 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes It Tie Out? Towards Autonomous Legal Agents in Venture Capital
Dec 21, 2025Before closing venture capital financing rounds, lawyers conduct diligence that includes tying out the capitalization table: verifying that every security (for example, shares, options, warrants) and issuance term (for example, vesting schedules, acceleration triggers, transfer restrictions) is supported by large sets of underlying legal documentation. While LLMs continue to improve on legal benchmarks, specialized legal workflows, such as capitalization tie-out, remain out of reach even for strong agentic systems. The task requires multi-document reasoning, strict evidence traceability, and deterministic outputs that current approaches fail to reliably deliver. We characterize capitalization tie-out as an instance of a real-world benchmark for legal AI, analyze and compare the performance of existing agentic systems, and propose a world model architecture toward tie-out automation-and more broadly as a foundation for applied legal intelligence.
EOL: Transductive Few-Shot Open-Set Recognition by Enhancing Outlier Logits
Aug 04, 2024



In Few-Shot Learning (FSL), models are trained to recognise unseen objects from a query set, given a few labelled examples from a support set. In standard FSL, models are evaluated on query instances sampled from the same class distribution of the support set. In this work, we explore the more nuanced and practical challenge of Open-Set Few-Shot Recognition (OSFSL). Unlike standard FSL, OSFSL incorporates unknown classes into the query set, thereby requiring the model not only to classify known classes but also to identify outliers. Building on the groundwork laid by previous studies, we define a novel transductive inference technique that leverages the InfoMax principle to exploit the unlabelled query set. We called our approach the Enhanced Outlier Logit (EOL) method. EOL refines class prototype representations through model calibration, effectively balancing the inlier-outlier ratio. This calibration enhances pseudo-label accuracy for the query set and improves the optimisation objective within the transductive inference process. We provide a comprehensive empirical evaluation demonstrating that EOL consistently surpasses traditional methods, recording performance improvements ranging from approximately $+1.3%$ to $+6.3%$ across a variety of classification and outlier detection metrics and benchmarks, even in the presence of inlier-outlier imbalance.
SaulLM-54B & SaulLM-141B: Scaling Up Domain Adaptation for the Legal Domain
Jul 28, 2024



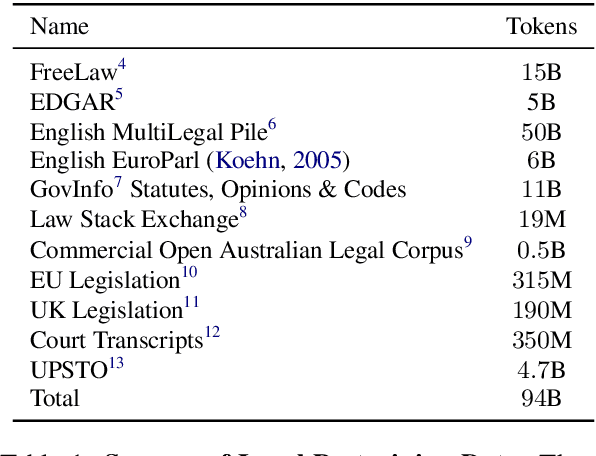
In this paper, we introduce SaulLM-54B and SaulLM-141B, two large language models (LLMs) tailored for the legal sector. These models, which feature architectures of 54 billion and 141 billion parameters, respectively, are based on the Mixtral architecture. The development of SaulLM-54B and SaulLM-141B is guided by large-scale domain adaptation, divided into three strategies: (1) the exploitation of continued pretraining involving a base corpus that includes over 540 billion of legal tokens, (2) the implementation of a specialized legal instruction-following protocol, and (3) the alignment of model outputs with human preferences in legal interpretations. The integration of synthetically generated data in the second and third steps enhances the models' capabilities in interpreting and processing legal texts, effectively reaching state-of-the-art performance and outperforming previous open-source models on LegalBench-Instruct. This work explores the trade-offs involved in domain-specific adaptation at this scale, offering insights that may inform future studies on domain adaptation using strong decoder models. Building upon SaulLM-7B, this study refines the approach to produce an LLM better equipped for legal tasks. We are releasing base, instruct, and aligned versions on top of SaulLM-54B and SaulLM-141B under the MIT License to facilitate reuse and collaborative research.
LP++: A Surprisingly Strong Linear Probe for Few-Shot CLIP
Apr 02, 2024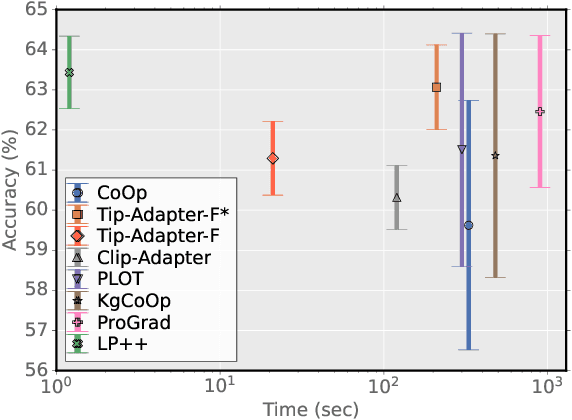
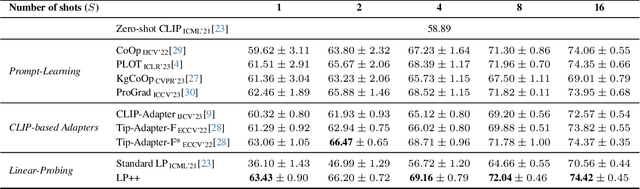
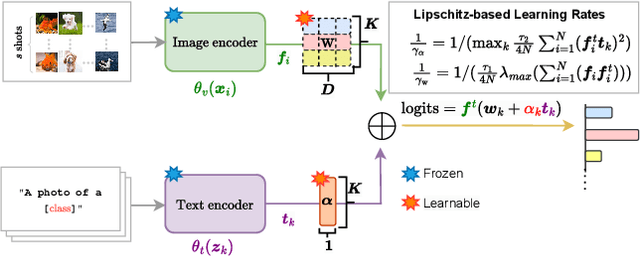
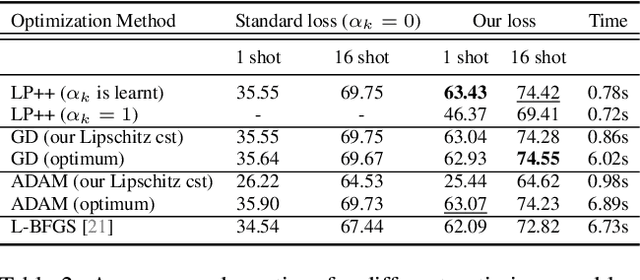
In a recent, strongly emergent literature on few-shot CLIP adaptation, Linear Probe (LP) has been often reported as a weak baseline. This has motivated intensive research building convoluted prompt learning or feature adaptation strategies. In this work, we propose and examine from convex-optimization perspectives a generalization of the standard LP baseline, in which the linear classifier weights are learnable functions of the text embedding, with class-wise multipliers blending image and text knowledge. As our objective function depends on two types of variables, i.e., the class visual prototypes and the learnable blending parameters, we propose a computationally efficient block coordinate Majorize-Minimize (MM) descent algorithm. In our full-batch MM optimizer, which we coin LP++, step sizes are implicit, unlike standard gradient descent practices where learning rates are intensively searched over validation sets. By examining the mathematical properties of our loss (e.g., Lipschitz gradient continuity), we build majorizing functions yielding data-driven learning rates and derive approximations of the loss's minima, which provide data-informed initialization of the variables. Our image-language objective function, along with these non-trivial optimization insights and ingredients, yields, surprisingly, highly competitive few-shot CLIP performances. Furthermore, LP++ operates in black-box, relaxes intensive validation searches for the optimization hyper-parameters, and runs orders-of-magnitudes faster than state-of-the-art few-shot CLIP adaptation methods. Our code is available at: \url{https://github.com/FereshteShakeri/FewShot-CLIP-Strong-Baseline.git}.
SaulLM-7B: A pioneering Large Language Model for Law
Mar 07, 2024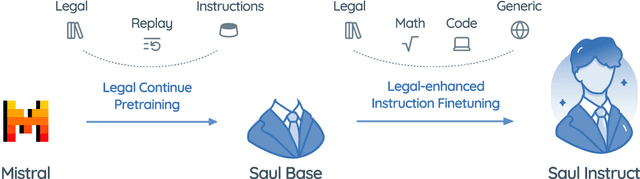


In this paper, we introduce SaulLM-7B, a large language model (LLM) tailored for the legal domain. With 7 billion parameters, SaulLM-7B is the first LLM designed explicitly for legal text comprehension and generation. Leveraging the Mistral 7B architecture as its foundation, SaulLM-7B is trained on an English legal corpus of over 30 billion tokens. SaulLM-7B exhibits state-of-the-art proficiency in understanding and processing legal documents. Additionally, we present a novel instructional fine-tuning method that leverages legal datasets to further enhance SaulLM-7B's performance in legal tasks. SaulLM-7B is released under the MIT License.
Transductive Learning for Textual Few-Shot Classification in API-based Embedding Models
Oct 21, 2023



Proprietary and closed APIs are becoming increasingly common to process natural language, and are impacting the practical applications of natural language processing, including few-shot classification. Few-shot classification involves training a model to perform a new classification task with a handful of labeled data. This paper presents three contributions. First, we introduce a scenario where the embedding of a pre-trained model is served through a gated API with compute-cost and data-privacy constraints. Second, we propose a transductive inference, a learning paradigm that has been overlooked by the NLP community. Transductive inference, unlike traditional inductive learning, leverages the statistics of unlabeled data. We also introduce a new parameter-free transductive regularizer based on the Fisher-Rao loss, which can be used on top of the gated API embeddings. This method fully utilizes unlabeled data, does not share any label with the third-party API provider and could serve as a baseline for future research. Third, we propose an improved experimental setting and compile a benchmark of eight datasets involving multiclass classification in four different languages, with up to 151 classes. We evaluate our methods using eight backbone models, along with an episodic evaluation over 1,000 episodes, which demonstrate the superiority of transductive inference over the standard inductive setting.
Bag of Tricks for Fully Test-Time Adaptation
Oct 03, 2023



Fully Test-Time Adaptation (TTA), which aims at adapting models to data drifts, has recently attracted wide interest. Numerous tricks and techniques have been proposed to ensure robust learning on arbitrary streams of unlabeled data. However, assessing the true impact of each individual technique and obtaining a fair comparison still constitutes a significant challenge. To help consolidate the community's knowledge, we present a categorization of selected orthogonal TTA techniques, including small batch normalization, stream rebalancing, reliable sample selection, and network confidence calibration. We meticulously dissect the effect of each approach on different scenarios of interest. Through our analysis, we shed light on trade-offs induced by those techniques between accuracy, the computational power required, and model complexity. We also uncover the synergy that arises when combining techniques and are able to establish new state-of-the-art results.
In Search for a Generalizable Method for Source Free Domain Adaptation
Feb 13, 2023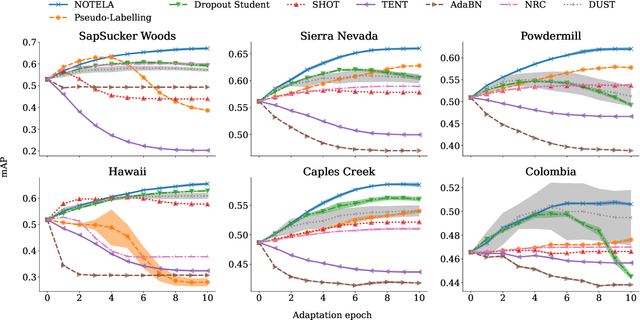
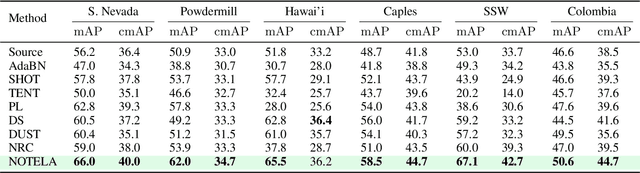
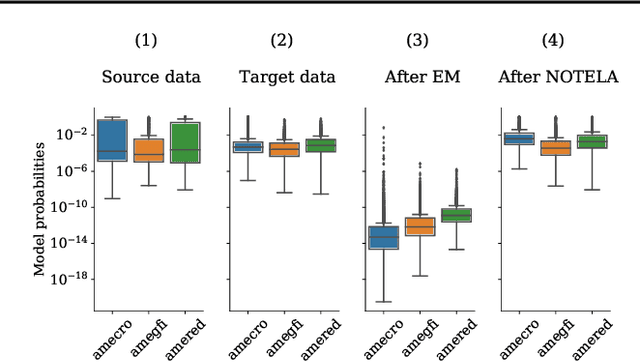
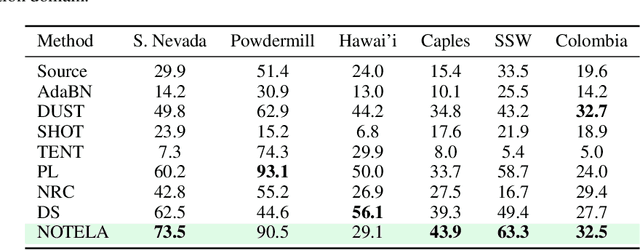
Source-free domain adaptation (SFDA) is compelling because it allows adapting an off-the-shelf model to a new domain using only unlabelled data. In this work, we apply existing SFDA techniques to a challenging set of naturally-occurring distribution shifts in bioacoustics, which are very different from the ones commonly studied in computer vision. We find existing methods perform differently relative to each other than observed in vision benchmarks, and sometimes perform worse than no adaptation at all. We propose a new simple method which outperforms the existing methods on our new shifts while exhibiting strong performance on a range of vision datasets. Our findings suggest that existing SFDA methods are not as generalizable as previously thought and that considering diverse modalities can be a useful avenue for designing more robust models.
Open-Set Likelihood Maximization for Few-Shot Learning
Jan 20, 2023We tackle the Few-Shot Open-Set Recognition (FSOSR) problem, i.e. classifying instances among a set of classes for which we only have a few labeled samples, while simultaneously detecting instances that do not belong to any known class. We explore the popular transductive setting, which leverages the unlabelled query instances at inference. Motivated by the observation that existing transductive methods perform poorly in open-set scenarios, we propose a generalization of the maximum likelihood principle, in which latent scores down-weighing the influence of potential outliers are introduced alongside the usual parametric model. Our formulation embeds supervision constraints from the support set and additional penalties discouraging overconfident predictions on the query set. We proceed with a block-coordinate descent, with the latent scores and parametric model co-optimized alternately, thereby benefiting from each other. We call our resulting formulation \textit{Open-Set Likelihood Optimization} (OSLO). OSLO is interpretable and fully modular; it can be applied on top of any pre-trained model seamlessly. Through extensive experiments, we show that our method surpasses existing inductive and transductive methods on both aspects of open-set recognition, namely inlier classification and outlier detection.
A Strong Baseline for Generalized Few-Shot Semantic Segmentation
Nov 25, 2022This paper introduces a generalized few-shot segmentation framework with a straightforward training process and an easy-to-optimize inference phase. In particular, we propose a simple yet effective model based on the well-known InfoMax principle, where the Mutual Information (MI) between the learned feature representations and their corresponding predictions is maximized. In addition, the terms derived from our MI-based formulation are coupled with a knowledge distillation term to retain the knowledge on base classes. With a simple training process, our inference model can be applied on top of any segmentation network trained on base classes. The proposed inference yields substantial improvements on the popular few-shot segmentation benchmarks PASCAL-$5^i$ and COCO-$20^i$. Particularly, for novel classes, the improvement gains range from 5% to 20% (PASCAL-$5^i$) and from 2.5% to 10.5% (COCO-$20^i$) in the 1-shot and 5-shot scenarios, respectively. Furthermore, we propose a more challenging setting, where performance gaps are further exacerbated. Our code is publicly available at https://github.com/sinahmr/DIaM.