 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLGC: Pseudo-Labeled Graph Condensation
Jan 15, 2026Large graph datasets make training graph neural networks (GNNs) computationally costly. Graph condensation methods address this by generating small synthetic graphs that approximate the original data. However, existing approaches rely on clean, supervised labels, which limits their reliability when labels are scarce, noisy, or inconsistent. We propose Pseudo-Labeled Graph Condensation (PLGC), a self-supervised framework that constructs latent pseudo-labels from node embeddings and optimizes condensed graphs to match the original graph's structural and feature statistics -- without requiring ground-truth labels. PLGC offers three key contributions: (1) A diagnosis of why supervised condensation fails under label noise and distribution shift. (2) A label-free condensation method that jointly learns latent prototypes and node assignments. (3) Theoretical guarantees showing that pseudo-labels preserve latent structural statistics of the original graph and ensure accurate embedding alignment. Empirically, across node classification and link prediction tasks, PLGC achieves competitive performance with state-of-the-art supervised condensation methods on clean datasets and exhibits substantial robustness under label noise, often outperforming all baselines by a significant margin. Our findings highlight the practical and theoretical advantages of self-supervised graph condensation in noisy or weakly-labeled environments.
Spectral State Space Model for Rotation-Invariant~Visual~Representation~Learning
Mar 09, 2025State Space Models (SSMs) have recently emerged as an alternative to Vision Transformers (ViTs) due to their unique ability of modeling global relationships with linear complexity. SSMs are specifically designed to capture spatially proximate relationships of image patches. However, they fail to identify relationships between conceptually related yet not adjacent patches. This limitation arises from the non-causal nature of image data, which lacks inherent directional relationships. Additionally, current vision-based SSMs are highly sensitive to transformations such as rotation. Their predefined scanning directions depend on the original image orientation, which can cause the model to produce inconsistent patch-processing sequences after rotation. To address these limitations, we introduce Spectral VMamba, a novel approach that effectively captures the global structure within an image by leveraging spectral information derived from the graph Laplacian of image patches. Through spectral decomposition, our approach encodes patch relationships independently of image orientation, achieving rotation invariance with the aid of our Rotational Feature Normalizer (RFN) module. Our experiments on classification tasks show that Spectral VMamba outperforms the leading SSM models in vision, such as VMamba, while maintaining invariance to rotations and a providing a similar runtime efficiency.
Symmetry-Aware Generative Modeling through Learned Canonicalization
Jan 14, 2025Generative modeling of symmetric densities has a range of applications in AI for science, from drug discovery to physics simulations. The existing generative modeling paradigm for invariant densities combines an invariant prior with an equivariant generative process. However, we observe that this technique is not necessary and has several drawbacks resulting from the limitations of equivariant networks. Instead, we propose to model a learned slice of the density so that only one representative element per orbit is learned. To accomplish this, we learn a group-equivariant canonicalization network that maps training samples to a canonical pose and train a non-equivariant generative model over these canonicalized samples. We implement this idea in the context of diffusion models. Our preliminary experimental results on molecular modeling are promising, demonstrating improved sample quality and faster inference time.
Learning Disentangled Representation in Object-Centric Models for Visual Dynamics Prediction via Transformers
Jul 03, 2024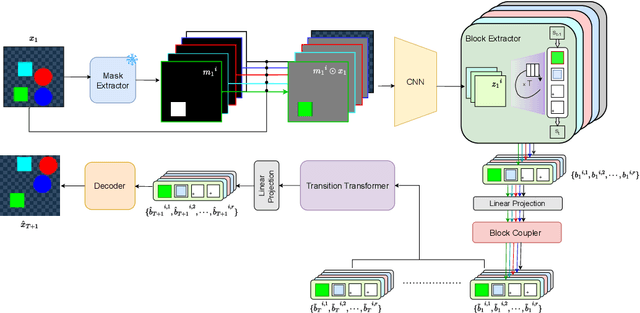
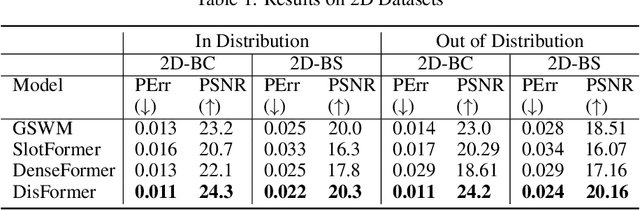
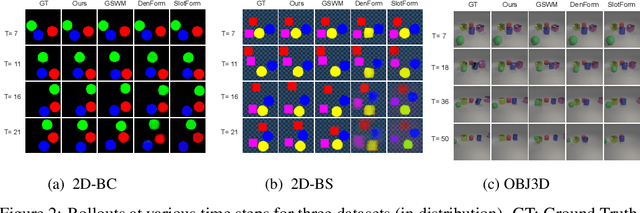
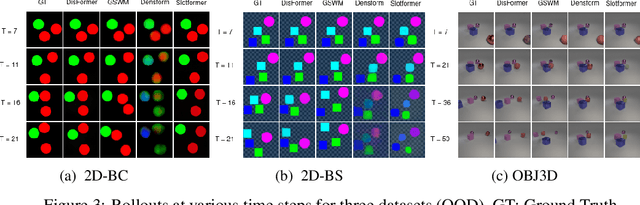
Recent work has shown that object-centric representations can greatly help improve the accuracy of learning dynamics while also bringing interpretability. In this work, we take this idea one step further, ask the following question: "can learning disentangled representation further improve the accuracy of visual dynamics prediction in object-centric models?" While there has been some attempt to learn such disentangled representations for the case of static images \citep{nsb}, to the best of our knowledge, ours is the first work which tries to do this in a general setting for video, without making any specific assumptions about the kind of attributes that an object might have. The key building block of our architecture is the notion of a {\em block}, where several blocks together constitute an object. Each block is represented as a linear combination of a given number of learnable concept vectors, which is iteratively refined during the learning process. The blocks in our model are discovered in an unsupervised manner, by attending over object masks, in a style similar to discovery of slots \citep{slot_attention}, for learning a dense object-centric representation. We employ self-attention via transformers over the discovered blocks to predict the next state resulting in discovery of visual dynamics. We perform a series of experiments on several benchmark 2-D, and 3-D datasets demonstrating that our architecture (1) can discover semantically meaningful blocks (2) help improve accuracy of dynamics prediction compared to SOTA object-centric models (3) perform significantly better in OOD setting where the specific attribute combinations are not seen earlier during training. Our experiments highlight the importance discovery of disentangled representation for visual dynamics prediction.
Improved Canonicalization for Model Agnostic Equivariance
May 23, 2024


This work introduces a novel approach to achieving architecture-agnostic equivariance in deep learning, particularly addressing the limitations of traditional equivariant architectures and the inefficiencies of the existing architecture-agnostic methods. Building equivariant models using traditional methods requires designing equivariant versions of existing models and training them from scratch, a process that is both impractical and resource-intensive. Canonicalization has emerged as a promising alternative for inducing equivariance without altering model architecture, but it suffers from the need for highly expressive and expensive equivariant networks to learn canonical orientations accurately. We propose a new method that employs any non-equivariant network for canonicalization. Our method uses contrastive learning to efficiently learn a unique canonical orientation and offers more flexibility for the choice of canonicalization network. We empirically demonstrate that this approach outperforms existing methods in achieving equivariance for large pretrained models and significantly speeds up the canonicalization process, making it up to 2 times faster.
HumMUSS: Human Motion Understanding using State Space Models
Apr 16, 2024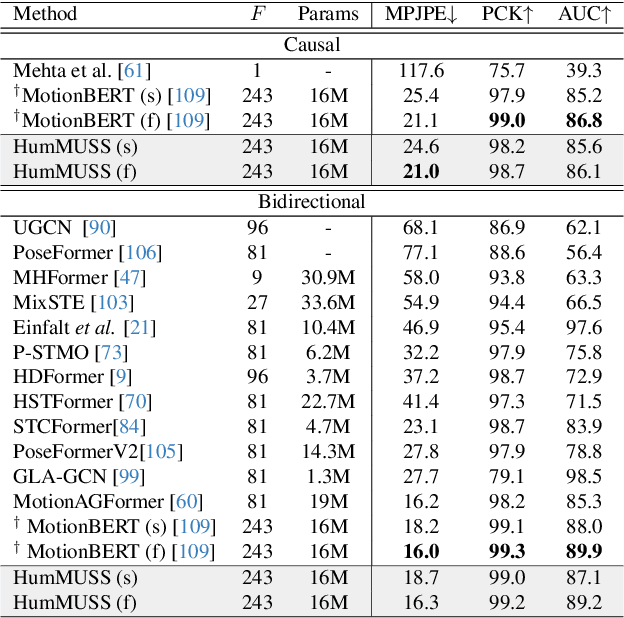
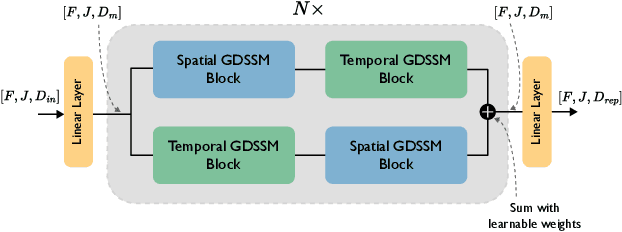
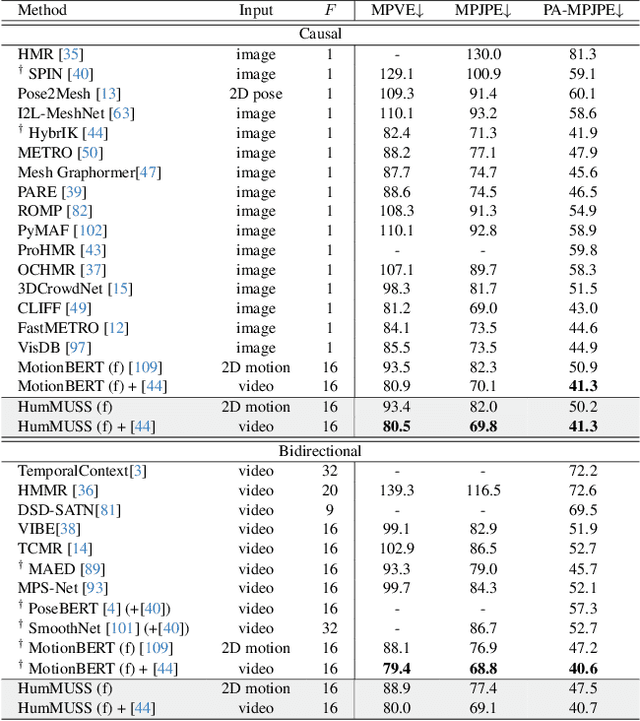
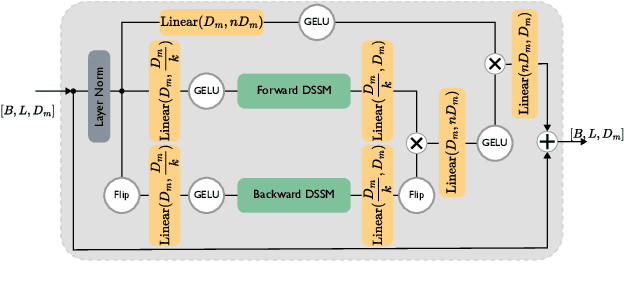
Understanding human motion from video is essential for a range of applications, including pose estimation, mesh recovery and action recognition. While state-of-the-art methods predominantly rely on transformer-based architectures, these approaches have limitations in practical scenarios. Transformers are slower when sequentially predicting on a continuous stream of frames in real-time, and do not generalize to new frame rates. In light of these constraints, we propose a novel attention-free spatiotemporal model for human motion understanding building upon recent advancements in state space models. Our model not only matches the performance of transformer-based models in various motion understanding tasks but also brings added benefits like adaptability to different video frame rates and enhanced training speed when working with longer sequence of keypoints. Moreover, the proposed model supports both offline and real-time applications. For real-time sequential prediction, our model is both memory efficient and several times faster than transformer-based approaches while maintaining their high accuracy.
Equivariant Adaptation of Large Pre-Trained Models
Oct 02, 2023



Equivariant networks are specifically designed to ensure consistent behavior with respect to a set of input transformations, leading to higher sample efficiency and more accurate and robust predictions. However, redesigning each component of prevalent deep neural network architectures to achieve chosen equivariance is a difficult problem and can result in a computationally expensive network during both training and inference. A recently proposed alternative towards equivariance that removes the architectural constraints is to use a simple canonicalization network that transforms the input to a canonical form before feeding it to an unconstrained prediction network. We show here that this approach can effectively be used to make a large pre-trained network equivariant. However, we observe that the produced canonical orientations can be misaligned with those of the training distribution, hindering performance. Using dataset-dependent priors to inform the canonicalization function, we are able to make large pre-trained models equivariant while maintaining their performance. This significantly improves the robustness of these models to deterministic transformations of the data, such as rotations. We believe this equivariant adaptation of large pre-trained models can help their domain-specific applications with known symmetry priors.
Efficient Dynamics Modeling in Interactive Environments with Koopman Theory
Jul 12, 2023



The accurate modeling of dynamics in interactive environments is critical for successful long-range prediction. Such a capability could advance Reinforcement Learning (RL) and Planning algorithms, but achieving it is challenging. Inaccuracies in model estimates can compound, resulting in increased errors over long horizons. We approach this problem from the lens of Koopman theory, where the nonlinear dynamics of the environment can be linearized in a high-dimensional latent space. This allows us to efficiently parallelize the sequential problem of long-range prediction using convolution, while accounting for the agent's action at every time step. Our approach also enables stability analysis and better control over gradients through time. Taken together, these advantages result in significant improvement over the existing approaches, both in the efficiency and the accuracy of modeling dynamics over extended horizons. We also report promising experimental results in dynamics modeling for the scenarios of both model-based planning and model-free RL.
Image Manipulation via Multi-Hop Instructions -- A New Dataset and Weakly-Supervised Neuro-Symbolic Approach
May 23, 2023
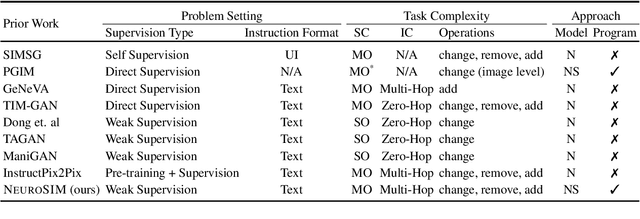
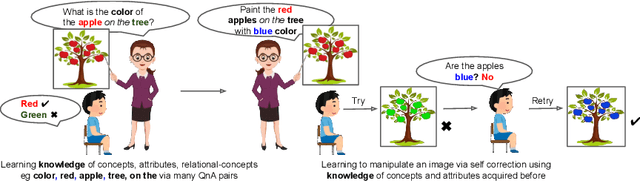
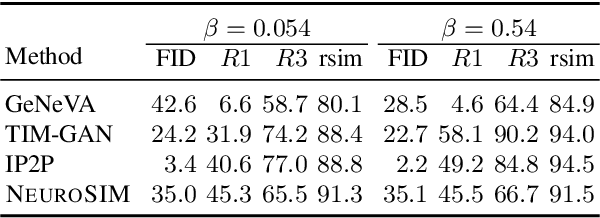
We are interested in image manipulation via natural language text -- a task that is useful for multiple AI applications but requires complex reasoning over multi-modal spaces. We extend recently proposed Neuro Symbolic Concept Learning (NSCL), which has been quite effective for the task of Visual Question Answering (VQA), for the task of image manipulation. Our system referred to as NeuroSIM can perform complex multi-hop reasoning over multi-object scenes and only requires weak supervision in the form of annotated data for VQA. NeuroSIM parses an instruction into a symbolic program, based on a Domain Specific Language (DSL) comprising of object attributes and manipulation operations, that guides its execution. We create a new dataset for the task, and extensive experiments demonstrate that NeuroSIM is highly competitive with or beats SOTA baselines that make use of supervised data for manipulation.
Equivariance with Learned Canonicalization Functions
Nov 11, 2022



Symmetry-based neural networks often constrain the architecture in order to achieve invariance or equivariance to a group of transformations. In this paper, we propose an alternative that avoids this architectural constraint by learning to produce a canonical representation of the data. These canonicalization functions can readily be plugged into non-equivariant backbone architectures. We offer explicit ways to implement them for many groups of interest. We show that this approach enjoys universality while providing interpretable insights. Our main hypothesis is that learning a neural network to perform canonicalization is better than using predefined heuristics. Our results show that learning the canonicalization function indeed leads to better results and that the approach achieves excellent performance in practice.