 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of Tricks for Fully Test-Time Adaptation
Oct 03, 2023



Fully Test-Time Adaptation (TTA), which aims at adapting models to data drifts, has recently attracted wide interest. Numerous tricks and techniques have been proposed to ensure robust learning on arbitrary streams of unlabeled data. However, assessing the true impact of each individual technique and obtaining a fair comparison still constitutes a significant challenge. To help consolidate the community's knowledge, we present a categorization of selected orthogonal TTA techniques, including small batch normalization, stream rebalancing, reliable sample selection, and network confidence calibration. We meticulously dissect the effect of each approach on different scenarios of interest. Through our analysis, we shed light on trade-offs induced by those techniques between accuracy, the computational power required, and model complexity. We also uncover the synergy that arises when combining techniques and are able to establish new state-of-the-art results.
Automatic Data Augmentation Learning using Bilevel Optimization for Histopathological Images
Jul 21, 2023



Training a deep learning model to classify histopathological images is challenging, because of the color and shape variability of the cells and tissues, and the reduced amount of available data, which does not allow proper learning of those variations. Variations can come from the image acquisition process, for example, due to different cell staining protocols or tissue deformation. To tackle this challenge, Data Augmentation (DA) can be used during training to generate additional samples by applying transformations to existing ones, to help the model become invariant to those color and shape transformations. The problem with DA is that it is not only dataset-specific but it also requires domain knowledge, which is not always available. Without this knowledge, selecting the right transformations can only be done using heuristics or through a computationally demanding search. To address this, we propose an automatic DA learning method. In this method, the DA parameters, i.e. the transformation parameters needed to improve the model training, are considered learnable and are learned automatically using a bilevel optimization approach in a quick and efficient way using truncated backpropagation. We validated the method on six different datasets. Experimental results show that our model can learn color and affine transformations that are more helpful to train an image classifier than predefined DA transformations, which are also more expensive as they need to be selected before the training by grid search on a validation set. We also show that similarly to a model trained with RandAugment, our model has also only a few method-specific hyperparameters to tune but is performing better. This makes our model a good solution for learning the best DA parameters, especially in the context of histopathological images, where defining potentially useful transformation heuristically is not trivial.
Learning Data Augmentation with Online Bilevel Optimization for Image Classification
Jun 25, 2020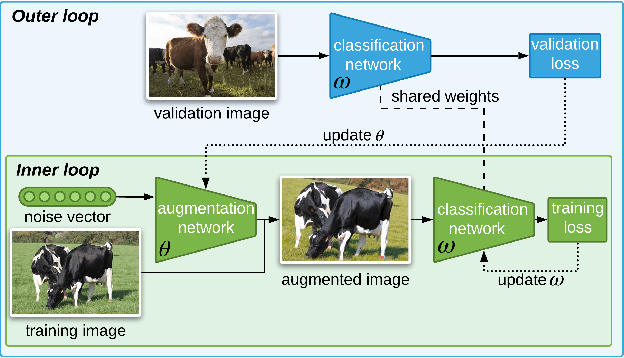
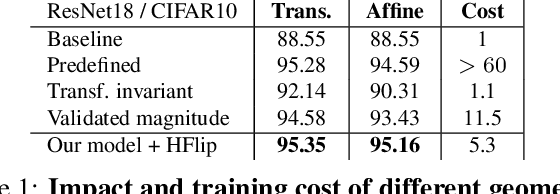
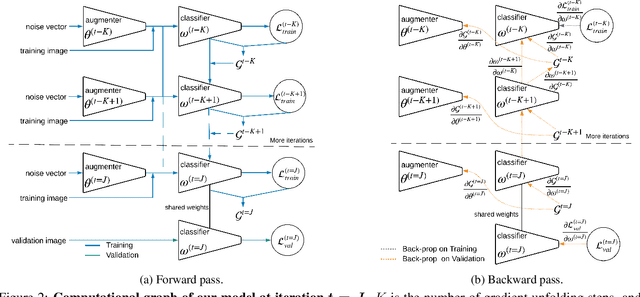
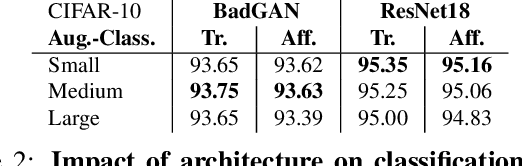
Data augmentation is a key practice in machine learning for improving generalization performance. However, finding the best data augmentation hyperparameters requires domain knowledge or a computationally demanding search. We address this issue by proposing an efficient approach to automatically train a network that learns an effective distribution of transformations to improve its generalization score. Using bilevel optimization, we directly optimize the data augmentation parameters using a validation set. This framework can be used as a general solution to learn the optimal data augmentation jointly with an end task model like a classifier. Results show that our joint training method produces an image classification accuracy that is comparable to or better than carefully hand-crafted data augmentation. Yet, it does not need an expensive external validation loop on the data augmentation hyperparameters.
Adversarial Learning of General Transformations for Data Augmentation
Sep 21, 2019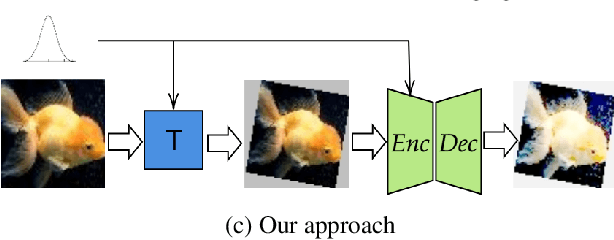
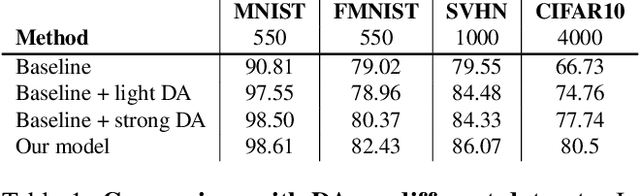
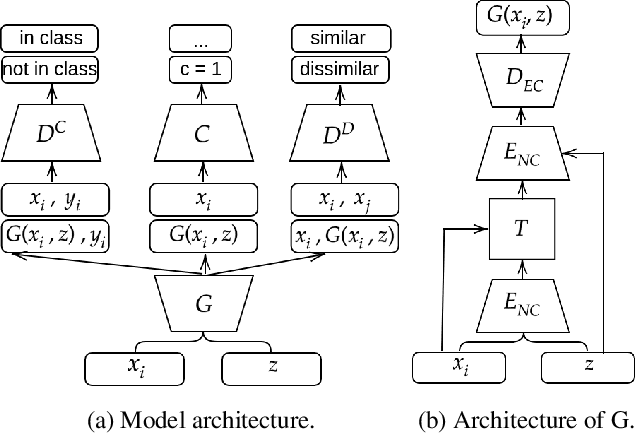
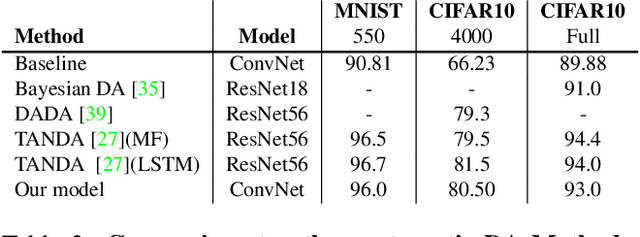
Data augmentation (DA) is fundamental against overfitting in large convolutional neural networks, especially with a limited training dataset. In images, DA is usually based on heuristic transformations, like geometric or color transformations. Instead of using predefined transformations, our work learns data augmentation directly from the training data by learning to transform images with an encoder-decoder architecture combined with a spatial transformer network. The transformed images still belong to the same class but are new, more complex samples for the classifier. Our experiments show that our approach is better than previous generative data augmentation methods, and comparable to predefined transformation methods when training an image classifier.