 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Entropy-based Active Learning for Fair Brain Segmentation
May 03, 2026Active learning (AL) has emerged as a crucial strategy for reducing the prohibitive costs associated with medical image segmentation. However, standard uncertainty-based AL methods typically focus on maximizing performance metrics, ignoring performance disparities or fairness across groups with sensitive attributes. While fair active learning has been explored in classification tasks, its intersection with medical image segmentation remains unaddressed. In this work, we introduced a fairness-aware active learning framework with a Weighted Entropy selection strategy that modulates uncertainty based on current group-specific performance estimates on the labeled set. To decouple true epistemic uncertainty from anatomical volume variances, we further utilized a masked, scaled entropy restricted to the region of interest. The framework was evaluated on synthetic T1-weighted brain MRIs with controlled left caudate bias in both strong and weak bias settings. A 3D U-Net was trained to segment the left caudate under several AL strategies, starting from both demographically balanced and strongly imbalanced initial labeled sets. Experiments demonstrated that our method markedly reduces performance disparities between groups compared to random sampling and standard uncertainty sampling. By prioritizing poorly segmented subgroups during the AL cycles, our method consistently achieved the highest equity-scaled performance and reduced the disparity metric by 75% (strong bias) and 86% (weak bias) relative to standard entropy at the final budget. Overall, this work is among the first studies on fair AL for medical image segmentation, offering an efficient strategy to train more equitable models in resource-constrained environments.
Locality-Attending Vision Transformer
Mar 05, 2026Vision transformers have demonstrated remarkable success in classification by leveraging global self-attention to capture long-range dependencies. However, this same mechanism can obscure fine-grained spatial details crucial for tasks such as segmentation. In this work, we seek to enhance segmentation performance of vision transformers after standard image-level classification training. More specifically, we present a simple yet effective add-on that improves performance on segmentation tasks while retaining vision transformers' image-level recognition capabilities. In our approach, we modulate the self-attention with a learnable Gaussian kernel that biases the attention toward neighboring patches. We further refine the patch representations to learn better embeddings at patch positions. These modifications encourage tokens to focus on local surroundings and ensure meaningful representations at spatial positions, while still preserving the model's ability to incorporate global information. Experiments demonstrate the effectiveness of our modifications, evidenced by substantial segmentation gains on three benchmarks (e.g., over 6% and 4% on ADE20K for ViT Tiny and Base), without changing the training regime or sacrificing classification performance. The code is available at https://github.com/sinahmr/LocAtViT/.
OCTOPUS: Enhancing the Spatial-Awareness of Vision SSMs with Multi-Dimensional Scans and Traversal Selection
Jan 31, 2026State space models (SSMs) have recently emerged as an alternative to transformers due to their unique ability of modeling global relationships in text with linear complexity. However, their success in vision tasks has been limited due to their causal formulation, which is suitable for sequential text but detrimental in the spatial domain where causality breaks the inherent spatial relationships among pixels or patches. As a result, standard SSMs fail to capture local spatial coherence, often linking non-adjacent patches while ignoring neighboring ones that are visually correlated. To address these limitations, we introduce OCTOPUS , a novel architecture that preserves both global context and local spatial structure within images, while maintaining the linear complexity of SSMs. OCTOPUS performs discrete reoccurrence along eight principal orientations, going forward or backward in the horizontal, vertical, and diagonal directions, allowing effective information exchange across all spatially connected regions while maintaining independence among unrelated patches. This design enables multi-directional recurrence, capturing both global context and local spatial structure with SSM-level efficiency. In our classification and segmentation benchmarks, OCTOPUS demonstrates notable improvements in boundary preservation and region consistency, as evident from the segmentation results, while maintaining relatively better classification accuracy compared to existing V-SSM based models. These results suggest that OCTOPUS appears as a foundation method for multi-directional recurrence as a scalable and effective mechanism for building spatially aware and computationally efficient vision architectures.
SPARK: Stochastic Propagation via Affinity-guided Random walK for training-free unsupervised segmentation
Jan 31, 2026We argue that existing training-free segmentation methods rely on an implicit and limiting assumption, that segmentation is a spectral graph partitioning problem over diffusion-derived affinities. Such approaches, based on global graph partitioning and eigenvector-based formulations of affinity matrices, suffer from several fundamental drawbacks, they require pre-selecting the number of clusters, induce boundary oversmoothing due to spectral relaxation, and remain highly sensitive to noisy or multi-modal affinity distributions. Moreover, many prior works neglect the importance of local neighborhood structure, which plays a crucial role in stabilizing affinity propagation and preserving fine-grained contours. To address these limitations, we reformulate training-free segmentation as a stochastic flow equilibrium problem over diffusion-induced affinity graphs, where segmentation emerges from a stochastic propagation process that integrates global diffusion attention with local neighborhoods extracted from stable diffusion, yielding a sparse yet expressive affinity structure. Building on this formulation, we introduce a Markov propagation scheme that performs random-walk-based label diffusion with an adaptive pruning strategy that suppresses unreliable transitions while reinforcing confident affinity paths. Experiments across seven widely used semantic segmentation benchmarks demonstrate that our method achieves state-of-the-art zero-shot performance, producing sharper boundaries, more coherent regions, and significantly more stable masks compared to prior spectral-clustering-based approaches.
Anatomically-aware conformal prediction for medical image segmentation with random walks
Jan 26, 2026The reliable deployment of deep learning in medical imaging requires uncertainty quantification that provides rigorous error guarantees while remaining anatomically meaningful. Conformal prediction (CP) is a powerful distribution-free framework for constructing statistically valid prediction intervals. However, standard applications in segmentation often ignore anatomical context, resulting in fragmented, spatially incoherent, and over-segmented prediction sets that limit clinical utility. To bridge this gap, this paper proposes Random-Walk Conformal Prediction (RW-CP), a model-agnostic framework which can be added on top of any segmentation method. RW-CP enforces spatial coherence to generate anatomically valid sets. Our method constructs a k-nearest neighbour graph from pre-trained vision foundation model features and applies a random walk to diffuse uncertainty. The random walk diffusion regularizes the non-conformity scores, making the prediction sets less sensitive to the conformal calibration parameter $λ$, ensuring more stable and continuous anatomical boundaries. RW-CP maintains rigorous marginal coverage while significantly improving segmentation quality. Evaluations on multi-modal public datasets show improvements of up to $35.4\%$ compared to standard CP baselines, given an allowable error rate of $α=0.1$.
Histopath-C: Towards Realistic Domain Shifts for Histopathology Vision-Language Adaptation
Jan 18, 2026Medical Vision-language models (VLMs) have shown remarkable performances in various medical imaging domains such as histo\-pathology by leveraging pre-trained, contrastive models that exploit visual and textual information. However, histopathology images may exhibit severe domain shifts, such as staining, contamination, blurring, and noise, which may severely degrade the VLM's downstream performance. In this work, we introduce Histopath-C, a new benchmark with realistic synthetic corruptions designed to mimic real-world distribution shifts observed in digital histopathology. Our framework dynamically applies corruptions to any available dataset and evaluates Test-Time Adaptation (TTA) mechanisms on the fly. We then propose LATTE, a transductive, low-rank adaptation strategy that exploits multiple text templates, mitigating the sensitivity of histopathology VLMs to diverse text inputs. Our approach outperforms state-of-the-art TTA methods originally designed for natural images across a breadth of histopathology datasets, demonstrating the effectiveness of our proposed design for robust adaptation in histopathology images. Code and data are available at https://github.com/Mehrdad-Noori/Histopath-C.
Revisiting the Learning Objectives of Vision-Language Reward Models
Dec 20, 2025Learning generalizable reward functions is a core challenge in embodied intelligence. Recent work leverages contrastive vision language models (VLMs) to obtain dense, domain-agnostic rewards without human supervision. These methods adapt VLMs into reward models through increasingly complex learning objectives, yet meaningful comparison remains difficult due to differences in training data, architectures, and evaluation settings. In this work, we isolate the impact of the learning objective by evaluating recent VLM-based reward models under a unified framework with identical backbones, finetuning data, and evaluation environments. Using Meta-World tasks, we assess modeling accuracy by measuring consistency with ground truth reward and correlation with expert progress. Remarkably, we show that a simple triplet loss outperforms state-of-the-art methods, suggesting that much of the improvements in recent approaches could be attributed to differences in data and architectures.
NERVE: Neighbourhood & Entropy-guided Random-walk for training free open-Vocabulary sEgmentation
Nov 11, 2025Despite recent advances in Open-Vocabulary Semantic Segmentation (OVSS), existing training-free methods face several limitations: use of computationally expensive affinity refinement strategies, ineffective fusion of transformer attention maps due to equal weighting or reliance on fixed-size Gaussian kernels to reinforce local spatial smoothness, enforcing isotropic neighborhoods. We propose a strong baseline for training-free OVSS termed as NERVE (Neighbourhood \& Entropy-guided Random-walk for open-Vocabulary sEgmentation), which uniquely integrates global and fine-grained local information, exploiting the neighbourhood structure from the self-attention layer of a stable diffusion model. We also introduce a stochastic random walk for refining the affinity rather than relying on fixed-size Gaussian kernels for local context. This spatial diffusion process encourages propagation across connected and semantically related areas, enabling it to effectively delineate objects with arbitrary shapes. Whereas most existing approaches treat self-attention maps from different transformer heads or layers equally, our method uses entropy-based uncertainty to select the most relevant maps. Notably, our method does not require any conventional post-processing techniques like Conditional Random Fields (CRF) or Pixel-Adaptive Mask Refinement (PAMR). Experiments are performed on 7 popular semantic segmentation benchmarks, yielding an overall state-of-the-art zero-shot segmentation performance, providing an effective approach to open-vocabulary semantic segmentation.
Reinforcement Learning for Unsupervised Domain Adaptation in Spatio-Temporal Echocardiography Segmentation
Oct 16, 2025Domain adaptation methods aim to bridge the gap between datasets by enabling knowledge transfer across domains, reducing the need for additional expert annotations. However, many approaches struggle with reliability in the target domain, an issue particularly critical in medical image segmentation, where accuracy and anatomical validity are essential. This challenge is further exacerbated in spatio-temporal data, where the lack of temporal consistency can significantly degrade segmentation quality, and particularly in echocardiography, where the presence of artifacts and noise can further hinder segmentation performance. To address these issues, we present RL4Seg3D, an unsupervised domain adaptation framework for 2D + time echocardiography segmentation. RL4Seg3D integrates novel reward functions and a fusion scheme to enhance key landmark precision in its segmentations while processing full-sized input videos. By leveraging reinforcement learning for image segmentation, our approach improves accuracy, anatomical validity, and temporal consistency while also providing, as a beneficial side effect, a robust uncertainty estimator, which can be used at test time to further enhance segmentation performance. We demonstrate the effectiveness of our framework on over 30,000 echocardiographic videos, showing that it outperforms standard domain adaptation techniques without the need for any labels on the target domain. Code is available at https://github.com/arnaudjudge/RL4Seg3D.
THUNDER: Tile-level Histopathology image UNDERstanding benchmark
Jul 10, 2025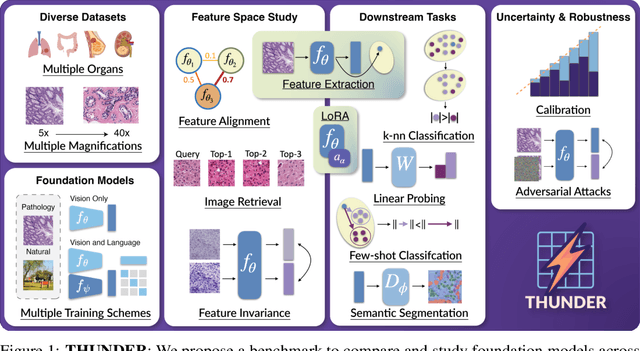
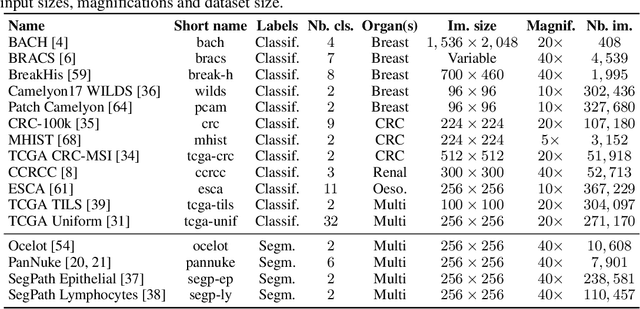

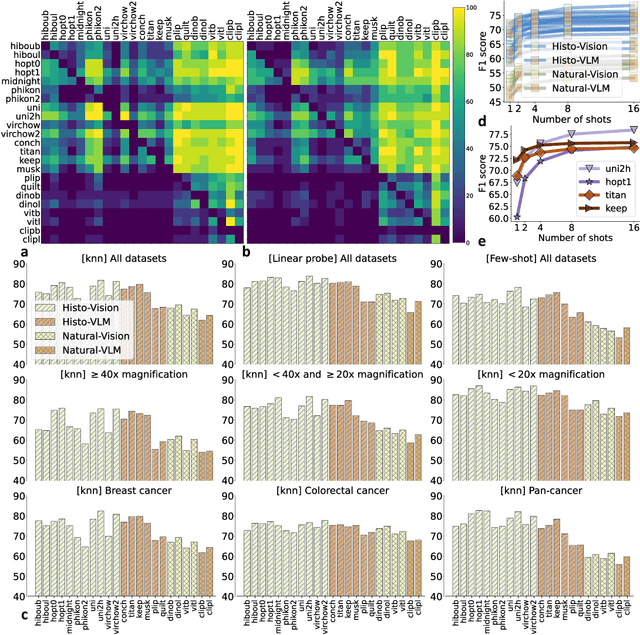
Progress in a research field can be hard to assess, in particular when many concurrent methods are proposed in a short period of time. This is the case in digital pathology, where many foundation models have been released recently to serve as feature extractors for tile-level images, being used in a variety of downstream tasks, both for tile- and slide-level problems. Benchmarking available methods then becomes paramount to get a clearer view of the research landscape. In particular, in critical domains such as healthcare, a benchmark should not only focus on evaluating downstream performance, but also provide insights about the main differences between methods, and importantly, further consider uncertainty and robustness to ensure a reliable usage of proposed models. For these reasons, we introduce THUNDER, a tile-level benchmark for digital pathology foundation models, allowing for efficient comparison of many models on diverse datasets with a series of downstream tasks, studying their feature spaces and assessing the robustness and uncertainty of predictions informed by their embeddings. THUNDER is a fast, easy-to-use, dynamic benchmark that can already support a large variety of state-of-the-art foundation, as well as local user-defined models for direct tile-based comparison. In this paper, we provide a comprehensive comparison of 23 foundation models on 16 different datasets covering diverse tasks, feature analysis, and robustness. The code for THUNDER is publicly available at https://github.com/MICS-Lab/thunder.