 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProMi: An Efficient Prototype-Mixture Baseline for Few-Shot Segmentation with Bounding-Box Annotations
May 18, 2025

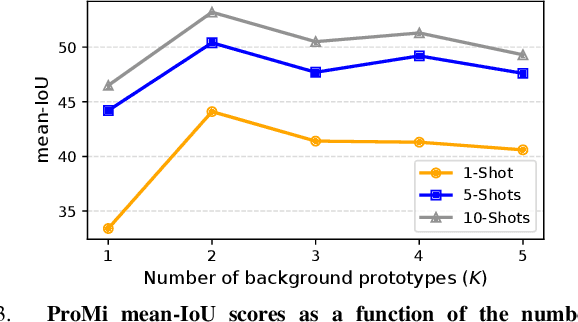

In robotics applications, few-shot segmentation is crucial because it allows robots to perform complex tasks with minimal training data, facilitating their adaptation to diverse, real-world environments. However, pixel-level annotations of even small amount of images is highly time-consuming and costly. In this paper, we present a novel few-shot binary segmentation method based on bounding-box annotations instead of pixel-level labels. We introduce, ProMi, an efficient prototype-mixture-based method that treats the background class as a mixture of distributions. Our approach is simple, training-free, and effective, accommodating coarse annotations with ease. Compared to existing baselines, ProMi achieves the best results across different datasets with significant gains, demonstrating its effectiveness. Furthermore, we present qualitative experiments tailored to real-world mobile robot tasks, demonstrating the applicability of our approach in such scenarios. Our code: https://github.com/ThalesGroup/promi.
Bag of Tricks for Fully Test-Time Adaptation
Oct 03, 2023



Fully Test-Time Adaptation (TTA), which aims at adapting models to data drifts, has recently attracted wide interest. Numerous tricks and techniques have been proposed to ensure robust learning on arbitrary streams of unlabeled data. However, assessing the true impact of each individual technique and obtaining a fair comparison still constitutes a significant challenge. To help consolidate the community's knowledge, we present a categorization of selected orthogonal TTA techniques, including small batch normalization, stream rebalancing, reliable sample selection, and network confidence calibration. We meticulously dissect the effect of each approach on different scenarios of interest. Through our analysis, we shed light on trade-offs induced by those techniques between accuracy, the computational power required, and model complexity. We also uncover the synergy that arises when combining techniques and are able to establish new state-of-the-art results.
MoP-CLIP: A Mixture of Prompt-Tuned CLIP Models for Domain Incremental Learning
Jul 11, 2023



Despite the recent progress in incremental learning, addressing catastrophic forgetting under distributional drift is still an open and important problem. Indeed, while state-of-the-art domain incremental learning (DIL) methods perform satisfactorily within known domains, their performance largely degrades in the presence of novel domains. This limitation hampers their generalizability, and restricts their scalability to more realistic settings where train and test data are drawn from different distributions. To address these limitations, we present a novel DIL approach based on a mixture of prompt-tuned CLIP models (MoP-CLIP), which generalizes the paradigm of S-Prompting to handle both in-distribution and out-of-distribution data at inference. In particular, at the training stage we model the features distribution of every class in each domain, learning individual text and visual prompts to adapt to a given domain. At inference, the learned distributions allow us to identify whether a given test sample belongs to a known domain, selecting the correct prompt for the classification task, or from an unseen domain, leveraging a mixture of the prompt-tuned CLIP models. Our empirical evaluation reveals the poor performance of existing DIL methods under domain shift, and suggests that the proposed MoP-CLIP performs competitively in the standard DIL settings while outperforming state-of-the-art methods in OOD scenarios. These results demonstrate the superiority of MoP-CLIP, offering a robust and general solution to the problem of domain incremental learning.
Mutual Information-based Generalized Category Discovery
Dec 01, 2022
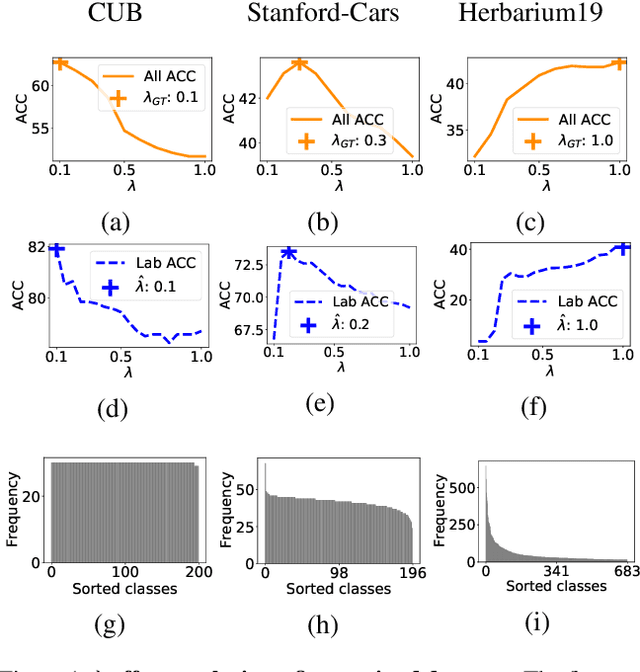


We introduce an information-maximization approach for the Generalized Category Discovery (GCD) problem. Specifically, we explore a parametric family of loss functions evaluating the mutual information between the features and the labels, and find automatically the one that maximizes the predictive performances. Furthermore, we introduce the Elbow Maximum Centroid-Shift (EMaCS) technique, which estimates the number of classes in the unlabeled set. We report comprehensive experiments, which show that our mutual information-based approach (MIB) is both versatile and highly competitive under various GCD scenarios. The gap between the proposed approach and the existing methods is significant, more so when dealing with fine-grained classification problems. Our code: \url{https://github.com/fchiaroni/Mutual-Information-Based-GCD}.
Simplex Clustering via sBeta with Applications to Online Adjustment of Black-Box Predictions
Aug 02, 2022
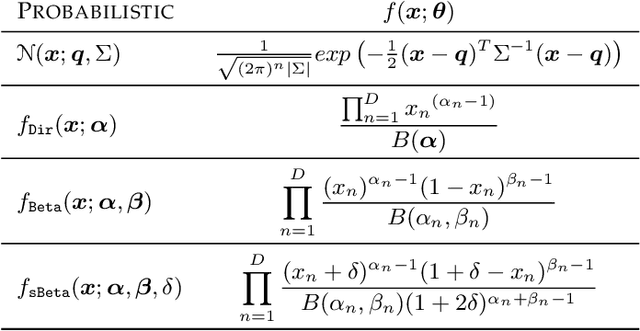
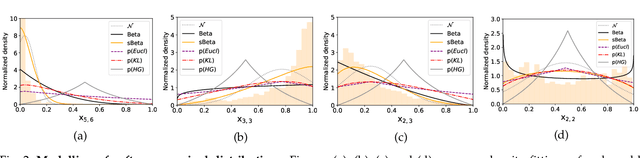
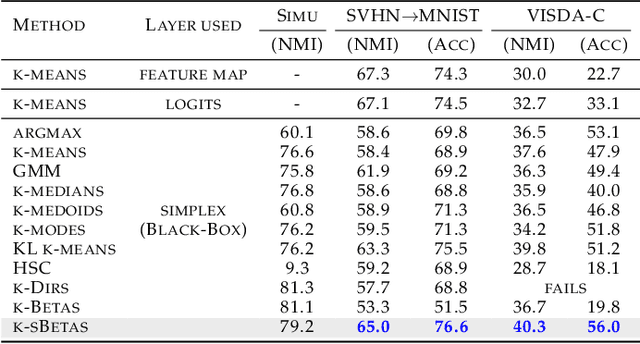
We explore clustering the softmax predictions of deep neural networks and introduce a novel probabilistic clustering method, referred to as k-sBetas. In the general context of clustering distributions, the existing methods focused on exploring distortion measures tailored to simplex data, such as the KL divergence, as alternatives to the standard Euclidean distance. We provide a general perspective of clustering distributions, which emphasizes that the statistical models underlying distortion-based methods may not be descriptive enough. Instead, we optimize a mixed-variable objective measuring the conformity of data within each cluster to the introduced sBeta density function, whose parameters are constrained and estimated jointly with binary assignment variables. Our versatile formulation approximates a variety of parametric densities for modeling cluster data, and enables to control the cluster-balance bias. This yields highly competitive performances for efficient unsupervised adjustment of black-box predictions in a variety of scenarios, including one-shot classification and unsupervised domain adaptation in real-time for road segmentation. Implementation is available at https://github.com/fchiaroni/Clustering_Softmax_Predictions.
Self-supervised classification of dynamic obstacles using the temporal information provided by videos
Oct 21, 2019



Nowadays, autonomous driving systems can detect, segment, and classify the surrounding obstacles using a monocular camera. However, state-of-the-art methods solving these tasks generally perform a fully supervised learning process and require a large amount of training labeled data. On another note, some self-supervised learning approaches can deal with detection and segmentation of dynamic obstacles using the temporal information available in video sequences. In this work, we propose in addition to classifiy the detected obstacles depending on their motion pattern. We present a novel self-supervised framework consisting of learning offline clusters from temporal patch sequences and using these clusters as pseudo labels to train a real-time image classifier. The presented model outperforms state-of-the-art unsupervised image classification methods on BDD100K dataset.
Generating Relevant Counter-Examples from a Positive Unlabeled Dataset for Image Classification
Oct 04, 2019

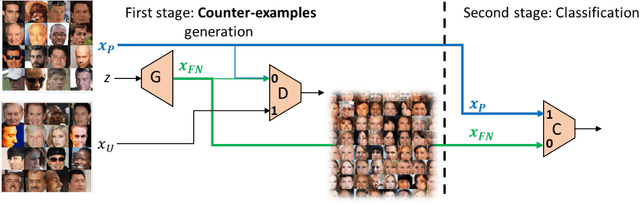

With surge of available but unlabeled data, Positive Unlabeled (PU) learning is becoming a thriving challenge. This work deals with this demanding task for which recent GAN-based PU approaches have demonstrated promising results. Generative adversarial Networks (GANs) are not hampered by deterministic bias or need for specific dimensionality. However, existing GAN-based PU approaches also present some drawbacks such as sensitive dependence to prior knowledge, a cumbersome architecture or first-stage overfitting. To settle these issues, we propose to incorporate a biased PU risk within the standard GAN discriminator loss function. In this manner, the discriminator is constrained to request the generator to converge towards the unlabeled samples distribution while diverging from the positive samples distribution. This enables the proposed model, referred to as D-GAN, to exclusively learn the counter-examples distribution without prior knowledge. Experiments demonstrate that our approach outperforms state-of-the-art PU methods without prior by overcoming their issues.
Self-supervised learning for autonomous vehicles perception: A conciliation between analytical and learning methods
Oct 03, 2019

This article mainly aims at motivating more investigations on self-supervised learning (SSL) perception techniques and their applications in autonomous driving. Such approaches are of broad interest as they can improve analytical methods performances, for example to perceive farther and more accurately spatially or temporally. In the meantime, they can also reduce the need of hand-labeled training data for learning methods, while offering the possibility to update the learning models into an online process. This can help an autonomous system to deal with unexpected changing conditions in the ego-vehicle environment. In all, this article firstly highlights the analytical and learning tools which may be interesting for improving or developping SSL techniques. Then, it presents the insights and correlations between existing autonomous driving perception SSL techniques, and some of their remaining limitations opening up some future research perspectives.