 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParity Requires Unified Input Dependence and Negative Eigenvalues in SSMs
Aug 10, 2025Recent work has shown that LRNN models such as S4D, Mamba, and DeltaNet lack state-tracking capability due to either time-invariant transition matrices or restricted eigenvalue ranges. To address this, input-dependent transition matrices, particularly those that are complex or non-triangular, have been proposed to enhance SSM performance on such tasks. While existing theorems demonstrate that both input-independent and non-negative SSMs are incapable of solving simple state-tracking tasks, such as parity, regardless of depth, they do not explore whether combining these two types in a multilayer SSM could help. We investigate this question for efficient SSMs with diagonal transition matrices and show that such combinations still fail to solve parity. This implies that a recurrence layer must both be input-dependent and include negative eigenvalues. Our experiments support this conclusion by analyzing an SSM model that combines S4D and Mamba layers.
Beyond Scalar Rewards: An Axiomatic Framework for Lexicographic MDPs
May 17, 2025Recent work has formalized the reward hypothesis through the lens of expected utility theory, by interpreting reward as utility. Hausner's foundational work showed that dropping the continuity axiom leads to a generalization of expected utility theory where utilities are lexicographically ordered vectors of arbitrary dimension. In this paper, we extend this result by identifying a simple and practical condition under which preferences cannot be represented by scalar rewards, necessitating a 2-dimensional reward function. We provide a full characterization of such reward functions, as well as the general d-dimensional case, in Markov Decision Processes (MDPs) under a memorylessness assumption on preferences. Furthermore, we show that optimal policies in this setting retain many desirable properties of their scalar-reward counterparts, while in the Constrained MDP (CMDP) setting -- another common multiobjective setting -- they do not.
Weight-Sharing Regularization
Nov 06, 2023
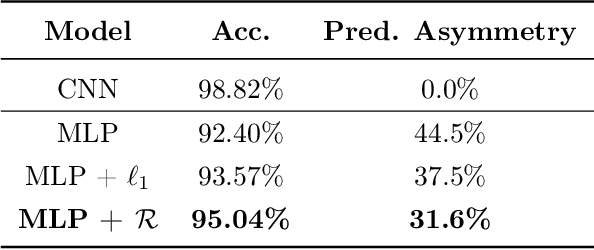
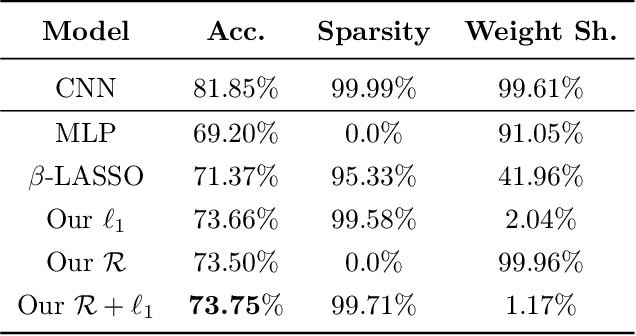

Weight-sharing is ubiquitous in deep learning. Motivated by this, we introduce ''weight-sharing regularization'' for neural networks, defined as $R(w) = \frac{1}{d - 1}\sum_{i > j}^d |w_i - w_j|$. We study the proximal mapping of $R$ and provide an intuitive interpretation of it in terms of a physical system of interacting particles. Using this interpretation, we design a novel parallel algorithm for $\operatorname{prox}_R$ which provides an exponential speedup over previous algorithms, with a depth of $O(\log^3 d)$. Our algorithm makes it feasible to train weight-sharing regularized deep neural networks with proximal gradient descent. Experiments reveal that weight-sharing regularization enables fully-connected networks to learn convolution-like filters.
Utility Theory for Sequential Decision Making
Jun 27, 2022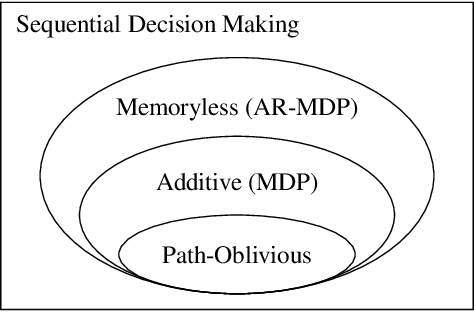
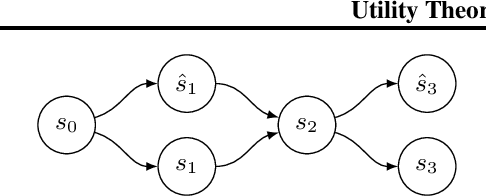
The von Neumann-Morgenstern (VNM) utility theorem shows that under certain axioms of rationality, decision-making is reduced to maximizing the expectation of some utility function. We extend these axioms to increasingly structured sequential decision making settings and identify the structure of the corresponding utility functions. In particular, we show that memoryless preferences lead to a utility in the form of a per transition reward and multiplicative factor on the future return. This result motivates a generalization of Markov Decision Processes (MDPs) with this structure on the agent's returns, which we call Affine-Reward MDPs. A stronger constraint on preferences is needed to recover the commonly used cumulative sum of scalar rewards in MDPs. A yet stronger constraint simplifies the utility function for goal-seeking agents in the form of a difference in some function of states that we call potential functions. Our necessary and sufficient conditions demystify the reward hypothesis that underlies the design of rational agents in reinforcement learning by adding an axiom to the VNM rationality axioms and motivates new directions for AI research involving sequential decision making.
Transformation Coding: Simple Objectives for Equivariant Representations
Feb 19, 2022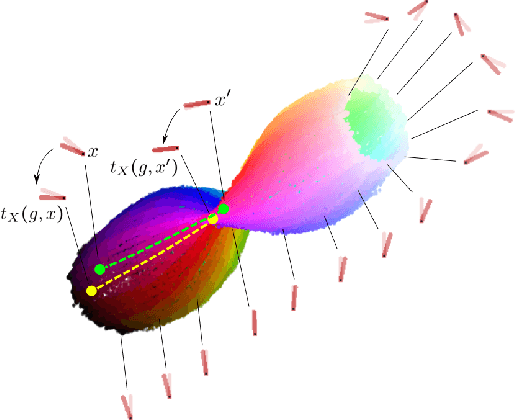


We present a simple non-generative approach to deep representation learning that seeks equivariant deep embedding through simple objectives. In contrast to existing equivariant networks, our transformation coding approach does not constrain the choice of the feed-forward layer or the architecture and allows for an unknown group action on the input space. We introduce several such transformation coding objectives for different Lie groups such as the Euclidean, Orthogonal and the Unitary groups. When using product groups, the representation is decomposed and disentangled. We show that the presence of additional information on different transformations improves disentanglement in transformation coding. We evaluate the representations learnt by transformation coding both qualitatively and quantitatively on downstream tasks, including reinforcement learning.
Equivariant Networks for Pixelized Spheres
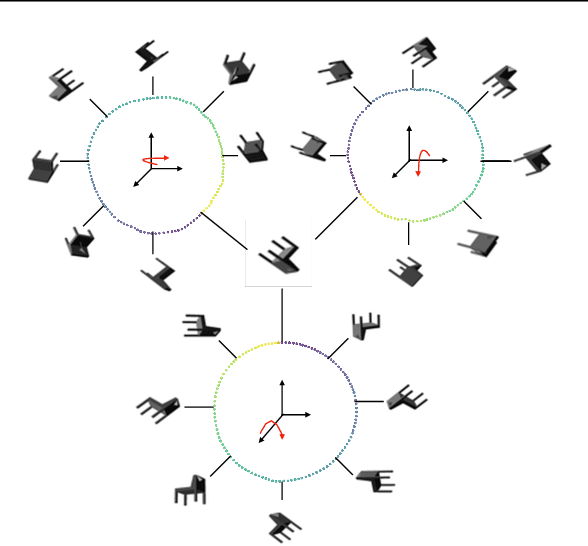
Jun 12, 2021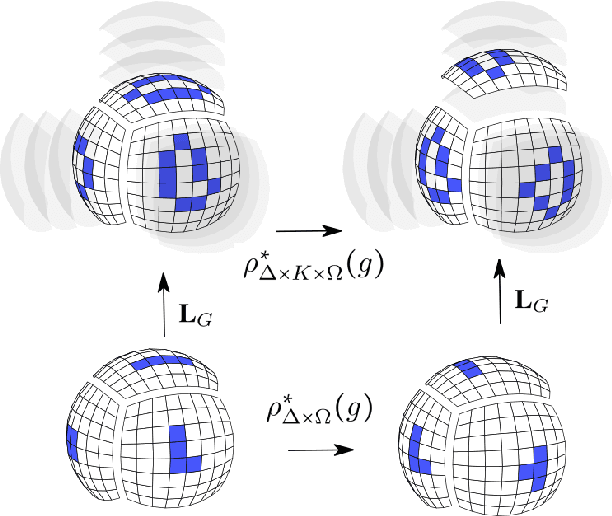
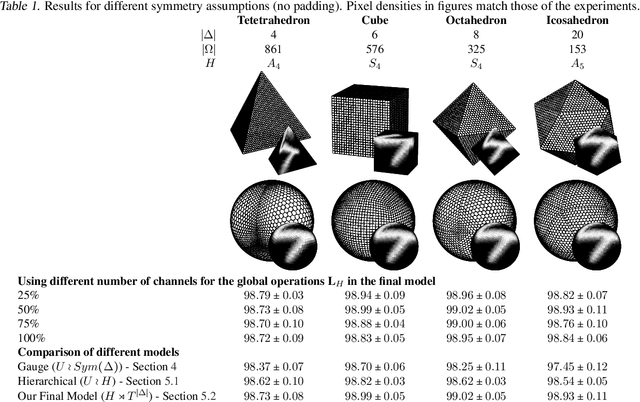
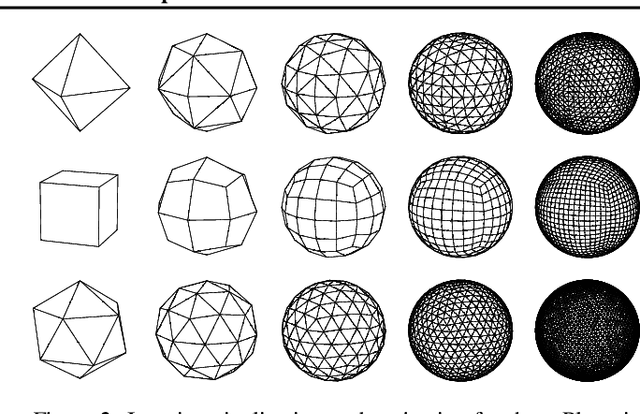
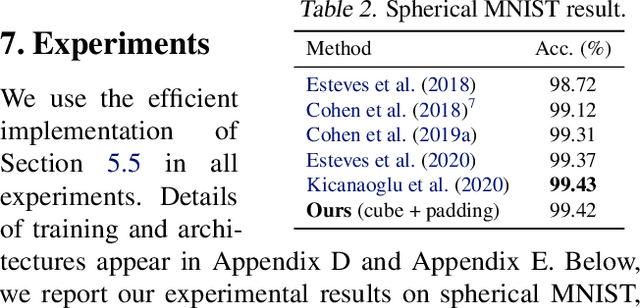
Pixelizations of Platonic solids such as the cube and icosahedron have been widely used to represent spherical data, from climate records to Cosmic Microwave Background maps. Platonic solids have well-known global symmetries. Once we pixelize each face of the solid, each face also possesses its own local symmetries in the form of Euclidean isometries. One way to combine these symmetries is through a hierarchy. However, this approach does not adequately model the interplay between the two levels of symmetry transformations. We show how to model this interplay using ideas from group theory, identify the equivariant linear maps, and introduce equivariant padding that respects these symmetries. Deep networks that use these maps as their building blocks generalize gauge equivariant CNNs on pixelized spheres. These deep networks achieve state-of-the-art results on semantic segmentation for climate data and omnidirectional image processing. Code is available at https://git.io/JGiZA.