 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransductive Information Maximization For Few-Shot Learning
Paper and Code
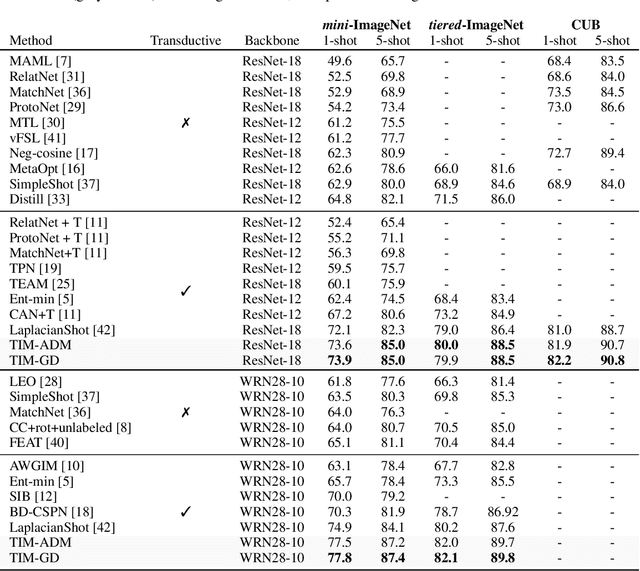
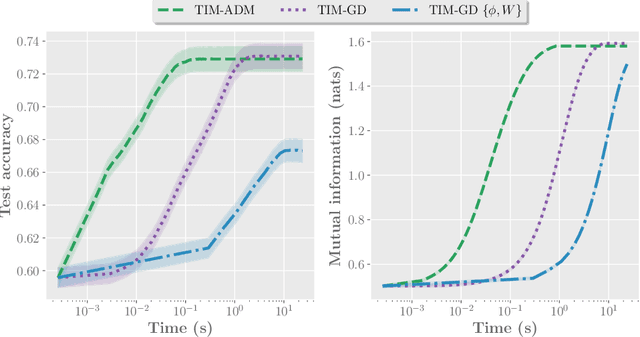
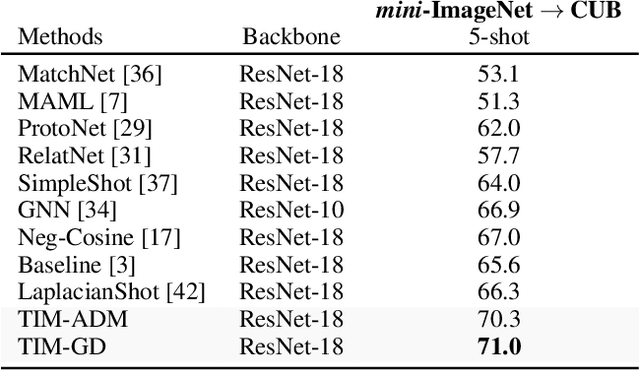
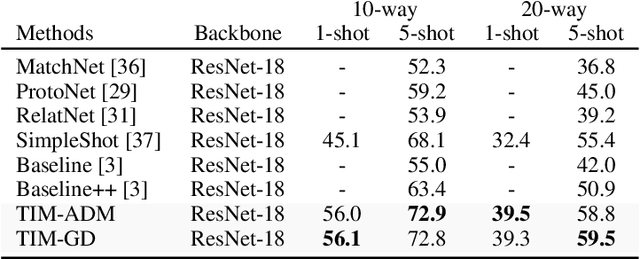
We introduce Transductive Infomation Maximization (TIM) for few-shot learning.Our method maximizes the mutual information between the query features andpredictions of a few-shot task, subject to supervision constraints from the supportset. Furthermore, we propose a new alternating direction solver for our mutual-information loss, which substantially speeds up transductive-inference convergenceover gradient-based optimization, while demonstrating similar accuracy perfor-mance. Following standard few-shot settings, our comprehensive experiments2demonstrate that TIM outperforms state-of-the-art methods significantly acrossall datasets and networks, while using simple cross-entropy training on the baseclasses, without resorting to complex meta-learning schemes. It consistently bringsbetween2%to5%improvement in accuracy over the best performing methods notonly on all the well-established few-shot benchmarks, but also on more challengingscenarios, with domain shifts and larger number of classes.