 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight-Field Dataset for Disparity Based Depth Estimation
Nov 08, 2025A Light Field (LF) camera consists of an additional two-dimensional array of micro-lenses placed between the main lens and sensor, compared to a conventional camera. The sensor pixels under each micro-lens receive light from a sub-aperture of the main lens. This enables the image sensor to capture both spatial information and the angular resolution of a scene point. This additional angular information is used to estimate the depth of a 3-D scene. The continuum of virtual viewpoints in light field data enables efficient depth estimation using Epipolar Line Images (EPIs) with robust occlusion handling. However, the trade-off between angular information and spatial information is very critical and depends on the focal position of the camera. To design, develop, implement, and test novel disparity-based light field depth estimation algorithms, the availability of suitable light field image datasets is essential. In this paper, a publicly available light field image dataset is introduced and thoroughly described. We have also demonstrated the effect of focal position on the disparity of a 3-D point as well as the shortcomings of the currently available light field dataset. The proposed dataset contains 285 light field images captured using a Lytro Illum LF camera and 13 synthetic LF images. The proposed dataset also comprises a synthetic dataset with similar disparity characteristics to those of a real light field camera. A real and synthetic stereo light field dataset is also created by using a mechanical gantry system and Blender. The dataset is available at https://github.com/aupendu/light-field-dataset.
Sharing the Learned Knowledge-base to Estimate Convolutional Filter Parameters for Continual Image Restoration
Nov 07, 2025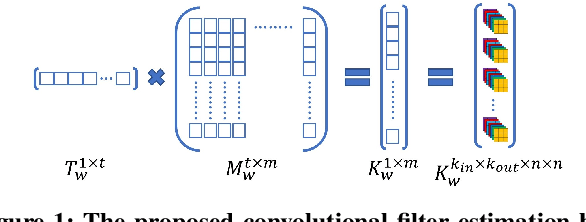
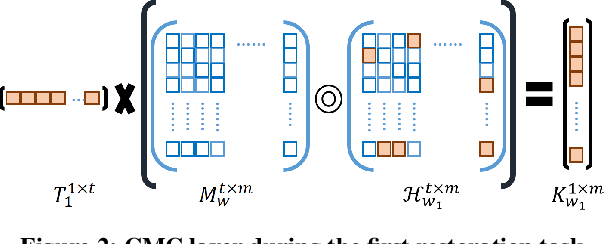
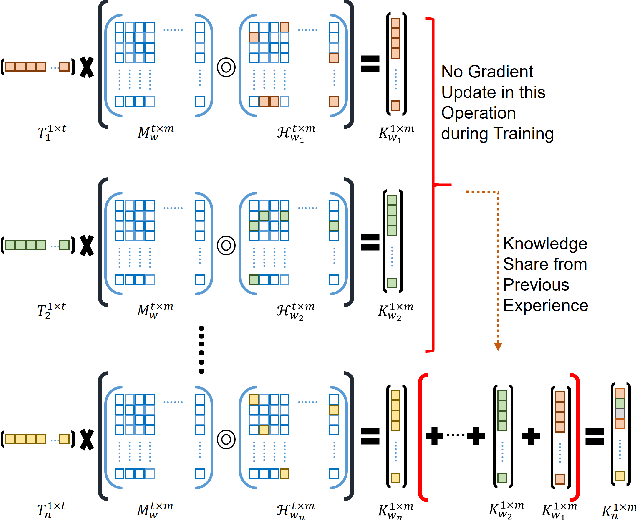
Continual learning is an emerging topic in the field of deep learning, where a model is expected to learn continuously for new upcoming tasks without forgetting previous experiences. This field has witnessed numerous advancements, but few works have been attempted in the direction of image restoration. Handling large image sizes and the divergent nature of various degradation poses a unique challenge in the restoration domain. However, existing works require heavily engineered architectural modifications for new task adaptation, resulting in significant computational overhead. Regularization-based methods are unsuitable for restoration, as different restoration challenges require different kinds of feature processing. In this direction, we propose a simple modification of the convolution layer to adapt the knowledge from previous restoration tasks without touching the main backbone architecture. Therefore, it can be seamlessly applied to any deep architecture without any structural modifications. Unlike other approaches, we demonstrate that our model can increase the number of trainable parameters without significantly increasing computational overhead or inference time. Experimental validation demonstrates that new restoration tasks can be introduced without compromising the performance of existing tasks. We also show that performance on new restoration tasks improves by adapting the knowledge from the knowledge base created by previous restoration tasks. The code is available at https://github.com/aupendu/continual-restore.
Variable Resolution Pixel Quantization for Low Power Machine Vision Application on Edge
Oct 07, 2024



This work describes an approach towards pixel quantization using variable resolution which is made feasible using image transformation in the analog domain. The main aim is to reduce the average bits-per-pixel (BPP) necessary for representing an image while maintaining the classification accuracy of a Convolutional Neural Network (CNN) that is trained for image classification. The proposed algorithm is based on the Hadamard transform that leads to a low-resolution variable quantization by the analog-to-digital converter (ADC) thus reducing the power dissipation in hardware at the sensor node. Despite the trade-offs inherent in image transformation, the proposed algorithm achieves competitive accuracy levels across various image sizes and ADC configurations, highlighting the importance of considering both accuracy and power consumption in edge computing applications. The schematic of a novel 1.5 bit ADC that incorporates the Hadamard transform is also proposed. A hardware implementation of the analog transformation followed by software-based variable quantization is done for the CIFAR-10 test dataset. The digitized data shows that the network can still identify transformed images with a remarkable 90% accuracy for 3-BPP transformed images following the proposed method.
Histopathological Image Analysis with Style-Augmented Feature Domain Mixing for Improved Generalization
Oct 31, 2023



Histopathological images are essential for medical diagnosis and treatment planning, but interpreting them accurately using machine learning can be challenging due to variations in tissue preparation, staining and imaging protocols. Domain generalization aims to address such limitations by enabling the learning models to generalize to new datasets or populations. Style transfer-based data augmentation is an emerging technique that can be used to improve the generalizability of machine learning models for histopathological images. However, existing style transfer-based methods can be computationally expensive, and they rely on artistic styles, which can negatively impact model accuracy. In this study, we propose a feature domain style mixing technique that uses adaptive instance normalization to generate style-augmented versions of images. We compare our proposed method with existing style transfer-based data augmentation methods and found that it performs similarly or better, despite requiring less computation and time. Our results demonstrate the potential of feature domain statistics mixing in the generalization of learning models for histopathological image analysis.
Self Supervised Low Dose Computed Tomography Image Denoising Using Invertible Network Exploiting Inter Slice Congruence
Nov 03, 2022The resurgence of deep neural networks has created an alternative pathway for low-dose computed tomography denoising by learning a nonlinear transformation function between low-dose CT (LDCT) and normal-dose CT (NDCT) image pairs. However, those paired LDCT and NDCT images are rarely available in the clinical environment, making deep neural network deployment infeasible. This study proposes a novel method for self-supervised low-dose CT denoising to alleviate the requirement of paired LDCT and NDCT images. Specifically, we have trained an invertible neural network to minimize the pixel-based mean square distance between a noisy slice and the average of its two immediate adjacent noisy slices. We have shown the aforementioned is similar to training a neural network to minimize the distance between clean NDCT and noisy LDCT image pairs. Again, during the reverse mapping of the invertible network, the output image is mapped to the original input image, similar to cycle consistency loss. Finally, the trained invertible network's forward mapping is used for denoising LDCT images. Extensive experiments on two publicly available datasets showed that our method performs favourably against other existing unsupervised methods.
Sub-Aperture Feature Adaptation in Single Image Super-resolution Model for Light Field Imaging
Jul 26, 2022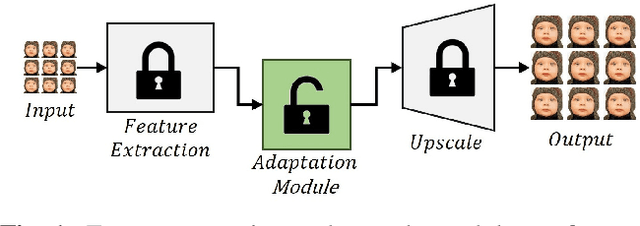
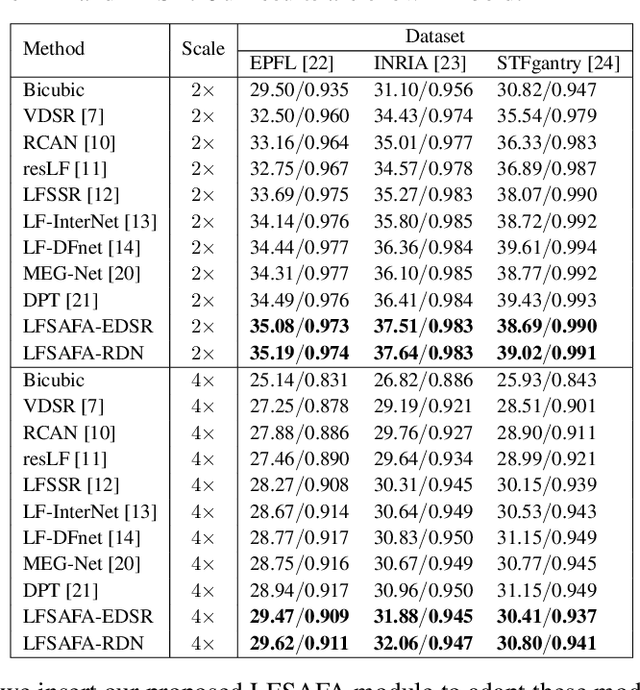
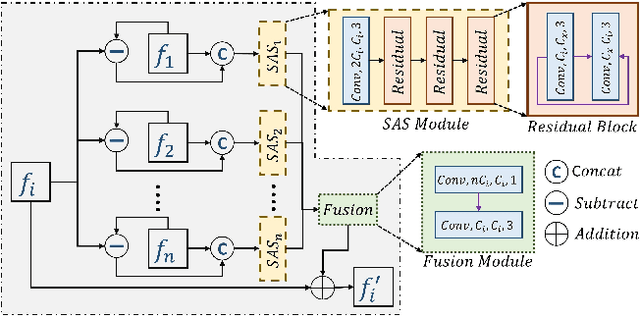
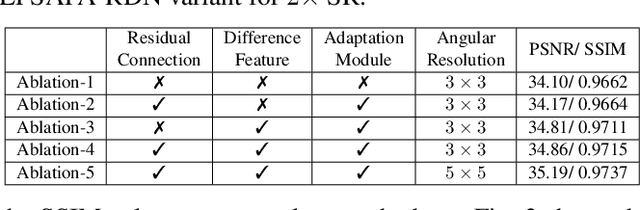
With the availability of commercial Light Field (LF) cameras, LF imaging has emerged as an up and coming technology in computational photography. However, the spatial resolution is significantly constrained in commercial microlens based LF cameras because of the inherent multiplexing of spatial and angular information. Therefore, it becomes the main bottleneck for other applications of light field cameras. This paper proposes an adaptation module in a pretrained Single Image Super Resolution (SISR) network to leverage the powerful SISR model instead of using highly engineered light field imaging domain specific Super Resolution models. The adaption module consists of a Sub aperture Shift block and a fusion block. It is an adaptation in the SISR network to further exploit the spatial and angular information in LF images to improve the super resolution performance. Experimental validation shows that the proposed method outperforms existing light field super resolution algorithms. It also achieves PSNR gains of more than 1 dB across all the datasets as compared to the same pretrained SISR models for scale factor 2, and PSNR gains 0.6 to 1 dB for scale factor 4.
Texture Aware Autoencoder Pre-training And Pairwise Learning Refinement For Improved Iris Recognition
Feb 15, 2022


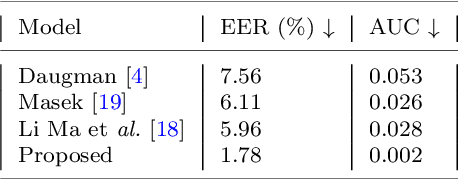
This paper presents a texture aware end-to-end trainable iris recognition system, specifically designed for datasets like iris having limited training data. We build upon our previous stagewise learning framework with certain key optimization and architectural innovations. First, we pretrain a Stage-1 encoder network with an unsupervised autoencoder learning optimized with an additional data relation loss on top of usual reconstruction loss. The data relation loss enables learning better texture representation which is pivotal for a texture rich dataset such as iris. Robustness of Stage-1 feature representation is further enhanced with an auxiliary denoising task. Such pre-training proves beneficial for effectively training deep networks on data constrained iris datasets. Next, in Stage-2 supervised refinement, we design a pairwise learning architecture for an end-to-end trainable iris recognition system. The pairwise learning includes the task of iris matching inside the training pipeline itself and results in significant improvement in recognition performance compared to usual offline matching. We validate our model across three publicly available iris datasets and the proposed model consistently outperforms both traditional and deep learning baselines for both Within-Dataset and Cross-Dataset configurations
Iterative Gradient Encoding Network with Feature Co-Occurrence Loss for Single Image Reflection Removal
Mar 29, 2021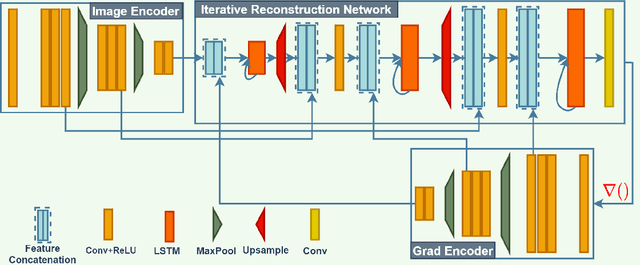



Removing undesired reflections from a photo taken in front of glass is of great importance for enhancing visual computing systems' efficiency. Previous learning-based approaches have produced visually plausible results for some reflections type, however, failed to generalize against other reflection types. There is a dearth of literature for efficient methods concerning single image reflection removal, which can generalize well in large-scale reflection types. In this study, we proposed an iterative gradient encoding network for single image reflection removal. Next, to further supervise the network in learning the correlation between the transmission layer features, we proposed a feature co-occurrence loss. Extensive experiments on the public benchmark dataset of SIR$^2$ demonstrated that our method can remove reflection favorably against the existing state-of-the-art method on all imaging settings, including diverse backgrounds. Moreover, as the reflection strength increases, our method can still remove reflection even where other state of the art methods failed.
A Novel Approach for Earthquake Early Warning System Design using Deep Learning Techniques
Jan 16, 2021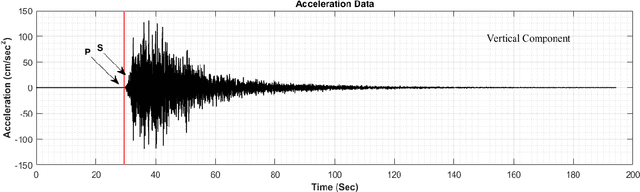
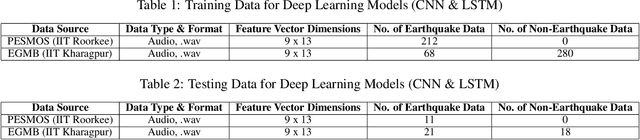
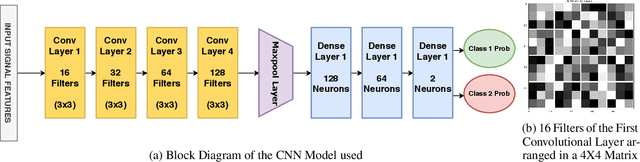
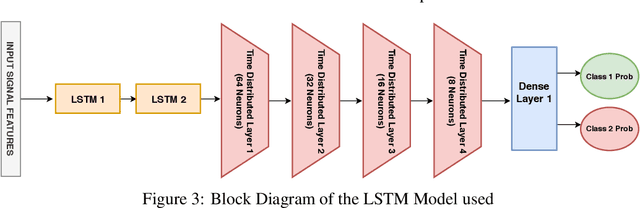
Earthquake signals are non-stationary in nature and thus in real-time, it is difficult to identify and classify events based on classical approaches like peak ground displacement, peak ground velocity. Even the popular algorithm of STA/LTA requires extensive research to determine basic thresholding parameters so as to trigger an alarm. Also, many times due to human error or other unavoidable natural factors such as thunder strikes or landslides, the algorithm may end up raising a false alarm. This work focuses on detecting earthquakes by converting seismograph recorded data into corresponding audio signals for better perception and then uses popular Speech Recognition techniques of Filter bank coefficients and Mel Frequency Cepstral Coefficients (MFCC) to extract the features. These features were then used to train a Convolutional Neural Network(CNN) and a Long Short Term Memory(LSTM) network. The proposed method can overcome the above-mentioned problems and help in detecting earthquakes automatically from the waveforms without much human intervention. For the 1000Hz audio data set the CNN model showed a testing accuracy of 91.1% for 0.2-second sample window length while the LSTM model showed 93.99% for the same. A total of 610 sounds consisting of 310 earthquake sounds and 300 non-earthquake sounds were used to train the models. While testing, the total time required for generating the alarm was approximately 2 seconds which included individual times for data collection, processing, and prediction taking into consideration the processing and prediction delays. This shows the effectiveness of the proposed method for Earthquake Early Warning (EEW) applications. Since the input of the method is only the waveform, it is suitable for real-time processing, thus the models can also be used as an onsite EEW system requiring a minimum amount of preparation time and workload.
Noise Conscious Training of Non Local Neural Network powered by Self Attentive Spectral Normalized Markovian Patch GAN for Low Dose CT Denoising
Nov 11, 2020
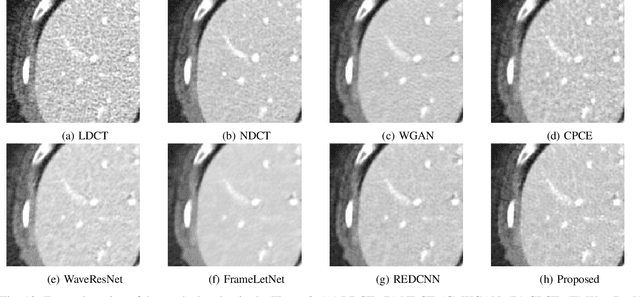
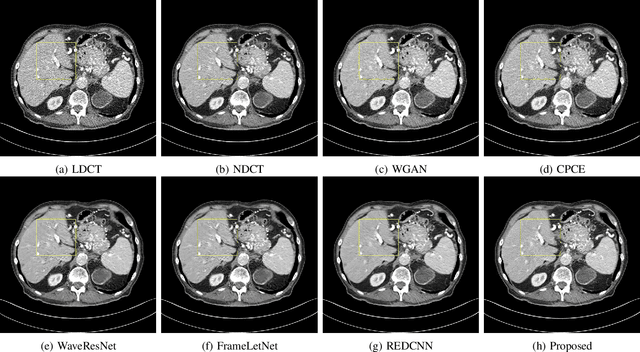
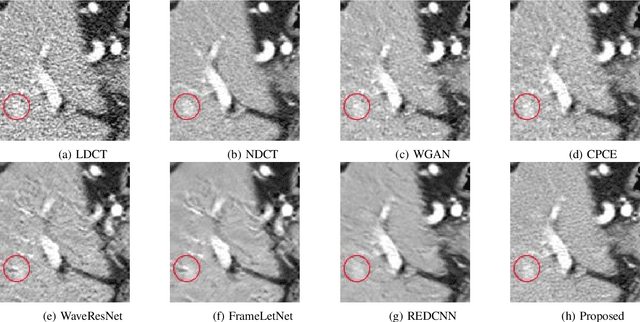
The explosive rise of the use of Computer tomography (CT) imaging in medical practice has heightened public concern over the patient's associated radiation dose. However, reducing the radiation dose leads to increased noise and artifacts, which adversely degrades the scan's interpretability. Consequently, an advanced image reconstruction algorithm to improve the diagnostic performance of low dose ct arose as the primary concern among the researchers, which is challenging due to the ill-posedness of the problem. In recent times, the deep learning-based technique has emerged as a dominant method for low dose CT(LDCT) denoising. However, some common bottleneck still exists, which hinders deep learning-based techniques from furnishing the best performance. In this study, we attempted to mitigate these problems with three novel accretions. First, we propose a novel convolutional module as the first attempt to utilize neighborhood similarity of CT images for denoising tasks. Our proposed module assisted in boosting the denoising by a significant margin. Next, we moved towards the problem of non-stationarity of CT noise and introduced a new noise aware mean square error loss for LDCT denoising. Moreover, the loss mentioned above also assisted to alleviate the laborious effort required while training CT denoising network using image patches. Lastly, we propose a novel discriminator function for CT denoising tasks. The conventional vanilla discriminator tends to overlook the fine structural details and focus on the global agreement. Our proposed discriminator leverage self-attention and pixel-wise GANs for restoring the diagnostic quality of LDCT images. Our method validated on a publicly available dataset of the 2016 NIH-AAPM-Mayo Clinic Low Dose CT Grand Challenge performed remarkably better than the existing state of the art method.