 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistopath-C: Towards Realistic Domain Shifts for Histopathology Vision-Language Adaptation
Jan 18, 2026Medical Vision-language models (VLMs) have shown remarkable performances in various medical imaging domains such as histo\-pathology by leveraging pre-trained, contrastive models that exploit visual and textual information. However, histopathology images may exhibit severe domain shifts, such as staining, contamination, blurring, and noise, which may severely degrade the VLM's downstream performance. In this work, we introduce Histopath-C, a new benchmark with realistic synthetic corruptions designed to mimic real-world distribution shifts observed in digital histopathology. Our framework dynamically applies corruptions to any available dataset and evaluates Test-Time Adaptation (TTA) mechanisms on the fly. We then propose LATTE, a transductive, low-rank adaptation strategy that exploits multiple text templates, mitigating the sensitivity of histopathology VLMs to diverse text inputs. Our approach outperforms state-of-the-art TTA methods originally designed for natural images across a breadth of histopathology datasets, demonstrating the effectiveness of our proposed design for robust adaptation in histopathology images. Code and data are available at https://github.com/Mehrdad-Noori/Histopath-C.
Test-Time Adaptation of Vision-Language Models for Open-Vocabulary Semantic Segmentation
May 28, 2025Recently, test-time adaptation has attracted wide interest in the context of vision-language models for image classification. However, to the best of our knowledge, the problem is completely overlooked in dense prediction tasks such as Open-Vocabulary Semantic Segmentation (OVSS). In response, we propose a novel TTA method tailored to adapting VLMs for segmentation during test time. Unlike TTA methods for image classification, our Multi-Level and Multi-Prompt (MLMP) entropy minimization integrates features from intermediate vision-encoder layers and is performed with different text-prompt templates at both the global CLS token and local pixel-wise levels. Our approach could be used as plug-and-play for any segmentation network, does not require additional training data or labels, and remains effective even with a single test sample. Furthermore, we introduce a comprehensive OVSS TTA benchmark suite, which integrates a rigorous evaluation protocol, seven segmentation datasets, and 15 common corruptions, with a total of 82 distinct test scenarios, establishing a standardized and comprehensive testbed for future TTA research in open-vocabulary segmentation. Our experiments on this suite demonstrate that our segmentation-tailored method consistently delivers significant gains over direct adoption of TTA classification baselines.
SMART-PC: Skeletal Model Adaptation for Robust Test-Time Training in Point Clouds
May 26, 2025Test-Time Training (TTT) has emerged as a promising solution to address distribution shifts in 3D point cloud classification. However, existing methods often rely on computationally expensive backpropagation during adaptation, limiting their applicability in real-world, time-sensitive scenarios. In this paper, we introduce SMART-PC, a skeleton-based framework that enhances resilience to corruptions by leveraging the geometric structure of 3D point clouds. During pre-training, our method predicts skeletal representations, enabling the model to extract robust and meaningful geometric features that are less sensitive to corruptions, thereby improving adaptability to test-time distribution shifts. Unlike prior approaches, SMART-PC achieves real-time adaptation by eliminating backpropagation and updating only BatchNorm statistics, resulting in a lightweight and efficient framework capable of achieving high frame-per-second rates while maintaining superior classification performance. Extensive experiments on benchmark datasets, including ModelNet40-C, ShapeNet-C, and ScanObjectNN-C, demonstrate that SMART-PC achieves state-of-the-art results, outperforming existing methods such as MATE in terms of both accuracy and computational efficiency. The implementation is available at: https://github.com/AliBahri94/SMART-PC.
Spectral State Space Model for Rotation-Invariant~Visual~Representation~Learning
Mar 09, 2025State Space Models (SSMs) have recently emerged as an alternative to Vision Transformers (ViTs) due to their unique ability of modeling global relationships with linear complexity. SSMs are specifically designed to capture spatially proximate relationships of image patches. However, they fail to identify relationships between conceptually related yet not adjacent patches. This limitation arises from the non-causal nature of image data, which lacks inherent directional relationships. Additionally, current vision-based SSMs are highly sensitive to transformations such as rotation. Their predefined scanning directions depend on the original image orientation, which can cause the model to produce inconsistent patch-processing sequences after rotation. To address these limitations, we introduce Spectral VMamba, a novel approach that effectively captures the global structure within an image by leveraging spectral information derived from the graph Laplacian of image patches. Through spectral decomposition, our approach encodes patch relationships independently of image orientation, achieving rotation invariance with the aid of our Rotational Feature Normalizer (RFN) module. Our experiments on classification tasks show that Spectral VMamba outperforms the leading SSM models in vision, such as VMamba, while maintaining invariance to rotations and a providing a similar runtime efficiency.
Spectral Informed Mamba for Robust Point Cloud Processing
Mar 06, 2025State space models have shown significant promise in Natural Language Processing (NLP) and, more recently, computer vision. This paper introduces a new methodology leveraging Mamba and Masked Autoencoder networks for point cloud data in both supervised and self-supervised learning. We propose three key contributions to enhance Mamba's capability in processing complex point cloud structures. First, we exploit the spectrum of a graph Laplacian to capture patch connectivity, defining an isometry-invariant traversal order that is robust to viewpoints and better captures shape manifolds than traditional 3D grid-based traversals. Second, we adapt segmentation via a recursive patch partitioning strategy informed by Laplacian spectral components, allowing finer integration and segment analysis. Third, we address token placement in Masked Autoencoder for Mamba by restoring tokens to their original positions, which preserves essential order and improves learning. Extensive experiments demonstrate the improvements of our approach in classification, segmentation, and few-shot tasks over state-of-the-art baselines.
Feedback-guided Domain Synthesis with Multi-Source Conditional Diffusion Models for Domain Generalization
Jul 04, 2024Standard deep learning architectures such as convolutional neural networks and vision transformers often fail to generalize to previously unseen domains due to the implicit assumption that both source and target data are drawn from independent and identically distributed (i.i.d.) populations. In response, Domain Generalization techniques aim to enhance model robustness by simulating novel data distributions during training, typically through various augmentation or stylization strategies. However, these methods frequently suffer from limited control over the diversity of generated images and lack assurance that these images span distinct distributions. To address these challenges, we propose FDS, a novel strategy that employs diffusion models to synthesize samples from new domains by training on source distribution samples and performing domain mixing. By incorporating images that pose classification challenges to models trained on original samples, alongside the original dataset, we ensure the generation of a training set that spans a broad distribution spectrum. Our comprehensive evaluations demonstrate that this methodology sets new benchmarks in domain generalization performance across a range of challenging datasets, effectively managing diverse types of domain shifts. The implementation is available at: \url{https://github.com/Mehrdad-Noori/FDS.git}.
WATT: Weight Average Test-Time Adaptation of CLIP
Jun 24, 2024



Vision-Language Models (VLMs) such as CLIP have yielded unprecedented performance for zero-shot image classification, yet their generalization capability may still be seriously challenged when confronted to domain shifts. In response, we present Weight Average Test-Time Adaptation (WATT) of CLIP, a pioneering approach facilitating full test-time adaptation (TTA) of this VLM. Our method employs a diverse set of templates for text prompts, augmenting the existing framework of CLIP. Predictions are utilized as pseudo labels for model updates, followed by weight averaging to consolidate the learned information globally. Furthermore, we introduce a text ensemble strategy, enhancing overall test performance by aggregating diverse textual cues. Our findings underscore the efficacy of WATT in enhancing performance across diverse datasets, including CIFAR-10-C, CIFAR-10.1, CIFAR-100-C, VisDA-C, and several other challenging datasets, effectively covering a wide range of domain shifts. Notably, these enhancements are achieved without necessitating additional model transformations or trainable modules. Moreover, compared to other Test-Time Adaptation methods, our approach can operate effectively with just a single image. Highlighting the potential of innovative test-time strategies, this research emphasizes their role in fortifying the adaptability of VLMs. The implementation is available at: \url{https://github.com/Mehrdad-Noori/WATT.git}.
WATT: Weight Average Test-Time Adaption of CLIP
Jun 19, 2024Vision-Language Models (VLMs) such as CLIP have yielded unprecedented performance for zero-shot image classification, yet their generalization capability may still be seriously challenged when confronted to domain shifts. In response, we present Weight Average Test-Time Adaptation (WATT) of CLIP, a pioneering approach facilitating full test-time adaptation (TTA) of this VLM. Our method employs a diverse set of templates for text prompts, augmenting the existing framework of CLIP. Predictions are utilized as pseudo labels for model updates, followed by weight averaging to consolidate the learned information globally. Furthermore, we introduce a text ensemble strategy, enhancing overall test performance by aggregating diverse textual cues. Our findings underscore the efficacy of WATT in enhancing performance across diverse datasets, including CIFAR-10-C, CIFAR-10.1, CIFAR-100-C, VisDA-C, and several other challenging datasets, effectively covering a wide range of domain shifts. Notably, these enhancements are achieved without necessitating additional model transformations or trainable modules. Moreover, compared to other Test-Time Adaptation methods, our approach can operate effectively with just a single image. Highlighting the potential of innovative test-time strategies, this research emphasizes their role in fortifying the adaptability of VLMs. The implementation is available at: \url{https://github.com/Mehrdad-Noori/WATT.git}.
GeoMask3D: Geometrically Informed Mask Selection for Self-Supervised Point Cloud Learning in 3D
May 20, 2024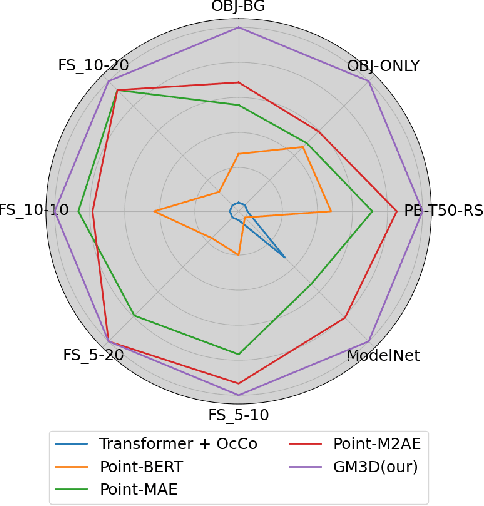
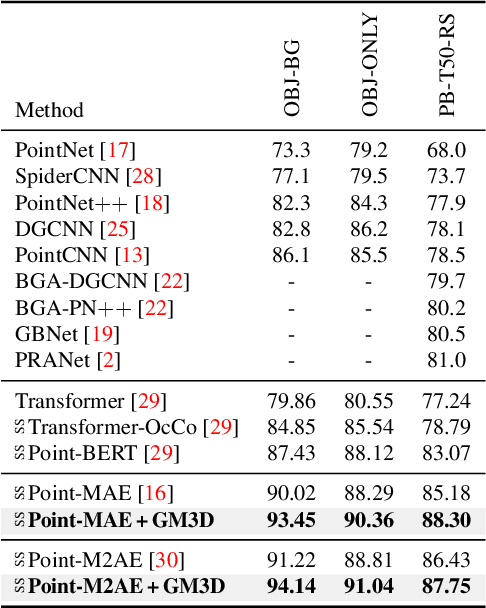
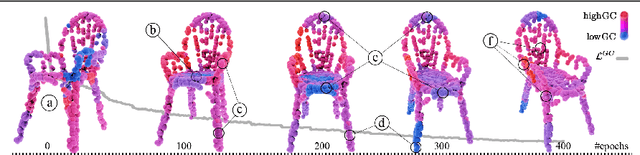
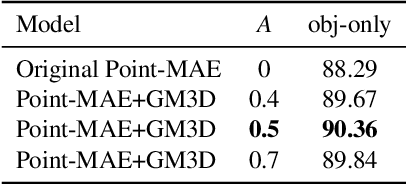
We introduce a pioneering approach to self-supervised learning for point clouds, employing a geometrically informed mask selection strategy called GeoMask3D (GM3D) to boost the efficiency of Masked Auto Encoders (MAE). Unlike the conventional method of random masking, our technique utilizes a teacher-student model to focus on intricate areas within the data, guiding the model's focus toward regions with higher geometric complexity. This strategy is grounded in the hypothesis that concentrating on harder patches yields a more robust feature representation, as evidenced by the improved performance on downstream tasks. Our method also presents a complete-to-partial feature-level knowledge distillation technique designed to guide the prediction of geometric complexity utilizing a comprehensive context from feature-level information. Extensive experiments confirm our method's superiority over State-Of-The-Art (SOTA) baselines, demonstrating marked improvements in classification, and few-shot tasks.
CLIPArTT: Light-weight Adaptation of CLIP to New Domains at Test Time
May 01, 2024



Pre-trained vision-language models (VLMs), exemplified by CLIP, demonstrate remarkable adaptability across zero-shot classification tasks without additional training. However, their performance diminishes in the presence of domain shifts. In this study, we introduce CLIP Adaptation duRing Test-Time (CLIPArTT), a fully test-time adaptation (TTA) approach for CLIP, which involves automatic text prompts construction during inference for their use as text supervision. Our method employs a unique, minimally invasive text prompt tuning process, wherein multiple predicted classes are aggregated into a single new text prompt, used as pseudo label to re-classify inputs in a transductive manner. Additionally, we pioneer the standardization of TTA benchmarks (e.g., TENT) in the realm of VLMs. Our findings demonstrate that, without requiring additional transformations nor new trainable modules, CLIPArTT enhances performance dynamically across non-corrupted datasets such as CIFAR-10, corrupted datasets like CIFAR-10-C and CIFAR-10.1, alongside synthetic datasets such as VisDA-C. This research underscores the potential for improving VLMs' adaptability through novel test-time strategies, offering insights for robust performance across varied datasets and environments. The code can be found at: https://github.com/dosowiechi/CLIPArTT.git