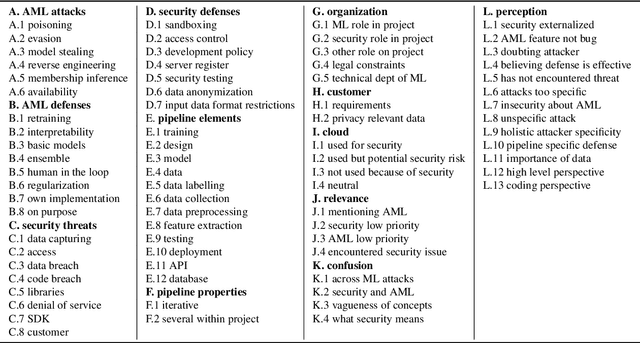
Although machine learning (ML) is widely used in practice, little is known about practitioners' actual understanding of potential security challenges. In this work, we close this substantial gap in the literature and contribute a qualitative study focusing on developers' mental models of the ML pipeline and potentially vulnerable components. Studying mental models has helped in other security fields to discover root causes or improve risk communication. Our study reveals four characteristic ranges in mental models of industrial practitioners. The first range concerns the intertwined relationship of adversarial machine learning (AML) and classical security. The second range describes structural and functional components. The third range expresses individual variations of mental models, which are neither explained by the application nor by the educational background of the corresponding subjects. The fourth range corresponds to the varying levels of technical depth, which are however not determined by our subjects' level of knowledge. Our characteristic ranges have implications for the integration of AML into corporate workflows, security enhancing tools for practitioners, and creating appropriate regulatory frameworks for AML.