 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Adaptation of Vision-Language Models for Open-Vocabulary Semantic Segmentation
May 28, 2025Recently, test-time adaptation has attracted wide interest in the context of vision-language models for image classification. However, to the best of our knowledge, the problem is completely overlooked in dense prediction tasks such as Open-Vocabulary Semantic Segmentation (OVSS). In response, we propose a novel TTA method tailored to adapting VLMs for segmentation during test time. Unlike TTA methods for image classification, our Multi-Level and Multi-Prompt (MLMP) entropy minimization integrates features from intermediate vision-encoder layers and is performed with different text-prompt templates at both the global CLS token and local pixel-wise levels. Our approach could be used as plug-and-play for any segmentation network, does not require additional training data or labels, and remains effective even with a single test sample. Furthermore, we introduce a comprehensive OVSS TTA benchmark suite, which integrates a rigorous evaluation protocol, seven segmentation datasets, and 15 common corruptions, with a total of 82 distinct test scenarios, establishing a standardized and comprehensive testbed for future TTA research in open-vocabulary segmentation. Our experiments on this suite demonstrate that our segmentation-tailored method consistently delivers significant gains over direct adoption of TTA classification baselines.
SMART-PC: Skeletal Model Adaptation for Robust Test-Time Training in Point Clouds
May 26, 2025Test-Time Training (TTT) has emerged as a promising solution to address distribution shifts in 3D point cloud classification. However, existing methods often rely on computationally expensive backpropagation during adaptation, limiting their applicability in real-world, time-sensitive scenarios. In this paper, we introduce SMART-PC, a skeleton-based framework that enhances resilience to corruptions by leveraging the geometric structure of 3D point clouds. During pre-training, our method predicts skeletal representations, enabling the model to extract robust and meaningful geometric features that are less sensitive to corruptions, thereby improving adaptability to test-time distribution shifts. Unlike prior approaches, SMART-PC achieves real-time adaptation by eliminating backpropagation and updating only BatchNorm statistics, resulting in a lightweight and efficient framework capable of achieving high frame-per-second rates while maintaining superior classification performance. Extensive experiments on benchmark datasets, including ModelNet40-C, ShapeNet-C, and ScanObjectNN-C, demonstrate that SMART-PC achieves state-of-the-art results, outperforming existing methods such as MATE in terms of both accuracy and computational efficiency. The implementation is available at: https://github.com/AliBahri94/SMART-PC.
Correcting Deviations from Normality: A Reformulated Diffusion Model for Multi-Class Unsupervised Anomaly Detection
Mar 25, 2025Recent advances in diffusion models have spurred research into their application for Reconstruction-based unsupervised anomaly detection. However, these methods may struggle with maintaining structural integrity and recovering the anomaly-free content of abnormal regions, especially in multi-class scenarios. Furthermore, diffusion models are inherently designed to generate images from pure noise and struggle to selectively alter anomalous regions of an image while preserving normal ones. This leads to potential degradation of normal regions during reconstruction, hampering the effectiveness of anomaly detection. This paper introduces a reformulation of the standard diffusion model geared toward selective region alteration, allowing the accurate identification of anomalies. By modeling anomalies as noise in the latent space, our proposed Deviation correction diffusion (DeCo-Diff) model preserves the normal regions and encourages transformations exclusively on anomalous areas. This selective approach enhances the reconstruction quality, facilitating effective unsupervised detection and localization of anomaly regions. Comprehensive evaluations demonstrate the superiority of our method in accurately identifying and localizing anomalies in complex images, with pixel-level AUPRC improvements of 11-14% over state-of-the-art models on well known anomaly detection datasets. The code is available at https://github.com/farzad-bz/DeCo-Diff
Spectral State Space Model for Rotation-Invariant~Visual~Representation~Learning
Mar 09, 2025State Space Models (SSMs) have recently emerged as an alternative to Vision Transformers (ViTs) due to their unique ability of modeling global relationships with linear complexity. SSMs are specifically designed to capture spatially proximate relationships of image patches. However, they fail to identify relationships between conceptually related yet not adjacent patches. This limitation arises from the non-causal nature of image data, which lacks inherent directional relationships. Additionally, current vision-based SSMs are highly sensitive to transformations such as rotation. Their predefined scanning directions depend on the original image orientation, which can cause the model to produce inconsistent patch-processing sequences after rotation. To address these limitations, we introduce Spectral VMamba, a novel approach that effectively captures the global structure within an image by leveraging spectral information derived from the graph Laplacian of image patches. Through spectral decomposition, our approach encodes patch relationships independently of image orientation, achieving rotation invariance with the aid of our Rotational Feature Normalizer (RFN) module. Our experiments on classification tasks show that Spectral VMamba outperforms the leading SSM models in vision, such as VMamba, while maintaining invariance to rotations and a providing a similar runtime efficiency.
Spectral Informed Mamba for Robust Point Cloud Processing
Mar 06, 2025State space models have shown significant promise in Natural Language Processing (NLP) and, more recently, computer vision. This paper introduces a new methodology leveraging Mamba and Masked Autoencoder networks for point cloud data in both supervised and self-supervised learning. We propose three key contributions to enhance Mamba's capability in processing complex point cloud structures. First, we exploit the spectrum of a graph Laplacian to capture patch connectivity, defining an isometry-invariant traversal order that is robust to viewpoints and better captures shape manifolds than traditional 3D grid-based traversals. Second, we adapt segmentation via a recursive patch partitioning strategy informed by Laplacian spectral components, allowing finer integration and segment analysis. Third, we address token placement in Masked Autoencoder for Mamba by restoring tokens to their original positions, which preserves essential order and improves learning. Extensive experiments demonstrate the improvements of our approach in classification, segmentation, and few-shot tasks over state-of-the-art baselines.
MAD-AD: Masked Diffusion for Unsupervised Brain Anomaly Detection
Feb 24, 2025Unsupervised anomaly detection in brain images is crucial for identifying injuries and pathologies without access to labels. However, the accurate localization of anomalies in medical images remains challenging due to the inherent complexity and variability of brain structures and the scarcity of annotated abnormal data. To address this challenge, we propose a novel approach that incorporates masking within diffusion models, leveraging their generative capabilities to learn robust representations of normal brain anatomy. During training, our model processes only normal brain MRI scans and performs a forward diffusion process in the latent space that adds noise to the features of randomly-selected patches. Following a dual objective, the model learns to identify which patches are noisy and recover their original features. This strategy ensures that the model captures intricate patterns of normal brain structures while isolating potential anomalies as noise in the latent space. At inference, the model identifies noisy patches corresponding to anomalies and generates a normal counterpart for these patches by applying a reverse diffusion process. Our method surpasses existing unsupervised anomaly detection techniques, demonstrating superior performance in generating accurate normal counterparts and localizing anomalies. The code is available at hhttps://github.com/farzad-bz/MAD-AD.
Test-Time Adaptation in Point Clouds: Leveraging Sampling Variation with Weight Averaging
Nov 02, 2024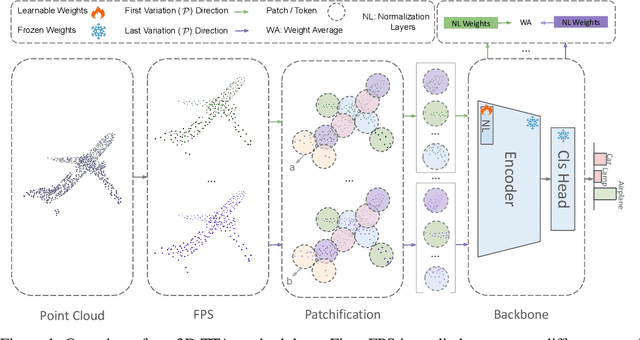
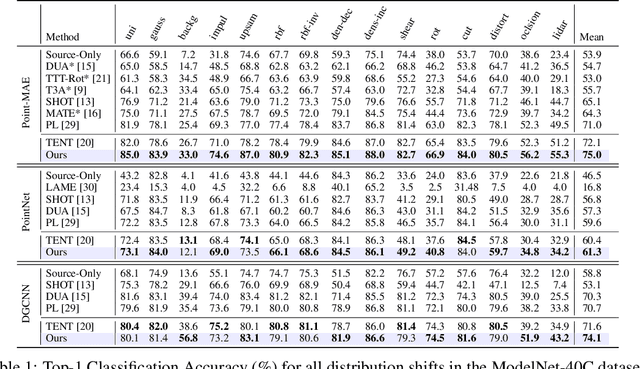
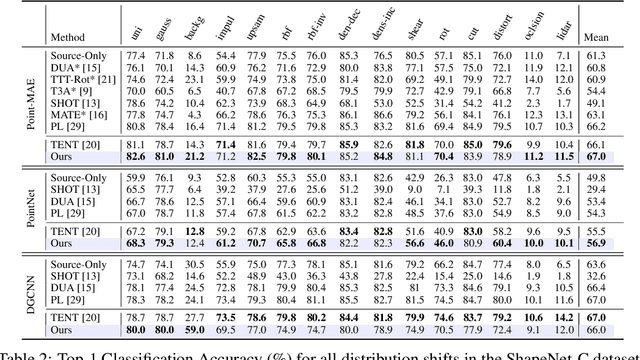
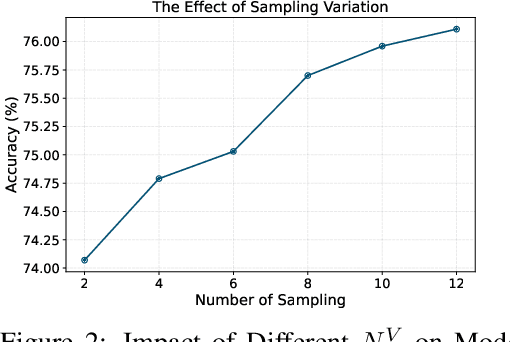
Test-Time Adaptation (TTA) addresses distribution shifts during testing by adapting a pretrained model without access to source data. In this work, we propose a novel TTA approach for 3D point cloud classification, combining sampling variation with weight averaging. Our method leverages Farthest Point Sampling (FPS) and K-Nearest Neighbors (KNN) to create multiple point cloud representations, adapting the model for each variation using the TENT algorithm. The final model parameters are obtained by averaging the adapted weights, leading to improved robustness against distribution shifts. Extensive experiments on ModelNet40-C, ShapeNet-C, and ScanObjectNN-C datasets, with different backbones (Point-MAE, PointNet, DGCNN), demonstrate that our approach consistently outperforms existing methods while maintaining minimal resource overhead. The proposed method effectively enhances model generalization and stability in challenging real-world conditions.
Harmonizing Flows: Leveraging normalizing flows for unsupervised and source-free MRI harmonization
Jul 22, 2024Lack of standardization and various intrinsic parameters for magnetic resonance (MR) image acquisition results in heterogeneous images across different sites and devices, which adversely affects the generalization of deep neural networks. To alleviate this issue, this work proposes a novel unsupervised harmonization framework that leverages normalizing flows to align MR images, thereby emulating the distribution of a source domain. The proposed strategy comprises three key steps. Initially, a normalizing flow network is trained to capture the distribution characteristics of the source domain. Then, we train a shallow harmonizer network to reconstruct images from the source domain via their augmented counterparts. Finally, during inference, the harmonizer network is updated to ensure that the output images conform to the learned source domain distribution, as modeled by the normalizing flow network. Our approach, which is unsupervised, source-free, and task-agnostic is assessed in the context of both adults and neonatal cross-domain brain MRI segmentation, as well as neonatal brain age estimation, demonstrating its generalizability across tasks and population demographics. The results underscore its superior performance compared to existing methodologies. The code is available at https://github.com/farzad-bz/Harmonizing-Flows
WATT: Weight Average Test-Time Adaptation of CLIP
Jun 24, 2024



Vision-Language Models (VLMs) such as CLIP have yielded unprecedented performance for zero-shot image classification, yet their generalization capability may still be seriously challenged when confronted to domain shifts. In response, we present Weight Average Test-Time Adaptation (WATT) of CLIP, a pioneering approach facilitating full test-time adaptation (TTA) of this VLM. Our method employs a diverse set of templates for text prompts, augmenting the existing framework of CLIP. Predictions are utilized as pseudo labels for model updates, followed by weight averaging to consolidate the learned information globally. Furthermore, we introduce a text ensemble strategy, enhancing overall test performance by aggregating diverse textual cues. Our findings underscore the efficacy of WATT in enhancing performance across diverse datasets, including CIFAR-10-C, CIFAR-10.1, CIFAR-100-C, VisDA-C, and several other challenging datasets, effectively covering a wide range of domain shifts. Notably, these enhancements are achieved without necessitating additional model transformations or trainable modules. Moreover, compared to other Test-Time Adaptation methods, our approach can operate effectively with just a single image. Highlighting the potential of innovative test-time strategies, this research emphasizes their role in fortifying the adaptability of VLMs. The implementation is available at: \url{https://github.com/Mehrdad-Noori/WATT.git}.
WATT: Weight Average Test-Time Adaption of CLIP
Jun 19, 2024Vision-Language Models (VLMs) such as CLIP have yielded unprecedented performance for zero-shot image classification, yet their generalization capability may still be seriously challenged when confronted to domain shifts. In response, we present Weight Average Test-Time Adaptation (WATT) of CLIP, a pioneering approach facilitating full test-time adaptation (TTA) of this VLM. Our method employs a diverse set of templates for text prompts, augmenting the existing framework of CLIP. Predictions are utilized as pseudo labels for model updates, followed by weight averaging to consolidate the learned information globally. Furthermore, we introduce a text ensemble strategy, enhancing overall test performance by aggregating diverse textual cues. Our findings underscore the efficacy of WATT in enhancing performance across diverse datasets, including CIFAR-10-C, CIFAR-10.1, CIFAR-100-C, VisDA-C, and several other challenging datasets, effectively covering a wide range of domain shifts. Notably, these enhancements are achieved without necessitating additional model transformations or trainable modules. Moreover, compared to other Test-Time Adaptation methods, our approach can operate effectively with just a single image. Highlighting the potential of innovative test-time strategies, this research emphasizes their role in fortifying the adaptability of VLMs. The implementation is available at: \url{https://github.com/Mehrdad-Noori/WATT.git}.