 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight-Sharing Regularization
Paper and Code

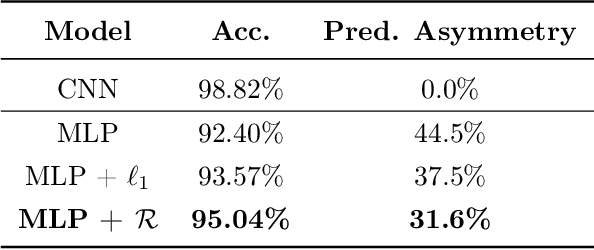
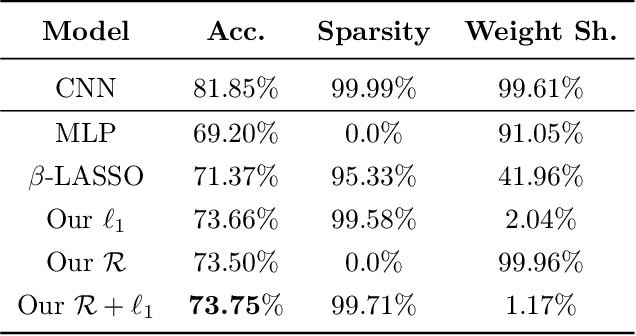

Weight-sharing is ubiquitous in deep learning. Motivated by this, we introduce ''weight-sharing regularization'' for neural networks, defined as $R(w) = \frac{1}{d - 1}\sum_{i > j}^d |w_i - w_j|$. We study the proximal mapping of $R$ and provide an intuitive interpretation of it in terms of a physical system of interacting particles. Using this interpretation, we design a novel parallel algorithm for $\operatorname{prox}_R$ which provides an exponential speedup over previous algorithms, with a depth of $O(\log^3 d)$. Our algorithm makes it feasible to train weight-sharing regularized deep neural networks with proximal gradient descent. Experiments reveal that weight-sharing regularization enables fully-connected networks to learn convolution-like filters.