 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn PI Controllers for Updating Lagrange Multipliers in Constrained Optimization
Jun 07, 2024Constrained optimization offers a powerful framework to prescribe desired behaviors in neural network models. Typically, constrained problems are solved via their min-max Lagrangian formulations, which exhibit unstable oscillatory dynamics when optimized using gradient descent-ascent. The adoption of constrained optimization techniques in the machine learning community is currently limited by the lack of reliable, general-purpose update schemes for the Lagrange multipliers. This paper proposes the $\nu$PI algorithm and contributes an optimization perspective on Lagrange multiplier updates based on PI controllers, extending the work of Stooke, Achiam and Abbeel (2020). We provide theoretical and empirical insights explaining the inability of momentum methods to address the shortcomings of gradient descent-ascent, and contrast this with the empirical success of our proposed $\nu$PI controller. Moreover, we prove that $\nu$PI generalizes popular momentum methods for single-objective minimization. Our experiments demonstrate that $\nu$PI reliably stabilizes the multiplier dynamics and its hyperparameters enjoy robust and predictable behavior.
Weight-Sharing Regularization
Nov 06, 2023
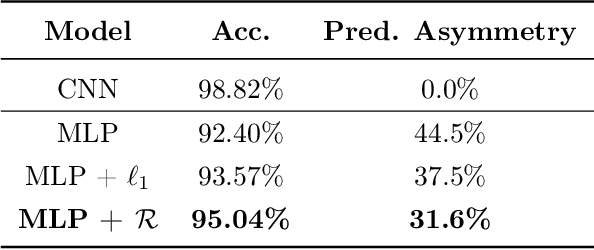
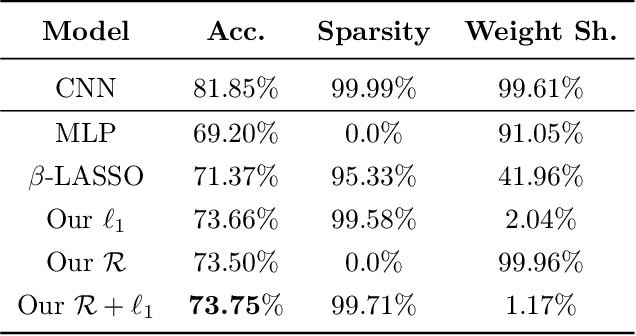

Weight-sharing is ubiquitous in deep learning. Motivated by this, we introduce ''weight-sharing regularization'' for neural networks, defined as $R(w) = \frac{1}{d - 1}\sum_{i > j}^d |w_i - w_j|$. We study the proximal mapping of $R$ and provide an intuitive interpretation of it in terms of a physical system of interacting particles. Using this interpretation, we design a novel parallel algorithm for $\operatorname{prox}_R$ which provides an exponential speedup over previous algorithms, with a depth of $O(\log^3 d)$. Our algorithm makes it feasible to train weight-sharing regularized deep neural networks with proximal gradient descent. Experiments reveal that weight-sharing regularization enables fully-connected networks to learn convolution-like filters.