 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttackBench: Evaluating Gradient-based Attacks for Adversarial Examples
Apr 30, 2024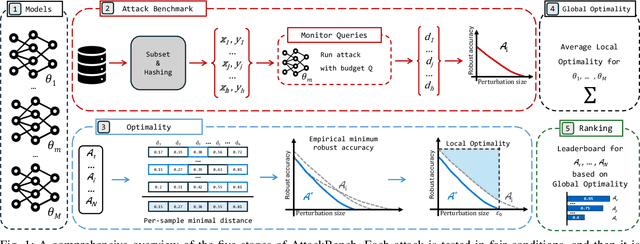
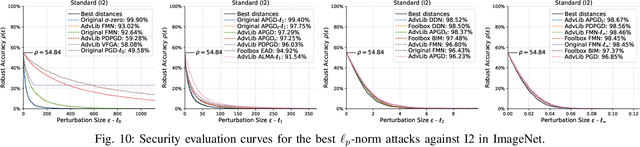
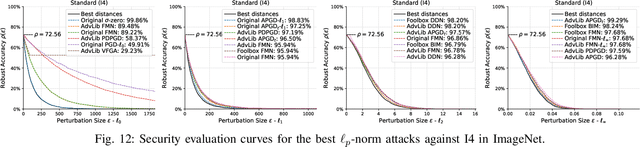
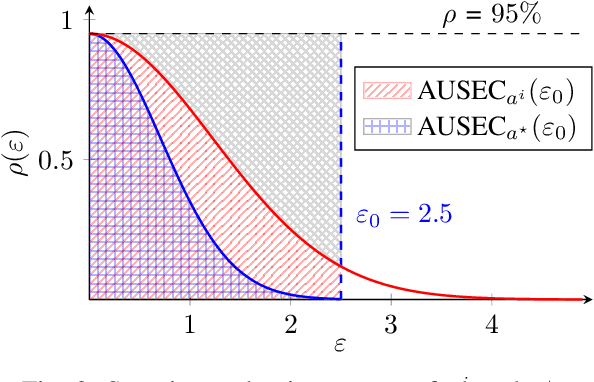
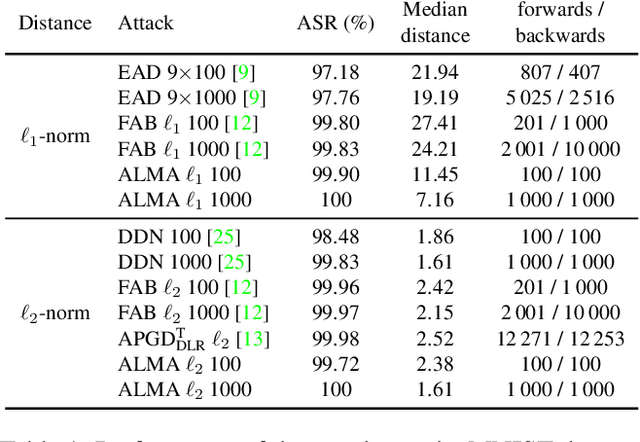
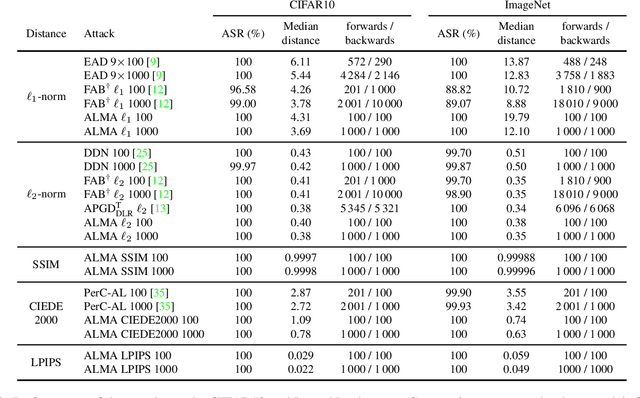
Adversarial examples are typically optimized with gradient-based attacks. While novel attacks are continuously proposed, each is shown to outperform its predecessors using different experimental setups, hyperparameter settings, and number of forward and backward calls to the target models. This provides overly-optimistic and even biased evaluations that may unfairly favor one particular attack over the others. In this work, we aim to overcome these limitations by proposing AttackBench, i.e., the first evaluation framework that enables a fair comparison among different attacks. To this end, we first propose a categorization of gradient-based attacks, identifying their main components and differences. We then introduce our framework, which evaluates their effectiveness and efficiency. We measure these characteristics by (i) defining an optimality metric that quantifies how close an attack is to the optimal solution, and (ii) limiting the number of forward and backward queries to the model, such that all attacks are compared within a given maximum query budget. Our extensive experimental analysis compares more than 100 attack implementations with a total of over 800 different configurations against CIFAR-10 and ImageNet models, highlighting that only very few attacks outperform all the competing approaches. Within this analysis, we shed light on several implementation issues that prevent many attacks from finding better solutions or running at all. We release AttackBench as a publicly available benchmark, aiming to continuously update it to include and evaluate novel gradient-based attacks for optimizing adversarial examples.
Class Adaptive Network Calibration
Nov 28, 2022
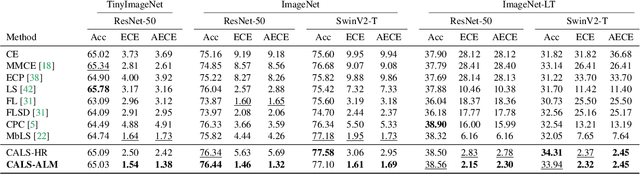
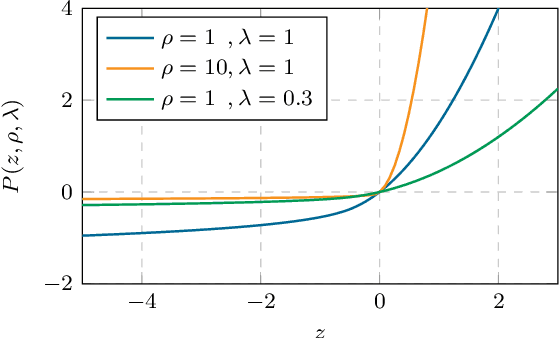
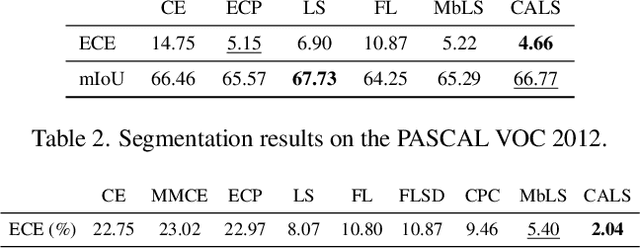
Recent studies have revealed that, beyond conventional accuracy, calibration should also be considered for training modern deep neural networks. To address miscalibration during learning, some methods have explored different penalty functions as part of the learning objective, alongside a standard classification loss, with a hyper-parameter controlling the relative contribution of each term. Nevertheless, these methods share two major drawbacks: 1) the scalar balancing weight is the same for all classes, hindering the ability to address different intrinsic difficulties or imbalance among classes; and 2) the balancing weight is usually fixed without an adaptive strategy, which may prevent from reaching the best compromise between accuracy and calibration, and requires hyper-parameter search for each application. We propose Class Adaptive Label Smoothing (CALS) for calibrating deep networks, which allows to learn class-wise multipliers during training, yielding a powerful alternative to common label smoothing penalties. Our method builds on a general Augmented Lagrangian approach, a well-established technique in constrained optimization, but we introduce several modifications to tailor it for large-scale, class-adaptive training. Comprehensive evaluation and multiple comparisons on a variety of benchmarks, including standard and long-tailed image classification, semantic segmentation, and text classification, demonstrate the superiority of the proposed method. The code is available at https://github.com/by-liu/CALS.
Proximal Splitting Adversarial Attacks for Semantic Segmentation
Jun 14, 2022
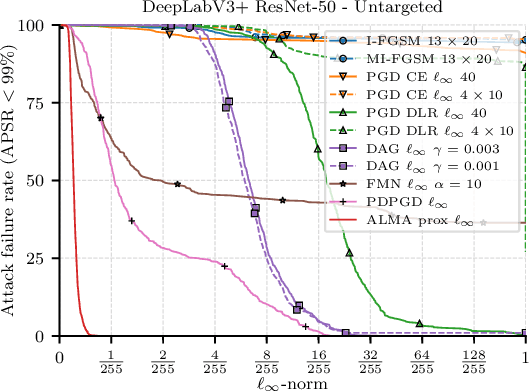

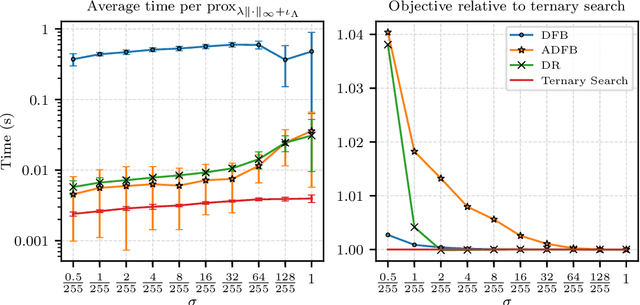
Classification has been the focal point of research on adversarial attacks, but only a few works investigate methods suited to denser prediction tasks, such as semantic segmentation. The methods proposed in these works do not accurately solve the adversarial segmentation problem and, therefore, are overoptimistic in terms of size of the perturbations required to fool models. Here, we propose a white-box attack for these models based on a proximal splitting to produce adversarial perturbations with much smaller $\ell_1$, $\ell_2$, or $\ell_\infty$ norms. Our attack can handle large numbers of constraints within a nonconvex minimization framework via an Augmented Lagrangian approach, coupled with adaptive constraint scaling and masking strategies. We demonstrate that our attack significantly outperforms previously proposed ones, as well as classification attacks that we adapted for segmentation, providing a first comprehensive benchmark for this dense task. Our results push current limits concerning robustness evaluations in segmentation tasks.
Leveraging Uncertainty for Deep Interpretable Classification and Weakly-Supervised Segmentation of Histology Images
May 12, 2022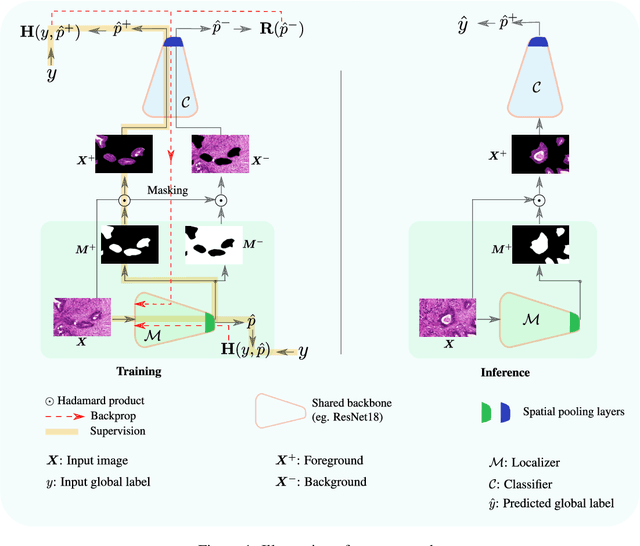
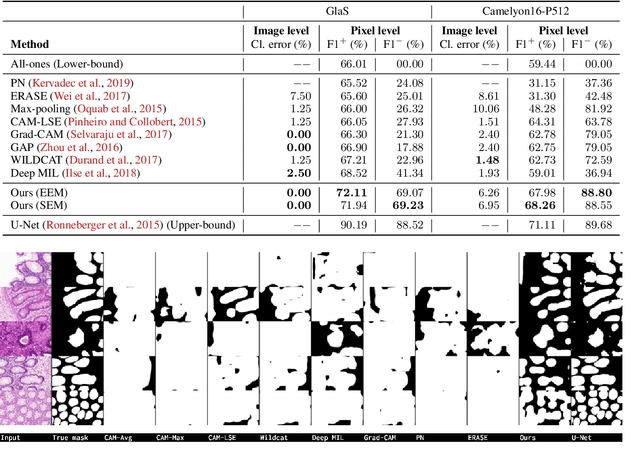


Trained using only image class label, deep weakly supervised methods allow image classification and ROI segmentation for interpretability. Despite their success on natural images, they face several challenges over histology data where ROI are visually similar to background making models vulnerable to high pixel-wise false positives. These methods lack mechanisms for modeling explicitly non-discriminative regions which raises false-positive rates. We propose novel regularization terms, which enable the model to seek both non-discriminative and discriminative regions, while discouraging unbalanced segmentations and using only image class label. Our method is composed of two networks: a localizer that yields segmentation mask, followed by a classifier. The training loss pushes the localizer to build a segmentation mask that holds most discrimiantive regions while simultaneously modeling background regions. Comprehensive experiments over two histology datasets showed the merits of our method in reducing false positives and accurately segmenting ROI.
Mutual-Information Based Few-Shot Classification
Jun 23, 2021
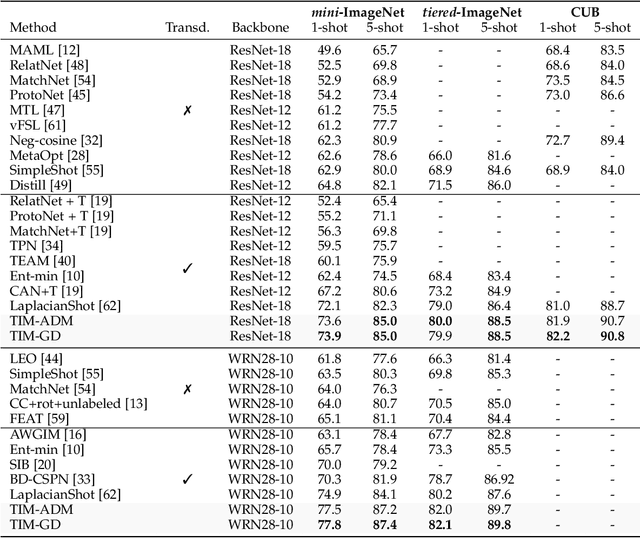
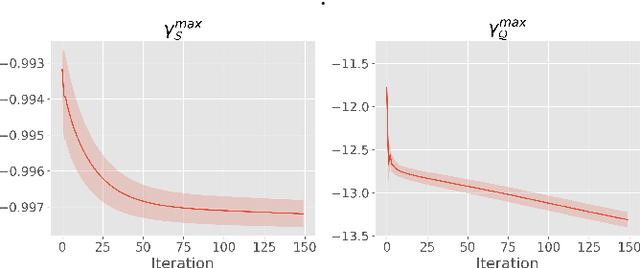

We introduce Transductive Infomation Maximization (TIM) for few-shot learning. Our method maximizes the mutual information between the query features and their label predictions for a given few-shot task, in conjunction with a supervision loss based on the support set. We motivate our transductive loss by deriving a formal relation between the classification accuracy and mutual-information maximization. Furthermore, we propose a new alternating-direction solver, which substantially speeds up transductive inference over gradient-based optimization, while yielding competitive accuracy. We also provide a convergence analysis of our solver based on Zangwill's theory and bound-optimization arguments. TIM inference is modular: it can be used on top of any base-training feature extractor. Following standard transductive few-shot settings, our comprehensive experiments demonstrate that TIM outperforms state-of-the-art methods significantly across various datasets and networks, while used on top of a fixed feature extractor trained with simple cross-entropy on the base classes, without resorting to complex meta-learning schemes. It consistently brings between 2 % and 5 % improvement in accuracy over the best performing method, not only on all the well-established few-shot benchmarks but also on more challenging scenarios, with random tasks, domain shift and larger numbers of classes, as in the recently introduced META-DATASET. Our code is publicly available at https://github.com/mboudiaf/TIM. We also publicly release a standalone PyTorch implementation of META-DATASET, along with additional benchmarking results, at https://github.com/mboudiaf/pytorch-meta-dataset.
Augmented Lagrangian Adversarial Attacks
Nov 24, 2020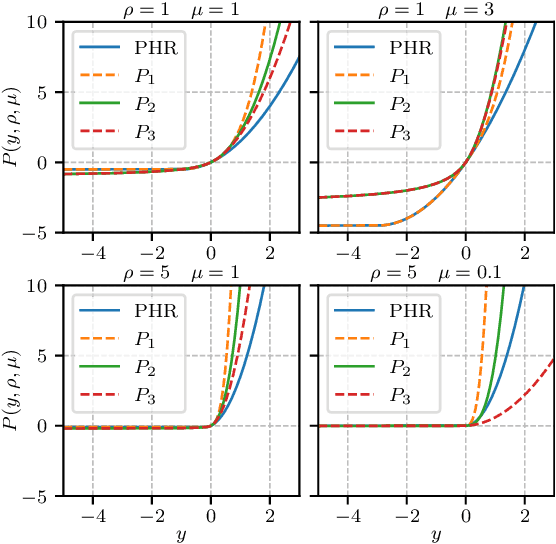
Adversarial attack algorithms are dominated by penalty methods, which are slow in practice, or more efficient distance-customized methods, which are heavily tailored to the properties of the considered distance. We propose a white-box attack algorithm to generate minimally perturbed adversarial examples based on Augmented Lagrangian principles. We bring several non-trivial algorithmic modifications, which have a crucial effect on performance. Our attack enjoys the generality of penalty methods and the computational efficiency of distance-customized algorithms, and can be readily used for a wide set of distances. We compare our attack to state-of-the-art methods on three datasets and several models, and consistently obtain competitive performances with similar or lower computational complexity.
Deep Interpretable Classification and Weakly-Supervised Segmentation of Histology Images via Max-Min Uncertainty
Nov 14, 2020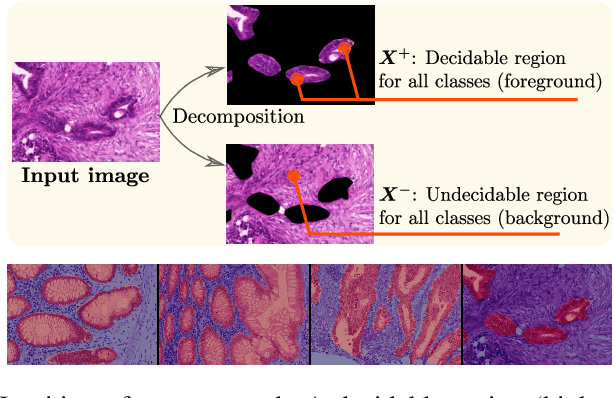
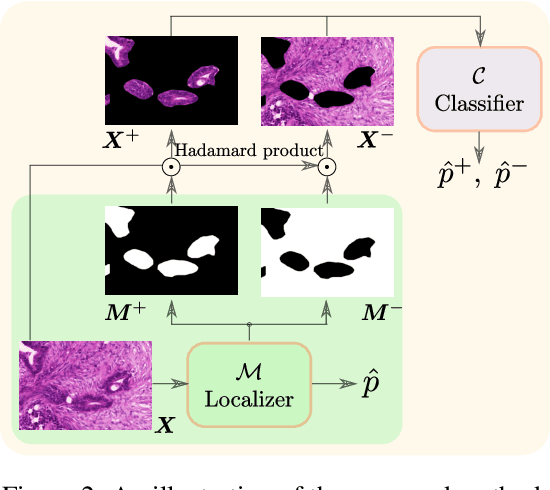
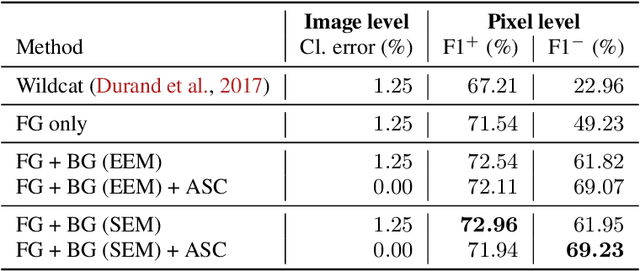
Weakly supervised learning (WSL) has recently triggered substantial interest as it mitigates the lack of pixel-wise annotations, while enabling interpretable models. Given global image labels, WSL methods yield pixel-level predictions (segmentations). Despite their recent success, mostly with natural images, such methods could be seriously challenged when the foreground and background regions have similar visual cues, yielding high false-positive rates in segmentations, as is the case of challenging histology images. WSL training is commonly driven by standard classification losses, which implicitly maximize model confidence and find the discriminative regions linked to classification decisions. Therefore, they lack mechanisms for modeling explicitly non-discriminative regions and reducing false-positive rates. We propose new regularization terms, which enable the model to seek both non-discriminative and discriminative regions, while discouraging unbalanced segmentations. We introduce high uncertainty as a criterion to localize non-discriminative regions that do not affect classifier decision, and describe it with original Kullback-Leibler (KL) divergence losses evaluating the deviation of posterior predictions from the uniform distribution. Our KL terms encourage high uncertainty of the model when the latter takes the latent non-discriminative regions as input. Our loss integrates: (i) a cross-entropy seeking a foreground, where model confidence about class prediction is high; (ii) a KL regularizer seeking a background, where model uncertainty is high; and (iii) log-barrier terms discouraging unbalanced segmentations. Comprehensive experiments and ablation studies over the public GlaS colon cancer data show substantial improvements over state-of-the-art WSL methods, and confirm the effect of our new regularizers. Our code is publicly available.
Transductive Information Maximization For Few-Shot Learning
Oct 05, 2020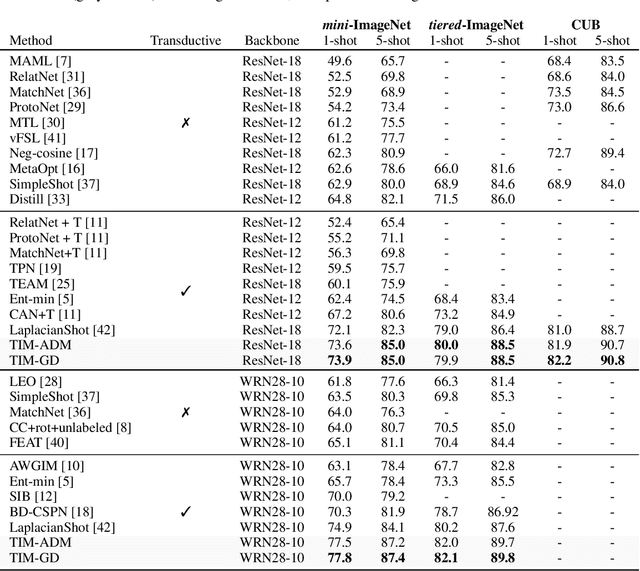
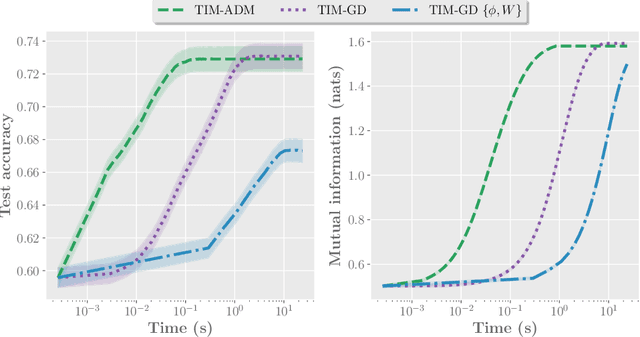
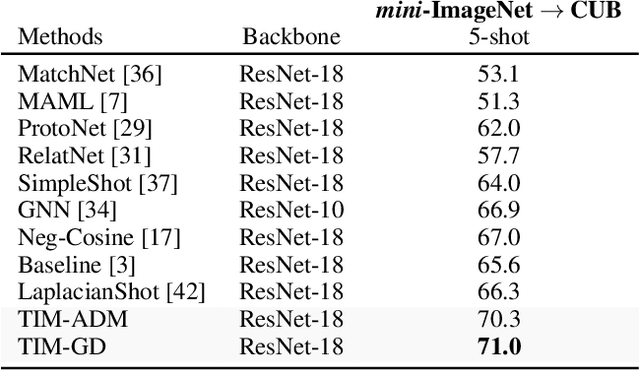
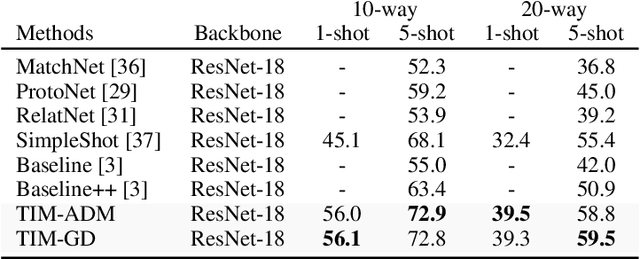
We introduce Transductive Infomation Maximization (TIM) for few-shot learning.Our method maximizes the mutual information between the query features andpredictions of a few-shot task, subject to supervision constraints from the supportset. Furthermore, we propose a new alternating direction solver for our mutual-information loss, which substantially speeds up transductive-inference convergenceover gradient-based optimization, while demonstrating similar accuracy perfor-mance. Following standard few-shot settings, our comprehensive experiments2demonstrate that TIM outperforms state-of-the-art methods significantly acrossall datasets and networks, while using simple cross-entropy training on the baseclasses, without resorting to complex meta-learning schemes. It consistently bringsbetween2%to5%improvement in accuracy over the best performing methods notonly on all the well-established few-shot benchmarks, but also on more challengingscenarios, with domain shifts and larger number of classes.
Metric learning: cross-entropy vs. pairwise losses
Mar 19, 2020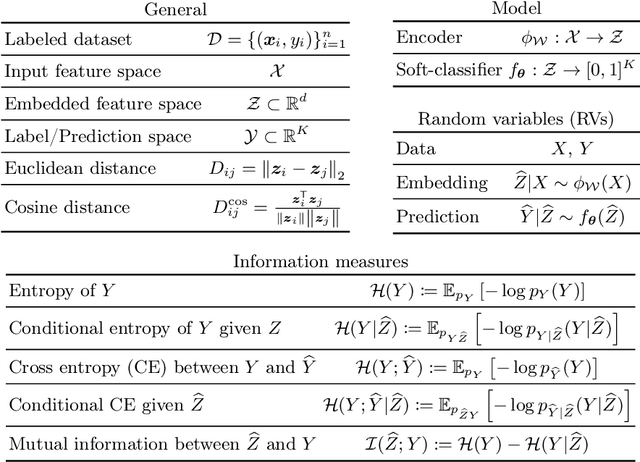
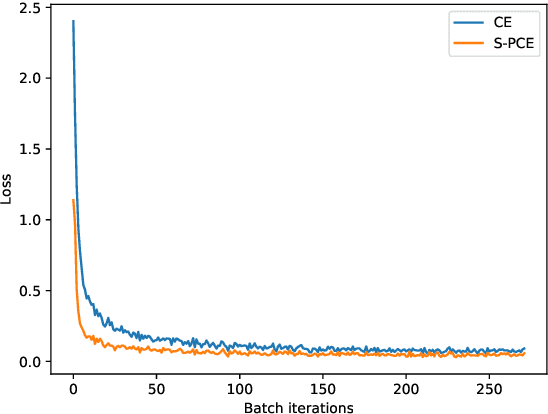


Recently, substantial research efforts in Deep Metric Learning (DML) focused on designing complex pairwise-distance losses and convoluted sample-mining and implementation strategies to ease optimization. The standard cross-entropy loss for classification has been largely overlooked in DML. On the surface, the cross-entropy may seem unrelated and irrelevant to metric learning as it does not explicitly involve pairwise distances. However, we provide a theoretical analysis that links the cross-entropy to several well-known and recent pairwise losses. Our connections are drawn from two different perspectives: one based on an explicit optimization insight; the other on discriminative and generative views of the mutual information between the labels and the learned features. First, we explicitly demonstrate that the cross-entropy is an upper bound on a new pairwise loss, which has a structure similar to various pairwise losses: it minimizes intra-class distances while maximizing inter-class distances. As a result, minimizing the cross-entropy can be seen as an approximate bound-optimization (or Majorize-Minimize) algorithm for minimizing this pairwise loss. Second, we show that, more generally, minimizing the cross-entropy is actually equivalent to maximizing the mutual information, to which we connect several well-known pairwise losses. These findings indicate that the cross-entropy represents a proxy for maximizing the mutual information -- as pairwise losses do -- without the need for complex sample-mining and optimization schemes. Furthermore, we show that various standard pairwise losses can be explicitly related to one another via bound relationships. Our experiments over four standard DML benchmarks (CUB200, Cars-196, Stanford Online Product and In-Shop) strongly support our findings. We consistently obtained state-of-the-art results, outperforming many recent and complex DML methods.
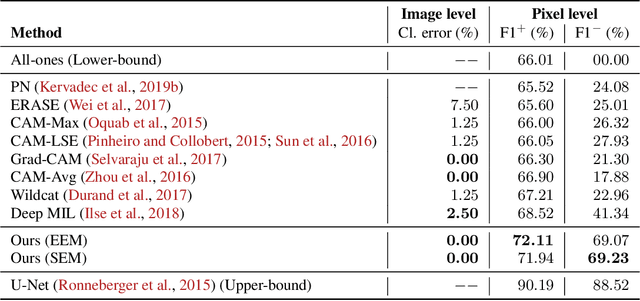
Deep weakly-supervised learning methods for classification and localization in histology images: a survey
Sep 26, 2019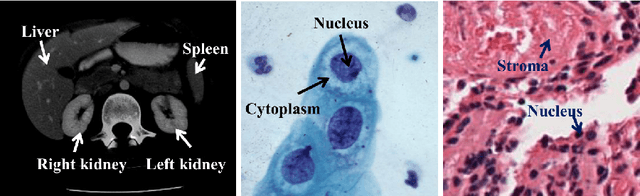


Using state-of-the-art deep learning models for the computer-assisted diagnosis of diseases like cancer raises several challenges related to the nature and availability of labeled histology images. In particular, cancer grading and localization in these images normally relies on both image- and pixel-level labels, the latter requiring a costly annotation process. In this survey, deep weakly-supervised learning (WSL) architectures are investigated to identify and locate diseases in histology image, without the need for pixel-level annotations. Given a training dataset with globally-annotated images, these models allow to simultaneously classify histology images, while localizing the corresponding regions of interest. These models are organized into two main approaches -- (1) bottom-up approaches (based on forward-pass information through a network, either by spatial pooling of representations/scores, or by detecting class regions), and (2) top-down approaches (based on backward-pass information within a network, inspired by human visual attention). Since relevant WSL models have mainly been developed in the computer vision community, and validated on natural scene images, we assess the extent to which they apply to histology images which have challenging properties, e.g., large size, non-salient and highly unstructured regions, stain heterogeneity, and coarse/ambiguous labels. The most relevant deep WSL models (e.g., CAM, WILDCAT and Deep MIL) are compared experimentally in terms of accuracy (classification and pixel-level localization) on several public benchmark histology datasets for breast and colon cancer (BACH ICIAR 2018, BreakHis, CAMELYON16, and GlaS). Results indicate that several deep learning models, and in particular WILDCAT and deep MIL can provide a high level of classification accuracy, although pixel-wise localization of cancer regions remains an issue for such images.