 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA self-training framework for glaucoma grading in OCT B-scans
Nov 23, 2021
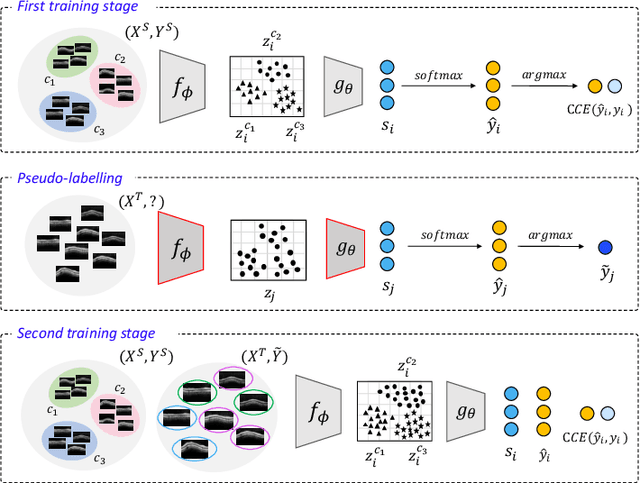
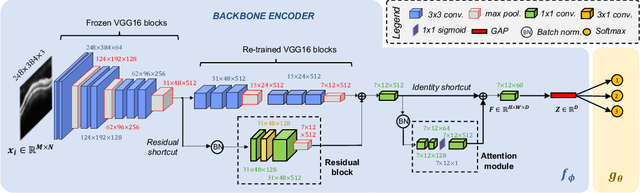
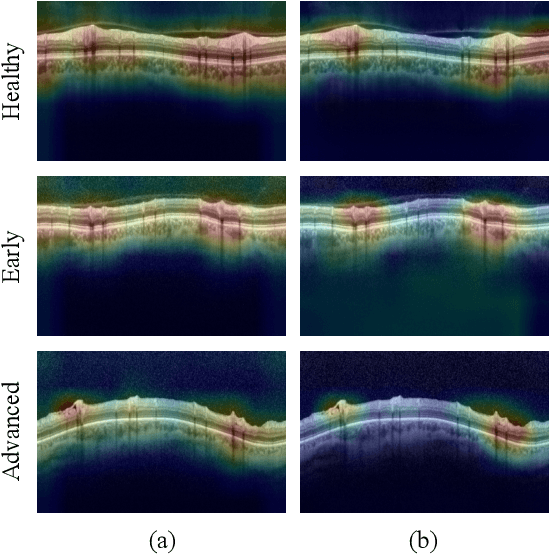
In this paper, we present a self-training-based framework for glaucoma grading using OCT B-scans under the presence of domain shift. Particularly, the proposed two-step learning methodology resorts to pseudo-labels generated during the first step to augment the training dataset on the target domain, which is then used to train the final target model. This allows transferring knowledge-domain from the unlabeled data. Additionally, we propose a novel glaucoma-specific backbone which introduces residual and attention modules via skip-connections to refine the embedding features of the latent space. By doing this, our model is capable of improving state-of-the-art from a quantitative and interpretability perspective. The reported results demonstrate that the proposed learning strategy can boost the performance of the model on the target dataset without incurring in additional annotation steps, by using only labels from the source examples. Our model consistently outperforms the baseline by 1-3% across different metrics and bridges the gap with respect to training the model on the labeled target data.
Transductive Information Maximization For Few-Shot Learning
Oct 05, 2020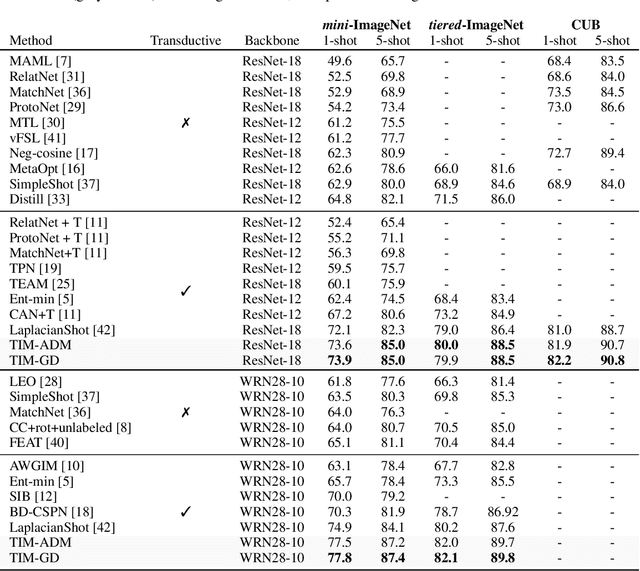
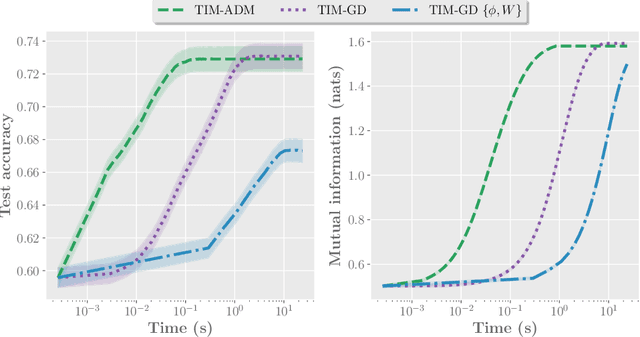
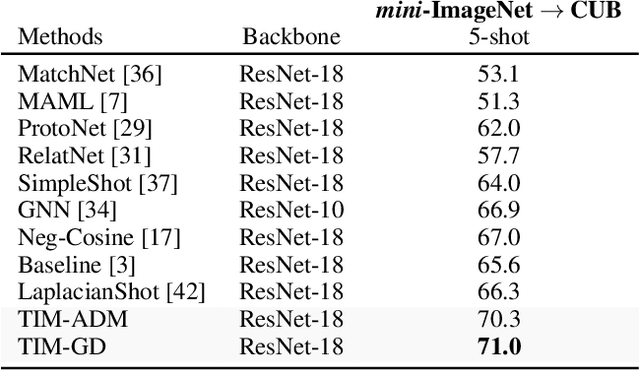
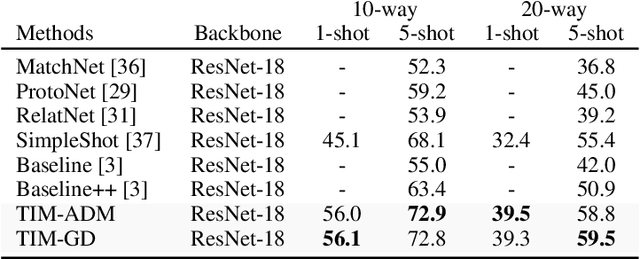
We introduce Transductive Infomation Maximization (TIM) for few-shot learning.Our method maximizes the mutual information between the query features andpredictions of a few-shot task, subject to supervision constraints from the supportset. Furthermore, we propose a new alternating direction solver for our mutual-information loss, which substantially speeds up transductive-inference convergenceover gradient-based optimization, while demonstrating similar accuracy perfor-mance. Following standard few-shot settings, our comprehensive experiments2demonstrate that TIM outperforms state-of-the-art methods significantly acrossall datasets and networks, while using simple cross-entropy training on the baseclasses, without resorting to complex meta-learning schemes. It consistently bringsbetween2%to5%improvement in accuracy over the best performing methods notonly on all the well-established few-shot benchmarks, but also on more challengingscenarios, with domain shifts and larger number of classes.
Cost-Sensitive Regularization for Diabetic Retinopathy Grading from Eye Fundus Images
Oct 01, 2020
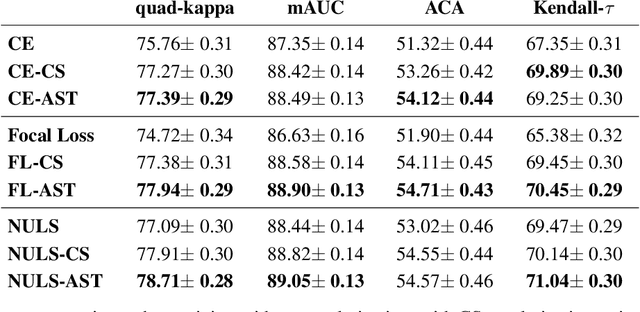

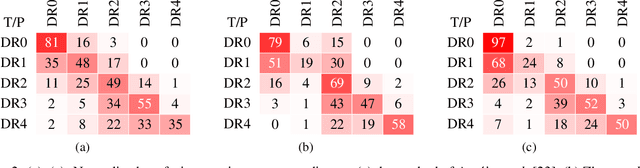
Assessing the degree of disease severity in biomedical images is a task similar to standard classification but constrained by an underlying structure in the label space. Such a structure reflects the monotonic relationship between different disease grades. In this paper, we propose a straightforward approach to enforce this constraint for the task of predicting Diabetic Retinopathy (DR) severity from eye fundus images based on the well-known notion of Cost-Sensitive classification. We expand standard classification losses with an extra term that acts as a regularizer, imposing greater penalties on predicted grades when they are farther away from the true grade associated to a particular image. Furthermore, we show how to adapt our method to the modelling of label noise in each of the sub-problems associated to DR grading, an approach we refer to as Atomic Sub-Task modeling. This yields models that can implicitly take into account the inherent noise present in DR grade annotations. Our experimental analysis on several public datasets reveals that, when a standard Convolutional Neural Network is trained using this simple strategy, improvements of 3-5\% of quadratic-weighted kappa scores can be achieved at a negligible computational cost. Code to reproduce our results is released at https://github.com/agaldran/cost_sensitive_loss_classification.
The Little W-Net That Could: State-of-the-Art Retinal Vessel Segmentation with Minimalistic Models
Sep 03, 2020
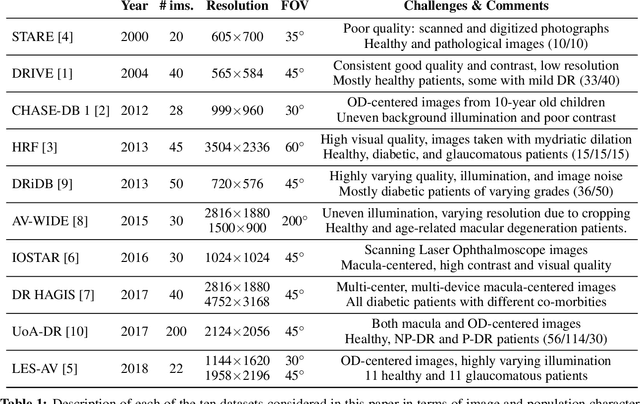
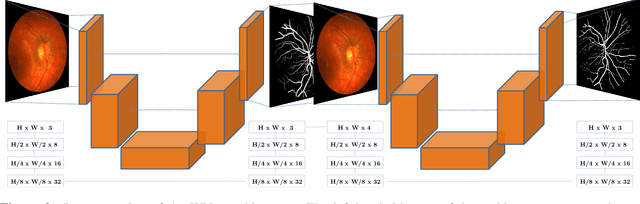
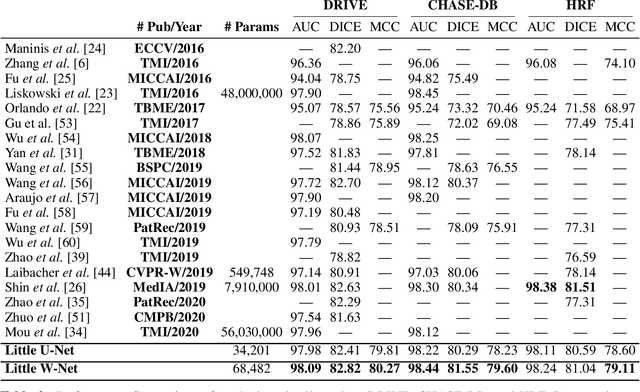
The segmentation of the retinal vasculature from eye fundus images represents one of the most fundamental tasks in retinal image analysis. Over recent years, increasingly complex approaches based on sophisticated Convolutional Neural Network architectures have been slowly pushing performance on well-established benchmark datasets. In this paper, we take a step back and analyze the real need of such complexity. Specifically, we demonstrate that a minimalistic version of a standard U-Net with several orders of magnitude less parameters, carefully trained and rigorously evaluated, closely approximates the performance of current best techniques. In addition, we propose a simple extension, dubbed W-Net, which reaches outstanding performance on several popular datasets, still using orders of magnitude less learnable weights than any previously published approach. Furthermore, we provide the most comprehensive cross-dataset performance analysis to date, involving up to 10 different databases. Our analysis demonstrates that the retinal vessel segmentation problem is far from solved when considering test images that differ substantially from the training data, and that this task represents an ideal scenario for the exploration of domain adaptation techniques. In this context, we experiment with a simple self-labeling strategy that allows us to moderately enhance cross-dataset performance, indicating that there is still much room for improvement in this area. Finally, we also test our approach on the Artery/Vein segmentation problem, where we again achieve results well-aligned with the state-of-the-art, at a fraction of the model complexity in recent literature. All the code to reproduce the results in this paper is released.