 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comedy of Estimators: On KL Regularization in RL Training of LLMs
Dec 26, 2025The reasoning performance of large language models (LLMs) can be substantially improved by training them with reinforcement learning (RL). The RL objective for LLM training involves a regularization term, which is the reverse Kullback-Leibler (KL) divergence between the trained policy and the reference policy. Since computing the KL divergence exactly is intractable, various estimators are used in practice to estimate it from on-policy samples. Despite its wide adoption, including in several open-source libraries, there is no systematic study analyzing the numerous ways of incorporating KL estimators in the objective and their effect on the downstream performance of RL-trained models. Recent works show that prevailing practices for incorporating KL regularization do not provide correct gradients for stated objectives, creating a discrepancy between the objective and its implementation. In this paper, we further analyze these practices and study the gradients of several estimators configurations, revealing how design choices shape gradient bias. We substantiate these findings with empirical observations by RL fine-tuning \texttt{Qwen2.5-7B}, \texttt{Llama-3.1-8B-Instruct} and \texttt{Qwen3-4B-Instruct-2507} with different configurations and evaluating their performance on both in- and out-of-distribution tasks. Through our analysis, we observe that, in on-policy settings: (1) estimator configurations with biased gradients can result in training instabilities; and (2) using estimator configurations resulting in unbiased gradients leads to better performance on in-domain as well as out-of-domain tasks. We also investigate the performance resulting from different KL configurations in off-policy settings and observe that KL regularization can help stabilize off-policy RL training resulting from asynchronous setups.
Recursive Self-Aggregation Unlocks Deep Thinking in Large Language Models
Sep 30, 2025Test-time scaling methods improve the capabilities of large language models (LLMs) by increasing the amount of compute used during inference to make a prediction. Inference-time compute can be scaled in parallel by choosing among multiple independent solutions or sequentially through self-refinement. We propose Recursive Self-Aggregation (RSA), a test-time scaling method inspired by evolutionary methods that combines the benefits of both parallel and sequential scaling. Each step of RSA refines a population of candidate reasoning chains through aggregation of subsets to yield a population of improved solutions, which are then used as the candidate pool for the next iteration. RSA exploits the rich information embedded in the reasoning chains -- not just the final answers -- and enables bootstrapping from partially correct intermediate steps within different chains of thought. Empirically, RSA delivers substantial performance gains with increasing compute budgets across diverse tasks, model families and sizes. Notably, RSA enables Qwen3-4B-Instruct-2507 to achieve competitive performance with larger reasoning models, including DeepSeek-R1 and o3-mini (high), while outperforming purely parallel and sequential scaling strategies across AIME-25, HMMT-25, Reasoning Gym, LiveCodeBench-v6, and SuperGPQA. We further demonstrate that training the model to combine solutions via a novel aggregation-aware reinforcement learning approach yields significant performance gains. Code available at https://github.com/HyperPotatoNeo/RSA.
Diffusion Tree Sampling: Scalable inference-time alignment of diffusion models
Jun 25, 2025Adapting a pretrained diffusion model to new objectives at inference time remains an open problem in generative modeling. Existing steering methods suffer from inaccurate value estimation, especially at high noise levels, which biases guidance. Moreover, information from past runs is not reused to improve sample quality, resulting in inefficient use of compute. Inspired by the success of Monte Carlo Tree Search, we address these limitations by casting inference-time alignment as a search problem that reuses past computations. We introduce a tree-based approach that samples from the reward-aligned target density by propagating terminal rewards back through the diffusion chain and iteratively refining value estimates with each additional generation. Our proposed method, Diffusion Tree Sampling (DTS), produces asymptotically exact samples from the target distribution in the limit of infinite rollouts, and its greedy variant, Diffusion Tree Search (DTS$^\star$), performs a global search for high reward samples. On MNIST and CIFAR-10 class-conditional generation, DTS matches the FID of the best-performing baseline with up to $10\times$ less compute. In text-to-image generation and language completion tasks, DTS$^\star$ effectively searches for high reward samples that match best-of-N with up to $5\times$ less compute. By reusing information from previous generations, we get an anytime algorithm that turns additional compute into steadily better samples, providing a scalable approach for inference-time alignment of diffusion models.
Sampling from Energy-based Policies using Diffusion
Oct 02, 2024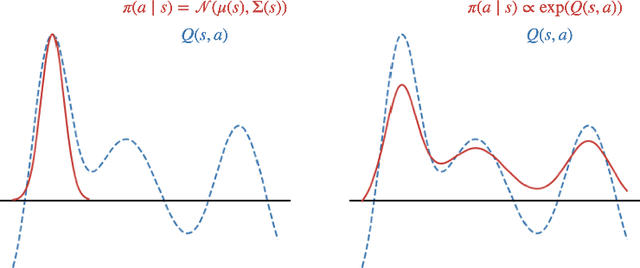
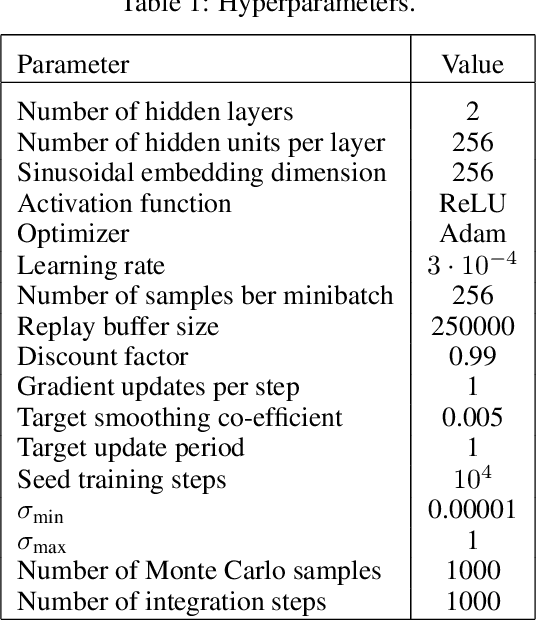
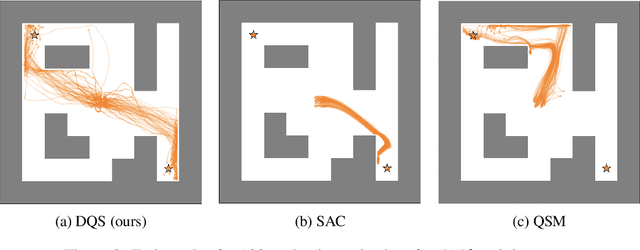

Energy-based policies offer a flexible framework for modeling complex, multimodal behaviors in reinforcement learning (RL). In maximum entropy RL, the optimal policy is a Boltzmann distribution derived from the soft Q-function, but direct sampling from this distribution in continuous action spaces is computationally intractable. As a result, existing methods typically use simpler parametric distributions, like Gaussians, for policy representation - limiting their ability to capture the full complexity of multimodal action distributions. In this paper, we introduce a diffusion-based approach for sampling from energy-based policies, where the negative Q-function defines the energy function. Based on this approach, we propose an actor-critic method called Diffusion Q-Sampling (DQS) that enables more expressive policy representations, allowing stable learning in diverse environments. We show that our approach enhances exploration and captures multimodal behavior in continuous control tasks, addressing key limitations of existing methods.
Learning to Reach Goals via Diffusion
Oct 04, 2023



Diffusion models are a powerful class of generative models capable of mapping random noise in high-dimensional spaces to a target manifold through iterative denoising. In this work, we present a novel perspective on goal-conditioned reinforcement learning by framing it within the context of diffusion modeling. Analogous to the diffusion process, where Gaussian noise is used to create random trajectories that walk away from the data manifold, we construct trajectories that move away from potential goal states. We then learn a goal-conditioned policy analogous to the score function. This approach, which we call Merlin, can reach predefined or novel goals from an arbitrary initial state without learning a separate value function. We consider three choices for the noise model to replace Gaussian noise in diffusion - reverse play from the buffer, reverse dynamics model, and a novel non-parametric approach. We theoretically justify our approach and validate it on offline goal-reaching tasks. Empirical results are competitive with state-of-the-art methods, which suggests this perspective on diffusion for RL is a simple, scalable, and effective direction for sequential decision-making.
On Diffusion Modeling for Anomaly Detection
May 29, 2023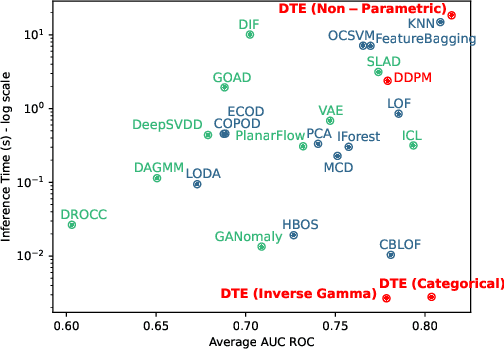
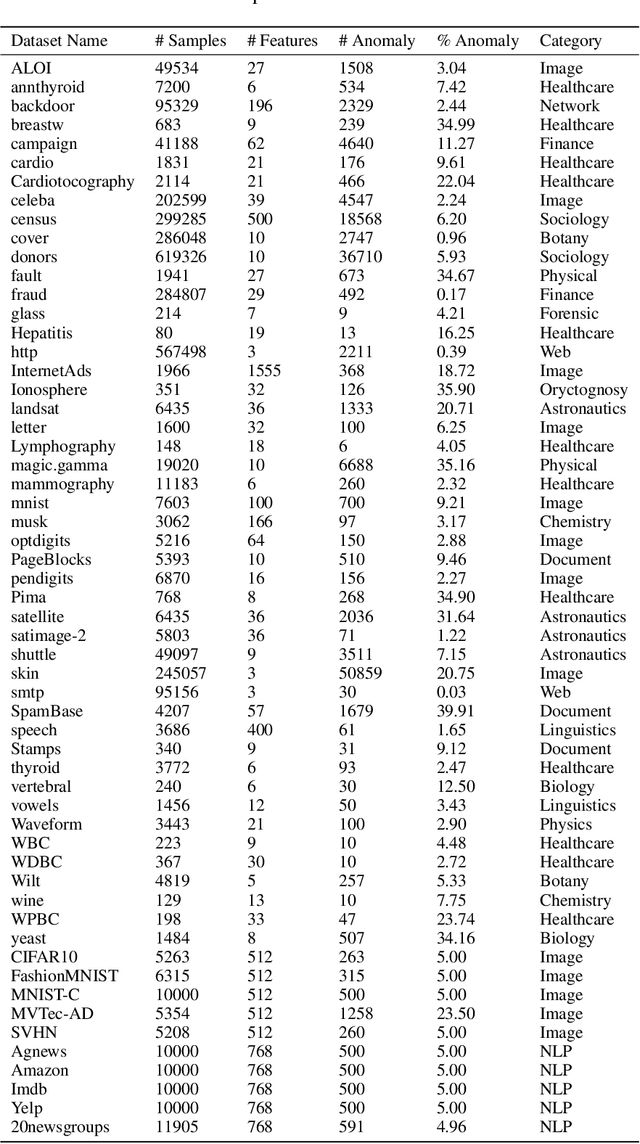
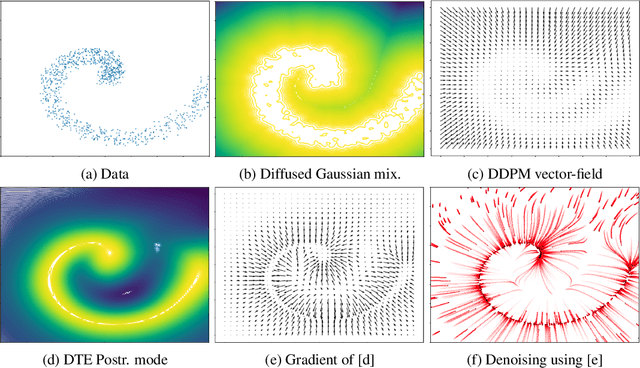
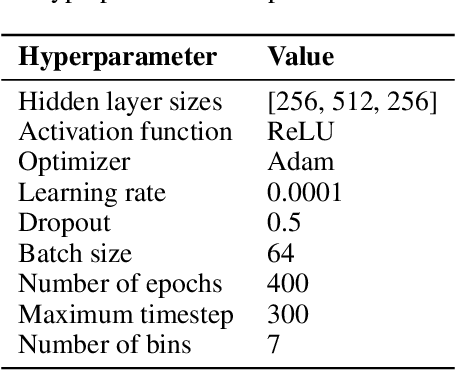
Known for their impressive performance in generative modeling, diffusion models are attractive candidates for density-based anomaly detection. This paper investigates different variations of diffusion modeling for unsupervised and semi-supervised anomaly detection. In particular, we find that Denoising Diffusion Probability Models (DDPM) are performant on anomaly detection benchmarks yet computationally expensive. By simplifying DDPM in application to anomaly detection, we are naturally led to an alternative approach called Diffusion Time Probabilistic Model (DTPM). DTPM estimates the posterior distribution over diffusion time for a given input, enabling the identification of anomalies due to their higher posterior density at larger timesteps. We derive an analytical form for this posterior density and leverage a deep neural network to improve inference efficiency. Through empirical evaluations on the ADBench benchmark, we demonstrate that all diffusion-based anomaly detection methods perform competitively. Notably, DTPM achieves orders of magnitude faster inference time than DDPM, while outperforming it on this benchmark. These results establish diffusion-based anomaly detection as an interpretable and scalable alternative to traditional methods and recent deep-learning techniques.
Mini-batch graphs for robust image classification
Apr 22, 2021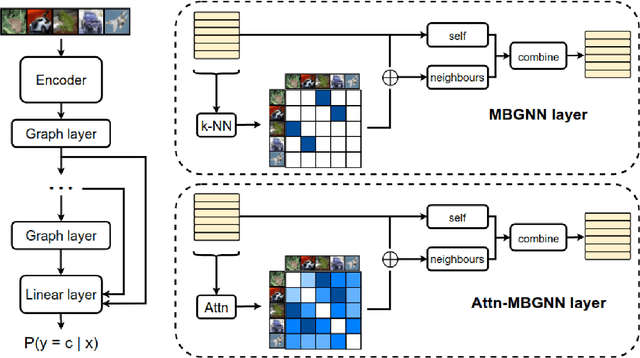
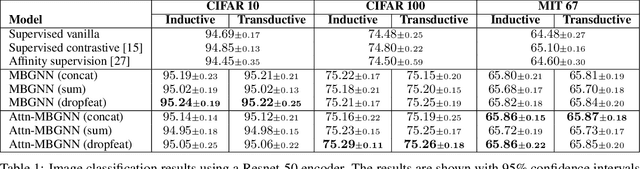
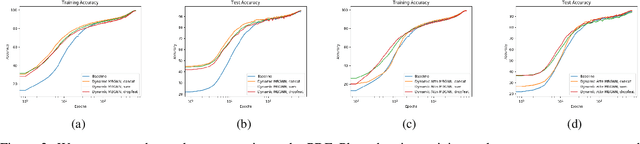

Current deep learning models for classification tasks in computer vision are trained using mini-batches. In the present article, we take advantage of the relationships between samples in a mini-batch, using graph neural networks to aggregate information from similar images. This helps mitigate the adverse effects of alterations to the input images on classification performance. Diverse experiments on image-based object and scene classification show that this approach not only improves a classifier's performance but also increases its robustness to image perturbations and adversarial attacks. Further, we also show that mini-batch graph neural networks can help to alleviate the problem of mode collapse in Generative Adversarial Networks.
Retinal Vessel Segmentation under Extreme Low Annotation: A Generative Adversarial Network Approach
Sep 05, 2018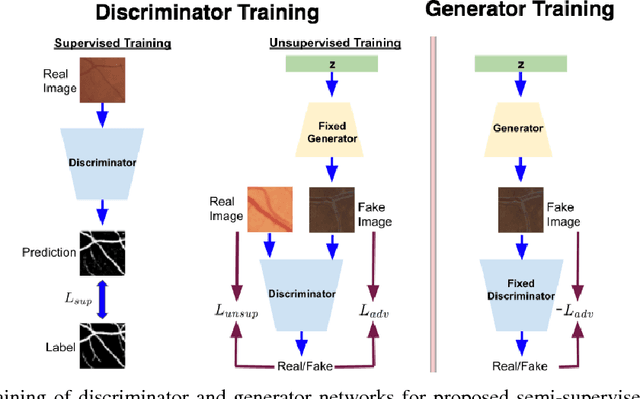
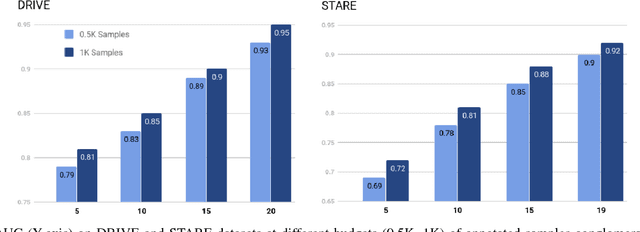
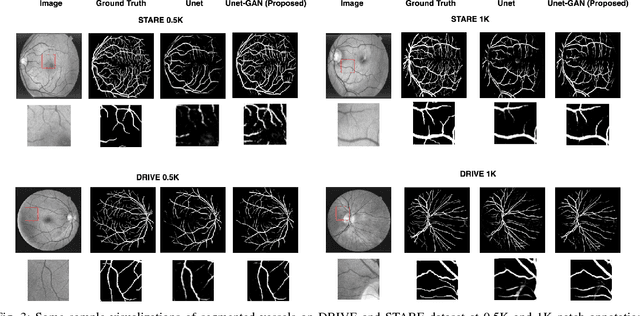

Contemporary deep learning based medical image segmentation algorithms require hours of annotation labor by domain experts. These data hungry deep models perform sub-optimally in the presence of limited amount of labeled data. In this paper, we present a data efficient learning framework using the recent concept of Generative Adversarial Networks; this allows a deep neural network to perform significantly better than its fully supervised counterpart in low annotation regime. The proposed method is an extension of our previous work with the addition of a new unsupervised adversarial loss and a structured prediction based architecture. To the best of our knowledge, this work is the first demonstration of an adversarial framework based structured prediction model for medical image segmentation. Though generic, we apply our method for segmentation of blood vessels in retinal fundus images. We experiment with extreme low annotation budget (0.8 - 1.6% of contemporary annotation size). On DRIVE and STARE datasets, the proposed method outperforms our previous method and other fully supervised benchmark models by significant margins especially with very low number of annotated examples. In addition, our systematic ablation studies suggest some key recipes for successfully training GAN based semi-supervised algorithms with an encoder-decoder style network architecture.