 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Approach for Earthquake Early Warning System Design using Deep Learning Techniques
Paper and Code
Jan 16, 2021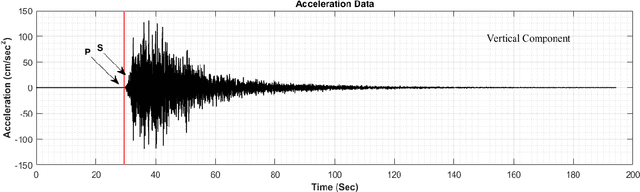
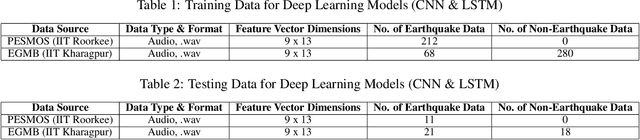
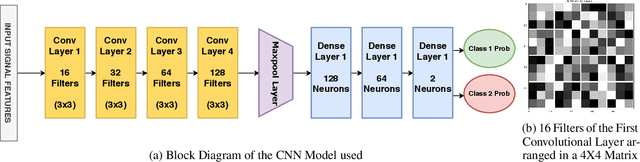
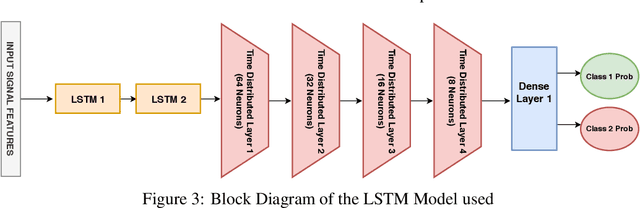
Earthquake signals are non-stationary in nature and thus in real-time, it is difficult to identify and classify events based on classical approaches like peak ground displacement, peak ground velocity. Even the popular algorithm of STA/LTA requires extensive research to determine basic thresholding parameters so as to trigger an alarm. Also, many times due to human error or other unavoidable natural factors such as thunder strikes or landslides, the algorithm may end up raising a false alarm. This work focuses on detecting earthquakes by converting seismograph recorded data into corresponding audio signals for better perception and then uses popular Speech Recognition techniques of Filter bank coefficients and Mel Frequency Cepstral Coefficients (MFCC) to extract the features. These features were then used to train a Convolutional Neural Network(CNN) and a Long Short Term Memory(LSTM) network. The proposed method can overcome the above-mentioned problems and help in detecting earthquakes automatically from the waveforms without much human intervention. For the 1000Hz audio data set the CNN model showed a testing accuracy of 91.1% for 0.2-second sample window length while the LSTM model showed 93.99% for the same. A total of 610 sounds consisting of 310 earthquake sounds and 300 non-earthquake sounds were used to train the models. While testing, the total time required for generating the alarm was approximately 2 seconds which included individual times for data collection, processing, and prediction taking into consideration the processing and prediction delays. This shows the effectiveness of the proposed method for Earthquake Early Warning (EEW) applications. Since the input of the method is only the waveform, it is suitable for real-time processing, thus the models can also be used as an onsite EEW system requiring a minimum amount of preparation time and workload.