 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Expressive Limits of Diagonal SSMs for State-Tracking
Mar 02, 2026State-Space Models (SSMs) have recently been shown to achieve strong empirical performance on a variety of long-range sequence modeling tasks while remaining efficient and highly-parallelizable. However, the theoretical understanding of their expressive power remains limited. In this work, we study the expressivity of input-Dependent Complex-valued Diagonal (DCD) SSMs on sequential state-tracking tasks. We show that single-layer DCD SSMs cannot express state-tracking of any non-Abelian group at finite precision. More generally, we show that $k$-layer DCD SSMs can express state-tracking of a group if and only if that group has a subnormal series of length $k$, with Abelian factors. That is, we identify the precise expressivity range of $k$-layer DCD SSMs within the solvable groups. Empirically, we find that multi-layer models often fail to learn state-tracking for non-Abelian groups, highlighting a gap between expressivity and learnability.
Inverting Data Transformations via Diffusion Sampling
Feb 09, 2026We study the problem of transformation inversion on general Lie groups: a datum is transformed by an unknown group element, and the goal is to recover an inverse transformation that maps it back to the original data distribution. Such unknown transformations arise widely in machine learning and scientific modeling, where they can significantly distort observations. We take a probabilistic view and model the posterior over transformations as a Boltzmann distribution defined by an energy function on data space. To sample from this posterior, we introduce a diffusion process on Lie groups that keeps all updates on-manifold and only requires computations in the associated Lie algebra. Our method, Transformation-Inverting Energy Diffusion (TIED), relies on a new trivialized target-score identity that enables efficient score-based sampling of the transformation posterior. As a key application, we focus on test-time equivariance, where the objective is to improve the robustness of pretrained neural networks to input transformations. Experiments on image homographies and PDE symmetries demonstrate that TIED can restore transformed inputs to the training distribution at test time, showing improved performance over strong canonicalization and sampling baselines. Code is available at https://github.com/jw9730/tied.
Parity Requires Unified Input Dependence and Negative Eigenvalues in SSMs
Aug 10, 2025Recent work has shown that LRNN models such as S4D, Mamba, and DeltaNet lack state-tracking capability due to either time-invariant transition matrices or restricted eigenvalue ranges. To address this, input-dependent transition matrices, particularly those that are complex or non-triangular, have been proposed to enhance SSM performance on such tasks. While existing theorems demonstrate that both input-independent and non-negative SSMs are incapable of solving simple state-tracking tasks, such as parity, regardless of depth, they do not explore whether combining these two types in a multilayer SSM could help. We investigate this question for efficient SSMs with diagonal transition matrices and show that such combinations still fail to solve parity. This implies that a recurrence layer must both be input-dependent and include negative eigenvalues. Our experiments support this conclusion by analyzing an SSM model that combines S4D and Mamba layers.
Diffusion Tree Sampling: Scalable inference-time alignment of diffusion models
Jun 25, 2025Adapting a pretrained diffusion model to new objectives at inference time remains an open problem in generative modeling. Existing steering methods suffer from inaccurate value estimation, especially at high noise levels, which biases guidance. Moreover, information from past runs is not reused to improve sample quality, resulting in inefficient use of compute. Inspired by the success of Monte Carlo Tree Search, we address these limitations by casting inference-time alignment as a search problem that reuses past computations. We introduce a tree-based approach that samples from the reward-aligned target density by propagating terminal rewards back through the diffusion chain and iteratively refining value estimates with each additional generation. Our proposed method, Diffusion Tree Sampling (DTS), produces asymptotically exact samples from the target distribution in the limit of infinite rollouts, and its greedy variant, Diffusion Tree Search (DTS$^\star$), performs a global search for high reward samples. On MNIST and CIFAR-10 class-conditional generation, DTS matches the FID of the best-performing baseline with up to $10\times$ less compute. In text-to-image generation and language completion tasks, DTS$^\star$ effectively searches for high reward samples that match best-of-N with up to $5\times$ less compute. By reusing information from previous generations, we get an anytime algorithm that turns additional compute into steadily better samples, providing a scalable approach for inference-time alignment of diffusion models.
Beyond Scalar Rewards: An Axiomatic Framework for Lexicographic MDPs
May 17, 2025Recent work has formalized the reward hypothesis through the lens of expected utility theory, by interpreting reward as utility. Hausner's foundational work showed that dropping the continuity axiom leads to a generalization of expected utility theory where utilities are lexicographically ordered vectors of arbitrary dimension. In this paper, we extend this result by identifying a simple and practical condition under which preferences cannot be represented by scalar rewards, necessitating a 2-dimensional reward function. We provide a full characterization of such reward functions, as well as the general d-dimensional case, in Markov Decision Processes (MDPs) under a memorylessness assumption on preferences. Furthermore, we show that optimal policies in this setting retain many desirable properties of their scalar-reward counterparts, while in the Constrained MDP (CMDP) setting -- another common multiobjective setting -- they do not.
On the Identifiability of Causal Abstractions
Mar 13, 2025
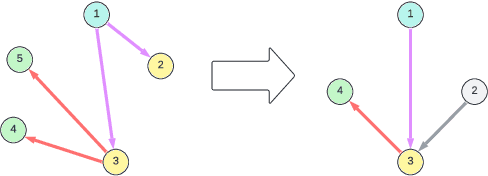
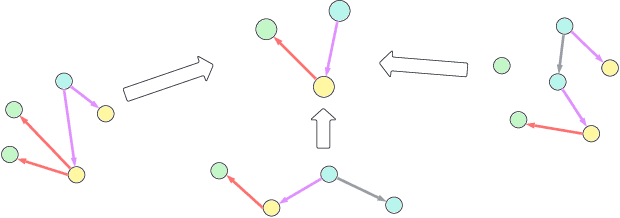

Causal representation learning (CRL) enhances machine learning models' robustness and generalizability by learning structural causal models associated with data-generating processes. We focus on a family of CRL methods that uses contrastive data pairs in the observable space, generated before and after a random, unknown intervention, to identify the latent causal model. (Brehmer et al., 2022) showed that this is indeed possible, given that all latent variables can be intervened on individually. However, this is a highly restrictive assumption in many systems. In this work, we instead assume interventions on arbitrary subsets of latent variables, which is more realistic. We introduce a theoretical framework that calculates the degree to which we can identify a causal model, given a set of possible interventions, up to an abstraction that describes the system at a higher level of granularity.
SymmCD: Symmetry-Preserving Crystal Generation with Diffusion Models
Feb 05, 2025Generating novel crystalline materials has potential to lead to advancements in fields such as electronics, energy storage, and catalysis. The defining characteristic of crystals is their symmetry, which plays a central role in determining their physical properties. However, existing crystal generation methods either fail to generate materials that display the symmetries of real-world crystals, or simply replicate the symmetry information from examples in a database. To address this limitation, we propose SymmCD, a novel diffusion-based generative model that explicitly incorporates crystallographic symmetry into the generative process. We decompose crystals into two components and learn their joint distribution through diffusion: 1) the asymmetric unit, the smallest subset of the crystal which can generate the whole crystal through symmetry transformations, and; 2) the symmetry transformations needed to be applied to each atom in the asymmetric unit. We also use a novel and interpretable representation for these transformations, enabling generalization across different crystallographic symmetry groups. We showcase the competitive performance of SymmCD on a subset of the Materials Project, obtaining diverse and valid crystals with realistic symmetries and predicted properties.
Symmetry-Aware Generative Modeling through Learned Canonicalization
Jan 14, 2025Generative modeling of symmetric densities has a range of applications in AI for science, from drug discovery to physics simulations. The existing generative modeling paradigm for invariant densities combines an invariant prior with an equivariant generative process. However, we observe that this technique is not necessary and has several drawbacks resulting from the limitations of equivariant networks. Instead, we propose to model a learned slice of the density so that only one representative element per orbit is learned. To accomplish this, we learn a group-equivariant canonicalization network that maps training samples to a canonical pose and train a non-equivariant generative model over these canonicalized samples. We implement this idea in the context of diffusion models. Our preliminary experimental results on molecular modeling are promising, demonstrating improved sample quality and faster inference time.
Sampling from Energy-based Policies using Diffusion
Oct 02, 2024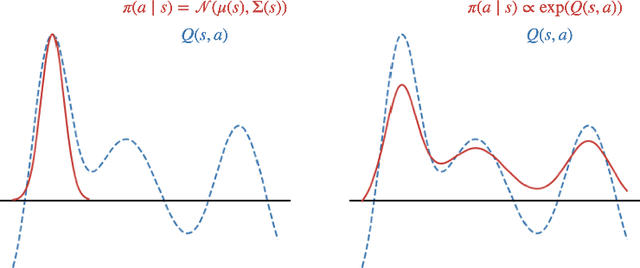
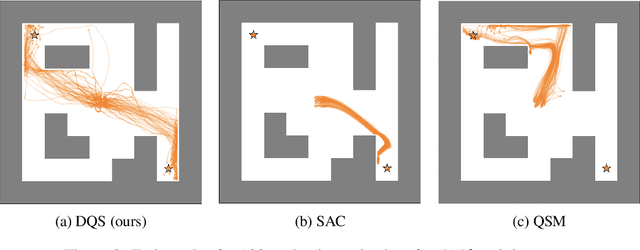

Energy-based policies offer a flexible framework for modeling complex, multimodal behaviors in reinforcement learning (RL). In maximum entropy RL, the optimal policy is a Boltzmann distribution derived from the soft Q-function, but direct sampling from this distribution in continuous action spaces is computationally intractable. As a result, existing methods typically use simpler parametric distributions, like Gaussians, for policy representation - limiting their ability to capture the full complexity of multimodal action distributions. In this paper, we introduce a diffusion-based approach for sampling from energy-based policies, where the negative Q-function defines the energy function. Based on this approach, we propose an actor-critic method called Diffusion Q-Sampling (DQS) that enables more expressive policy representations, allowing stable learning in diverse environments. We show that our approach enhances exploration and captures multimodal behavior in continuous control tasks, addressing key limitations of existing methods.
E(3)-Equivariant Mesh Neural Networks
Feb 19, 2024Triangular meshes are widely used to represent three-dimensional objects. As a result, many recent works have address the need for geometric deep learning on 3D mesh. However, we observe that the complexities in many of these architectures does not translate to practical performance, and simple deep models for geometric graphs are competitive in practice. Motivated by this observation, we minimally extend the update equations of E(n)-Equivariant Graph Neural Networks (EGNNs) (Satorras et al., 2021) to incorporate mesh face information, and further improve it to account for long-range interactions through hierarchy. The resulting architecture, Equivariant Mesh Neural Network (EMNN), outperforms other, more complicated equivariant methods on mesh tasks, with a fast run-time and no expensive pre-processing. Our implementation is available at https://github.com/HySonLab/EquiMesh