 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Hyperbolic Geometry for Harmful Prompt Detection and Sanitization
Apr 07, 2026Vision-Language Models (VLMs) have become essential for tasks such as image synthesis, captioning, and retrieval by aligning textual and visual information in a shared embedding space. Yet, this flexibility also makes them vulnerable to malicious prompts designed to produce unsafe content, raising critical safety concerns. Existing defenses either rely on blacklist filters, which are easily circumvented, or on heavy classifier-based systems, both of which are costly and fragile under embedding-level attacks. We address these challenges with two complementary components: Hyperbolic Prompt Espial (HyPE) and Hyperbolic Prompt Sanitization (HyPS). HyPE is a lightweight anomaly detector that leverages the structured geometry of hyperbolic space to model benign prompts and detect harmful ones as outliers. HyPS builds on this detection by applying explainable attribution methods to identify and selectively modify harmful words, neutralizing unsafe intent while preserving the original semantics of user prompts. Through extensive experiments across multiple datasets and adversarial scenarios, we prove that our framework consistently outperforms prior defenses in both detection accuracy and robustness. Together, HyPE and HyPS offer an efficient, interpretable, and resilient approach to safeguarding VLMs against malicious prompt misuse.
Robust image classification with multi-modal large language models
Dec 13, 2024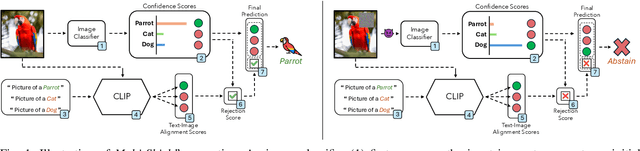
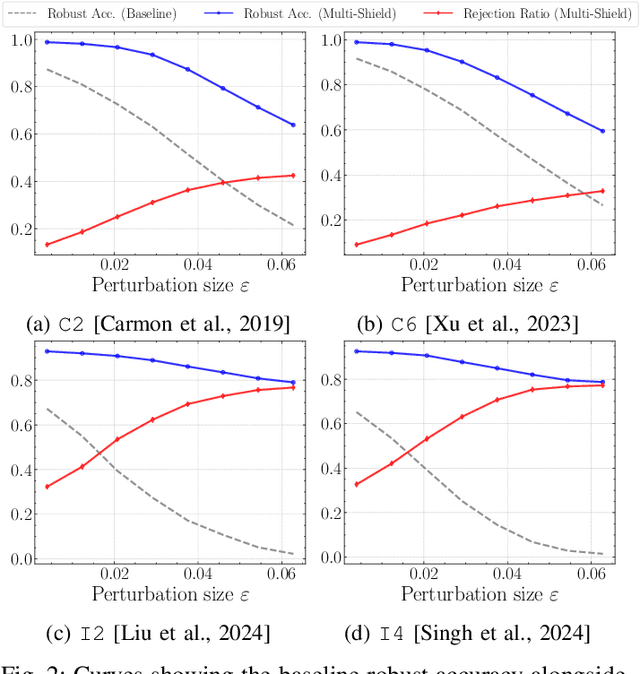
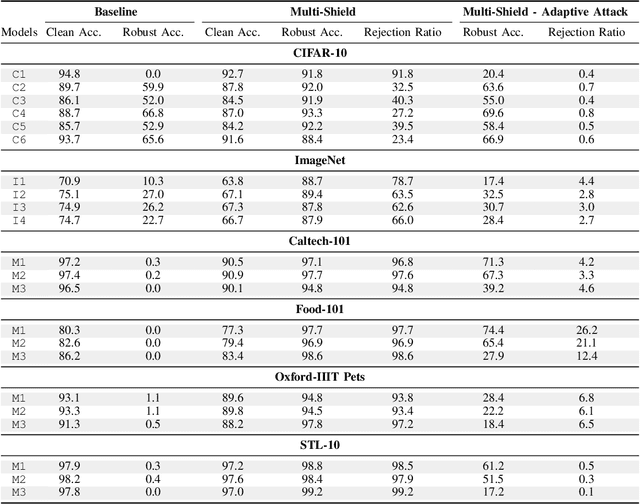
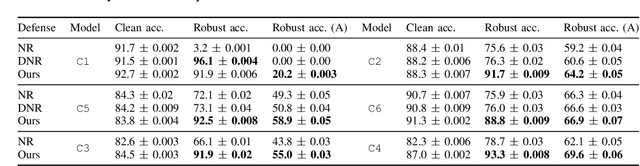
Deep Neural Networks are vulnerable to adversarial examples, i.e., carefully crafted input samples that can cause models to make incorrect predictions with high confidence. To mitigate these vulnerabilities, adversarial training and detection-based defenses have been proposed to strengthen models in advance. However, most of these approaches focus on a single data modality, overlooking the relationships between visual patterns and textual descriptions of the input. In this paper, we propose a novel defense, Multi-Shield, designed to combine and complement these defenses with multi-modal information to further enhance their robustness. Multi-Shield leverages multi-modal large language models to detect adversarial examples and abstain from uncertain classifications when there is no alignment between textual and visual representations of the input. Extensive evaluations on CIFAR-10 and ImageNet datasets, using robust and non-robust image classification models, demonstrate that Multi-Shield can be easily integrated to detect and reject adversarial examples, outperforming the original defenses.
On the Robustness of Adversarial Training Against Uncertainty Attacks
Oct 29, 2024


In learning problems, the noise inherent to the task at hand hinders the possibility to infer without a certain degree of uncertainty. Quantifying this uncertainty, regardless of its wide use, assumes high relevance for security-sensitive applications. Within these scenarios, it becomes fundamental to guarantee good (i.e., trustworthy) uncertainty measures, which downstream modules can securely employ to drive the final decision-making process. However, an attacker may be interested in forcing the system to produce either (i) highly uncertain outputs jeopardizing the system's availability or (ii) low uncertainty estimates, making the system accept uncertain samples that would instead require a careful inspection (e.g., human intervention). Therefore, it becomes fundamental to understand how to obtain robust uncertainty estimates against these kinds of attacks. In this work, we reveal both empirically and theoretically that defending against adversarial examples, i.e., carefully perturbed samples that cause misclassification, additionally guarantees a more secure, trustworthy uncertainty estimate under common attack scenarios without the need for an ad-hoc defense strategy. To support our claims, we evaluate multiple adversarial-robust models from the publicly available benchmark RobustBench on the CIFAR-10 and ImageNet datasets.
Sonic: Fast and Transferable Data Poisoning on Clustering Algorithms
Aug 14, 2024



Data poisoning attacks on clustering algorithms have received limited attention, with existing methods struggling to scale efficiently as dataset sizes and feature counts increase. These attacks typically require re-clustering the entire dataset multiple times to generate predictions and assess the attacker's objectives, significantly hindering their scalability. This paper addresses these limitations by proposing Sonic, a novel genetic data poisoning attack that leverages incremental and scalable clustering algorithms, e.g., FISHDBC, as surrogates to accelerate poisoning attacks against graph-based and density-based clustering methods, such as HDBSCAN. We empirically demonstrate the effectiveness and efficiency of Sonic in poisoning the target clustering algorithms. We then conduct a comprehensive analysis of the factors affecting the scalability and transferability of poisoning attacks against clustering algorithms, and we conclude by examining the robustness of hyperparameters in our attack strategy Sonic.
Understanding XAI Through the Philosopher's Lens: A Historical Perspective
Jul 26, 2024
Despite explainable AI (XAI) has recently become a hot topic and several different approaches have been developed, there is still a widespread belief that it lacks a convincing unifying foundation. On the other hand, over the past centuries, the very concept of explanation has been the subject of extensive philosophical analysis in an attempt to address the fundamental question of "why" in the context of scientific law. However, this discussion has rarely been connected with XAI. This paper tries to fill in this gap and aims to explore the concept of explanation in AI through an epistemological lens. By comparing the historical development of both the philosophy of science and AI, an intriguing picture emerges. Specifically, we show that a gradual progression has independently occurred in both domains from logical-deductive to statistical models of explanation, thereby experiencing in both cases a paradigm shift from deterministic to nondeterministic and probabilistic causality. Interestingly, we also notice that similar concepts have independently emerged in both realms such as, for example, the relation between explanation and understanding and the importance of pragmatic factors. Our study aims to be the first step towards understanding the philosophical underpinnings of the notion of explanation in AI, and we hope that our findings will shed some fresh light on the elusive nature of XAI.
Over-parameterization and Adversarial Robustness in Neural Networks: An Overview and Empirical Analysis
Jun 14, 2024



Thanks to their extensive capacity, over-parameterized neural networks exhibit superior predictive capabilities and generalization. However, having a large parameter space is considered one of the main suspects of the neural networks' vulnerability to adversarial example -- input samples crafted ad-hoc to induce a desired misclassification. Relevant literature has claimed contradictory remarks in support of and against the robustness of over-parameterized networks. These contradictory findings might be due to the failure of the attack employed to evaluate the networks' robustness. Previous research has demonstrated that depending on the considered model, the algorithm employed to generate adversarial examples may not function properly, leading to overestimating the model's robustness. In this work, we empirically study the robustness of over-parameterized networks against adversarial examples. However, unlike the previous works, we also evaluate the considered attack's reliability to support the results' veracity. Our results show that over-parameterized networks are robust against adversarial attacks as opposed to their under-parameterized counterparts.
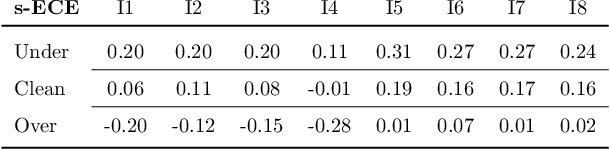
AttackBench: Evaluating Gradient-based Attacks for Adversarial Examples
Apr 30, 2024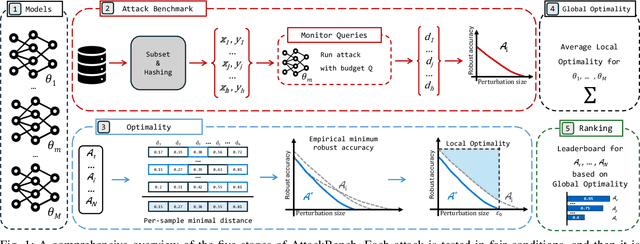
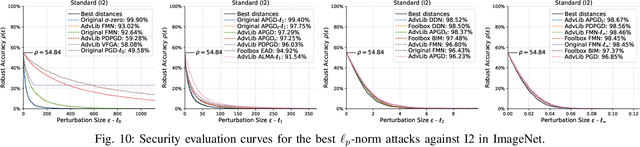
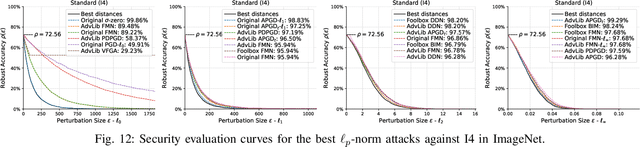
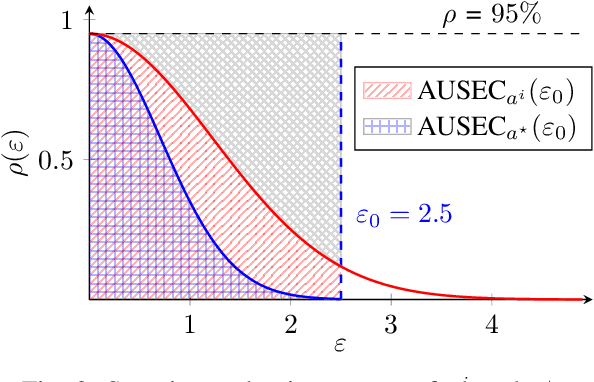
Adversarial examples are typically optimized with gradient-based attacks. While novel attacks are continuously proposed, each is shown to outperform its predecessors using different experimental setups, hyperparameter settings, and number of forward and backward calls to the target models. This provides overly-optimistic and even biased evaluations that may unfairly favor one particular attack over the others. In this work, we aim to overcome these limitations by proposing AttackBench, i.e., the first evaluation framework that enables a fair comparison among different attacks. To this end, we first propose a categorization of gradient-based attacks, identifying their main components and differences. We then introduce our framework, which evaluates their effectiveness and efficiency. We measure these characteristics by (i) defining an optimality metric that quantifies how close an attack is to the optimal solution, and (ii) limiting the number of forward and backward queries to the model, such that all attacks are compared within a given maximum query budget. Our extensive experimental analysis compares more than 100 attack implementations with a total of over 800 different configurations against CIFAR-10 and ImageNet models, highlighting that only very few attacks outperform all the competing approaches. Within this analysis, we shed light on several implementation issues that prevent many attacks from finding better solutions or running at all. We release AttackBench as a publicly available benchmark, aiming to continuously update it to include and evaluate novel gradient-based attacks for optimizing adversarial examples.
$σ$-zero: Gradient-based Optimization of $\ell_0$-norm Adversarial Examples
Feb 02, 2024Evaluating the adversarial robustness of deep networks to gradient-based attacks is challenging. While most attacks consider $\ell_2$- and $\ell_\infty$-norm constraints to craft input perturbations, only a few investigate sparse $\ell_1$- and $\ell_0$-norm attacks. In particular, $\ell_0$-norm attacks remain the least studied due to the inherent complexity of optimizing over a non-convex and non-differentiable constraint. However, evaluating adversarial robustness under these attacks could reveal weaknesses otherwise left untested with more conventional $\ell_2$- and $\ell_\infty$-norm attacks. In this work, we propose a novel $\ell_0$-norm attack, called $\sigma$-zero, which leverages an ad hoc differentiable approximation of the $\ell_0$ norm to facilitate gradient-based optimization, and an adaptive projection operator to dynamically adjust the trade-off between loss minimization and perturbation sparsity. Extensive evaluations using MNIST, CIFAR10, and ImageNet datasets, involving robust and non-robust models, show that $\sigma$-zero finds minimum $\ell_0$-norm adversarial examples without requiring any time-consuming hyperparameter tuning, and that it outperforms all competing sparse attacks in terms of success rate, perturbation size, and scalability.
Hardening RGB-D Object Recognition Systems against Adversarial Patch Attacks
Sep 13, 2023



RGB-D object recognition systems improve their predictive performances by fusing color and depth information, outperforming neural network architectures that rely solely on colors. While RGB-D systems are expected to be more robust to adversarial examples than RGB-only systems, they have also been proven to be highly vulnerable. Their robustness is similar even when the adversarial examples are generated by altering only the original images' colors. Different works highlighted the vulnerability of RGB-D systems; however, there is a lacking of technical explanations for this weakness. Hence, in our work, we bridge this gap by investigating the learned deep representation of RGB-D systems, discovering that color features make the function learned by the network more complex and, thus, more sensitive to small perturbations. To mitigate this problem, we propose a defense based on a detection mechanism that makes RGB-D systems more robust against adversarial examples. We empirically show that this defense improves the performances of RGB-D systems against adversarial examples even when they are computed ad-hoc to circumvent this detection mechanism, and that is also more effective than adversarial training.
Minimizing Energy Consumption of Deep Learning Models by Energy-Aware Training
Jul 01, 2023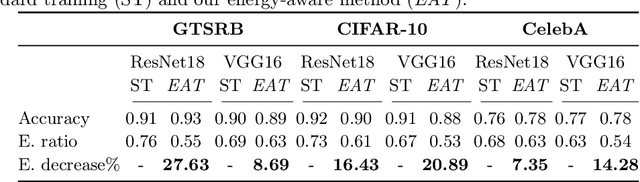
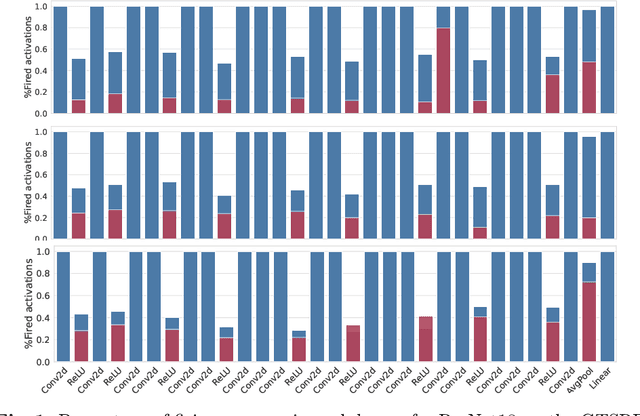
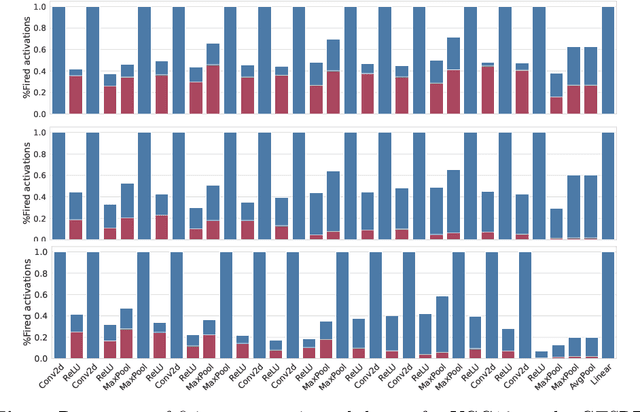
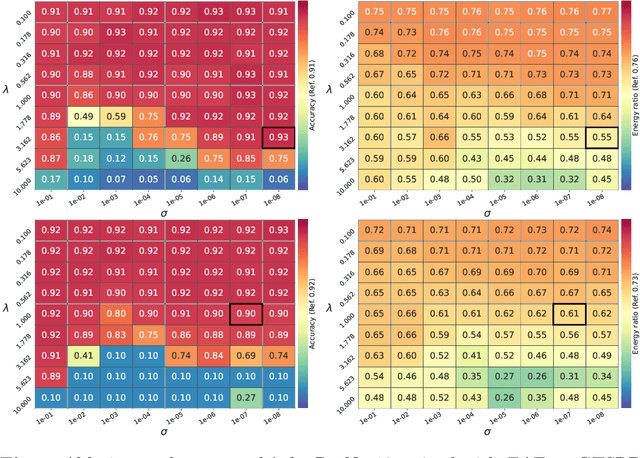
Deep learning models undergo a significant increase in the number of parameters they possess, leading to the execution of a larger number of operations during inference. This expansion significantly contributes to higher energy consumption and prediction latency. In this work, we propose EAT, a gradient-based algorithm that aims to reduce energy consumption during model training. To this end, we leverage a differentiable approximation of the $\ell_0$ norm, and use it as a sparse penalty over the training loss. Through our experimental analysis conducted on three datasets and two deep neural networks, we demonstrate that our energy-aware training algorithm EAT is able to train networks with a better trade-off between classification performance and energy efficiency.