 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Key Postures of Bharatanatyam Adavus with Pose Estimation
Mar 31, 2026Preserving intangible cultural dances rooted in centuries of tradition and governed by strict structural and symbolic rules presents unique challenges in the digital era. Among these, Bharatanatyam, a classical Indian dance form, stands out for its emphasis on codified adavus and precise key postures. Accurately generating these postures is crucial not only for maintaining anatomical and stylistic integrity, but also for enabling effective documentation, analysis, and transmission to broader global audiences through digital means. We propose a pose-aware generative framework integrated with a pose estimation module, guided by keypoint-based loss and pose consistency constraints. These supervisory signals ensure anatomical accuracy and stylistic integrity in the synthesized outputs. We evaluate four configurations: standard conditional generative adversarial network (cGAN), cGAN with pose supervision, conditional diffusion, and conditional diffusion with pose supervision. Each model is conditioned on key posture class labels and optimized to maintain geometric structure. In both cGAN and conditional diffusion settings, the integrated pose guidance aligns generated poses with ground-truth keypoint structures, promoting cultural fidelity. Our results demonstrate that incorporating pose supervision significantly enhances the quality, realism, and authenticity of generated Bharatanatyam postures. This framework provides a scalable approach for the digital preservation, education, and dissemination of traditional dance forms, enabling high-fidelity generation without compromising cultural precision. Code is available at https://github.com/jagidsh/Generating-Key-Postures-of-Bharatanatyam-Adavus-with-Pose-Estimation.
* Published in ICVGIP, 2025
Light-Field Dataset for Disparity Based Depth Estimation
Nov 08, 2025A Light Field (LF) camera consists of an additional two-dimensional array of micro-lenses placed between the main lens and sensor, compared to a conventional camera. The sensor pixels under each micro-lens receive light from a sub-aperture of the main lens. This enables the image sensor to capture both spatial information and the angular resolution of a scene point. This additional angular information is used to estimate the depth of a 3-D scene. The continuum of virtual viewpoints in light field data enables efficient depth estimation using Epipolar Line Images (EPIs) with robust occlusion handling. However, the trade-off between angular information and spatial information is very critical and depends on the focal position of the camera. To design, develop, implement, and test novel disparity-based light field depth estimation algorithms, the availability of suitable light field image datasets is essential. In this paper, a publicly available light field image dataset is introduced and thoroughly described. We have also demonstrated the effect of focal position on the disparity of a 3-D point as well as the shortcomings of the currently available light field dataset. The proposed dataset contains 285 light field images captured using a Lytro Illum LF camera and 13 synthetic LF images. The proposed dataset also comprises a synthetic dataset with similar disparity characteristics to those of a real light field camera. A real and synthetic stereo light field dataset is also created by using a mechanical gantry system and Blender. The dataset is available at https://github.com/aupendu/light-field-dataset.
Sub-Aperture Feature Adaptation in Single Image Super-resolution Model for Light Field Imaging
Jul 26, 2022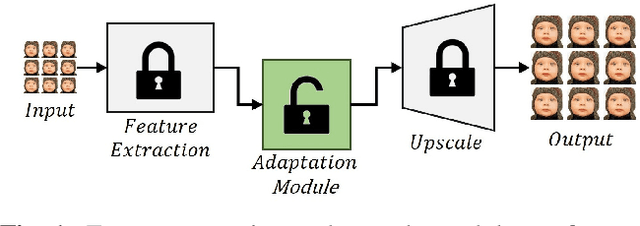
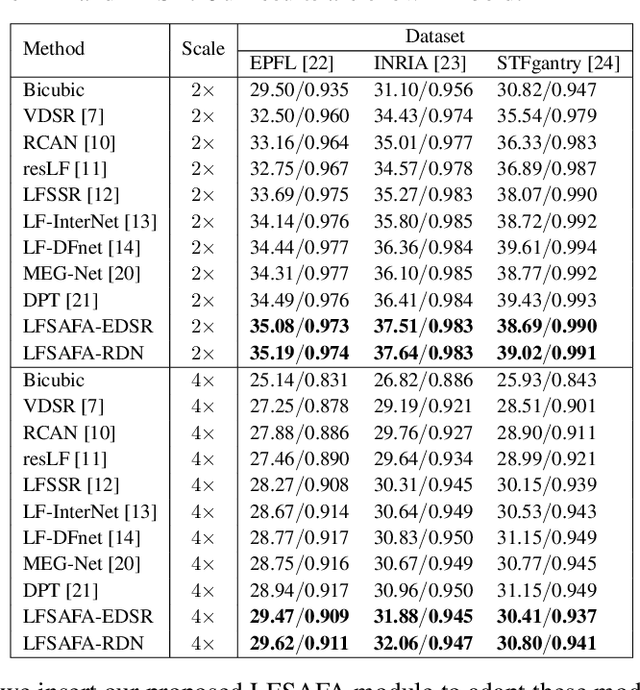
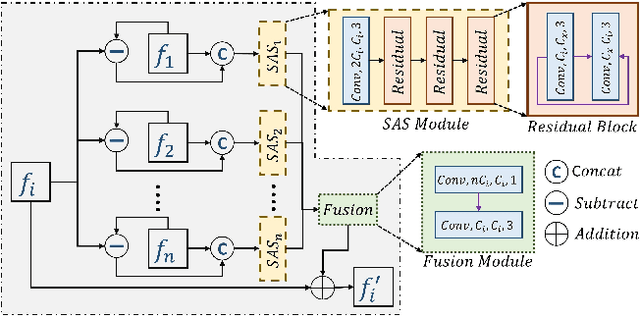
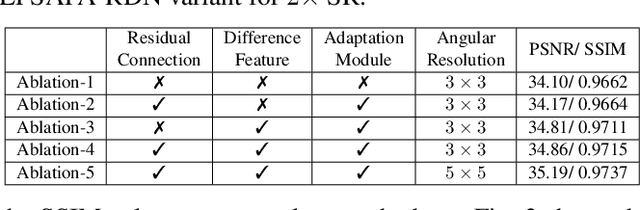
With the availability of commercial Light Field (LF) cameras, LF imaging has emerged as an up and coming technology in computational photography. However, the spatial resolution is significantly constrained in commercial microlens based LF cameras because of the inherent multiplexing of spatial and angular information. Therefore, it becomes the main bottleneck for other applications of light field cameras. This paper proposes an adaptation module in a pretrained Single Image Super Resolution (SISR) network to leverage the powerful SISR model instead of using highly engineered light field imaging domain specific Super Resolution models. The adaption module consists of a Sub aperture Shift block and a fusion block. It is an adaptation in the SISR network to further exploit the spatial and angular information in LF images to improve the super resolution performance. Experimental validation shows that the proposed method outperforms existing light field super resolution algorithms. It also achieves PSNR gains of more than 1 dB across all the datasets as compared to the same pretrained SISR models for scale factor 2, and PSNR gains 0.6 to 1 dB for scale factor 4.
Deriving Explanation of Deep Visual Saliency Models
Sep 08, 2021



Deep neural networks have shown their profound impact on achieving human level performance in visual saliency prediction. However, it is still unclear how they learn the task and what it means in terms of understanding human visual system. In this work, we develop a technique to derive explainable saliency models from their corresponding deep neural architecture based saliency models by applying human perception theories and the conventional concepts of saliency. This technique helps us understand the learning pattern of the deep network at its intermediate layers through their activation maps. Initially, we consider two state-of-the-art deep saliency models, namely UNISAL and MSI-Net for our interpretation. We use a set of biologically plausible log-gabor filters for identifying and reconstructing the activation maps of them using our explainable saliency model. The final saliency map is generated using these reconstructed activation maps. We also build our own deep saliency model named cross-concatenated multi-scale residual block based network (CMRNet) for saliency prediction. Then, we evaluate and compare the performance of the explainable models derived from UNISAL, MSI-Net and CMRNet on three benchmark datasets with other state-of-the-art methods. Hence, we propose that this approach of explainability can be applied to any deep visual saliency model for interpretation which makes it a generic one.
Tabular Structure Detection from Document Images for Resource Constrained Devices Using A Row Based Similarity Measure
Aug 26, 2020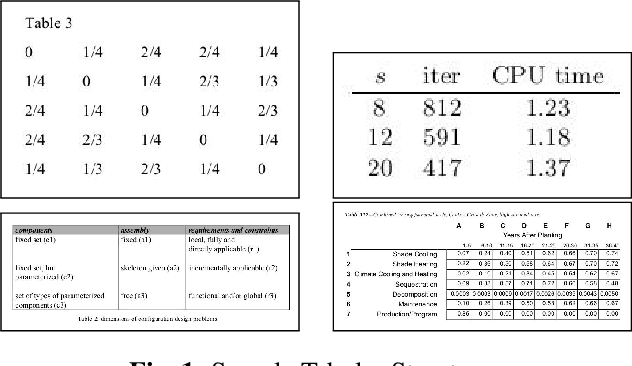
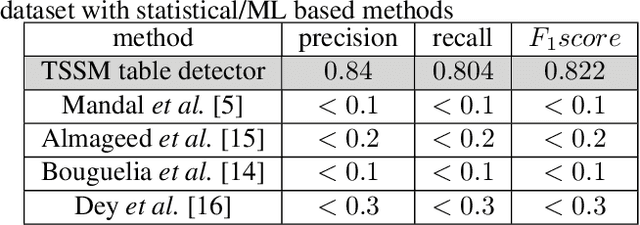

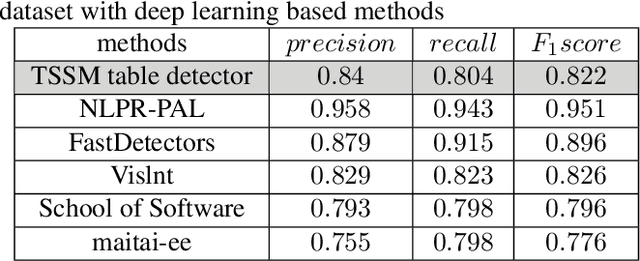
Tabular structures are used to present crucial information in a structured and crisp manner. Detection of such regions is of great importance for proper understanding of a document. Tabular structures can be of various layouts and types. Therefore, detection of these regions is a hard problem. Most of the existing techniques detect tables from a document image by using prior knowledge of the structures of the tables. However, these methods are not applicable for generalized tabular structures. In this work, we propose a similarity measure to find similarities between pairs of rows in a tabular structure. This similarity measure is utilized to identify a tabular region. Since the tabular regions are detected exploiting the similarities among all rows, the method is inherently independent of layouts of the tabular regions present in the training data. Moreover, the proposed similarity measure can be used to identify tabular regions without using large sets of parameters associated with recent deep learning based methods. Thus, the proposed method can easily be used with resource constrained devices such as mobile devices without much of an overhead.
RECAL: Reuse of Established CNN classifer Apropos unsupervised Learning paradigm
Jun 15, 2019

Recently, clustering with deep network framework has attracted attention of several researchers in the computer vision community. Deep framework gains extensive attention due to its efficiency and scalability towards large-scale and high-dimensional data. In this paper, we transform supervised CNN classifier architecture into an unsupervised clustering model, called RECAL, which jointly learns discriminative embedding subspace and cluster labels. RECAL is made up of feature extraction layers which are convolutional, followed by unsupervised classifier layers which is fully connected. A multinomial logistic regression function (softmax) stacked on top of classifier layers. We train this network using stochastic gradient descent (SGD) optimizer. However, the successful implementation of our model is revolved around the design of loss function. Our loss function uses the heuristics that true partitioning entails lower entropy given that the class distribution is not heavily skewed. This is a trade-off between the situations of "skewed distribution" and "low-entropy". To handle this, we have proposed classification entropy and class entropy which are the two components of our loss function. In this approach, size of the mini-batch should be kept high. Experimental results indicate the consistent and competitive behavior of our model for clustering well-known digit, multi-viewed object and face datasets. Morever, we use this model to generate unsupervised patch segmentation for multi-spectral LISS-IV images. We observe that it is able to distinguish built-up area, wet land, vegetation and waterbody from the underlying scene.
Efficient Retrieval of Logos Using Rough Set Reducts
Apr 10, 2019

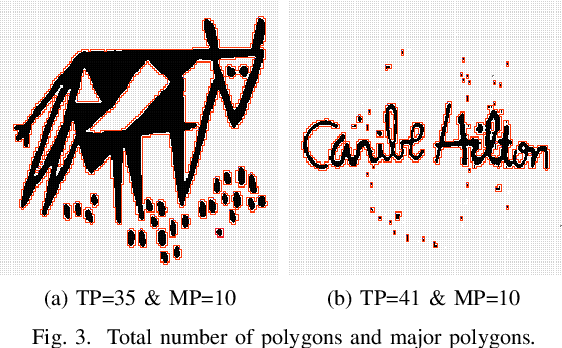

Searching for similar logos in the registered logo database is a very important and tedious task at the trademark office. Speed and accuracy are two aspects that one must attend to while developing a system for retrieval of logos. In this paper, we propose a rough-set based method to quantify the structural information in a logo image that can be used to efficiently index an image. A logo is split into a number of polygons, and for each polygon, we compute the tight upper and lower approximations based on the principles of a rough set. This representation is used for forming feature vectors for retrieval of logos. Experimentation on a standard data set shows the usefulness of the proposed technique. It is computationally efficient and also provides retrieval results at high accuracy.
Visual Based Navigation of Mobile Robots
Dec 15, 2017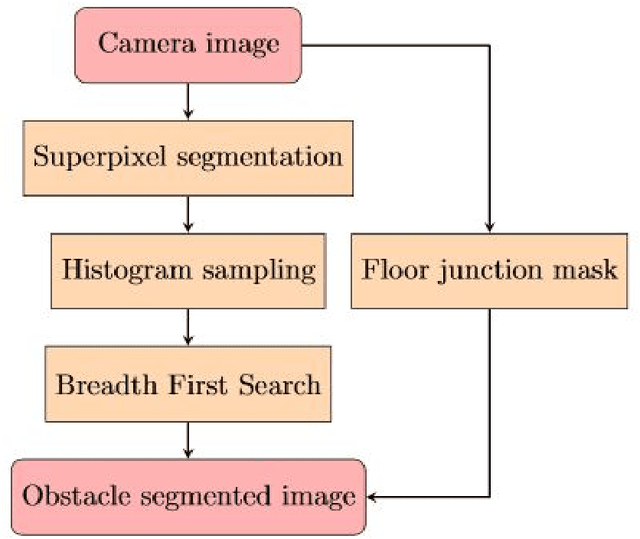



We have developed an algorithm to generate a complete map of the traversable region for a personal assistant robot using monocular vision only. Using multiple taken by a simple webcam, obstacle detection and avoidance algorithms have been developed. Simple Linear Iterative Clustering (SLIC) has been used for segmentation to reduce the memory and computation cost. A simple mapping technique using inverse perspective mapping and occupancy grids, which is robust, and supports very fast updates has been used to create the map for indoor navigation.
Bayesian Optimisation with Prior Reuse for Motion Planning in Robot Soccer
Oct 18, 2017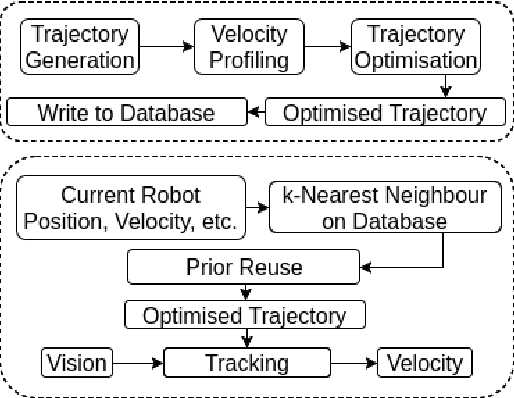

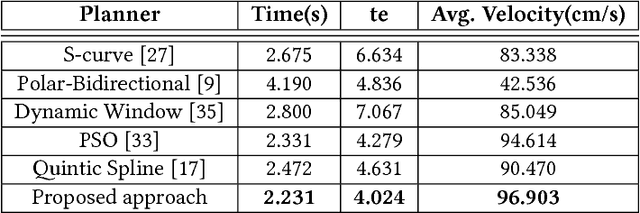
We integrate learning and motion planning for soccer playing differential drive robots using Bayesian optimisation. Trajectories generated using end-slope cubic Bezier splines are first optimised globally through Bayesian optimisation for a set of candidate points with obstacles. The optimised trajectories along with robot and obstacle positions and velocities are stored in a database. The closest planning situation is identified from the database using k-Nearest Neighbour approach. It is further optimised online through reuse of prior information from previously optimised trajectory. Our approach reduces computation time of trajectory optimisation considerably. Velocity profiling generates velocities consistent with robot kinodynamoic constraints, and avoids collision and slipping. Extensive testing is done on developed simulator, as well as on physical differential drive robots. Our method shows marked improvements in mitigating tracking error, and reducing traversal and computational time over competing techniques under the constraints of performing tasks in real time.
5-DoF Monocular Visual Localization Over Grid Based Floor
Sep 14, 2017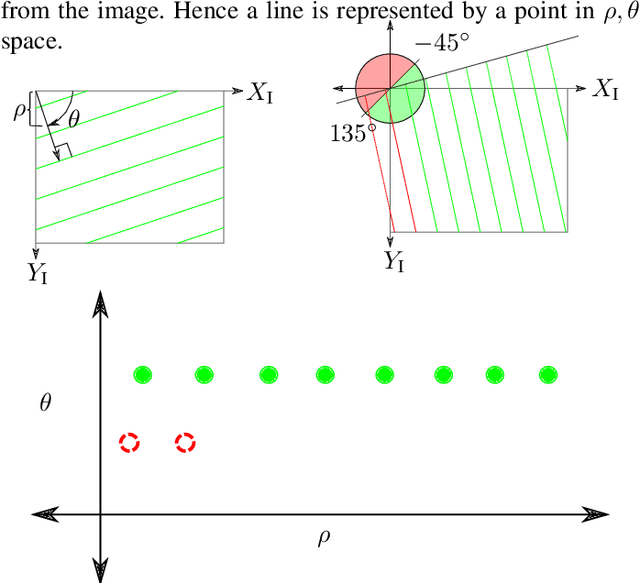
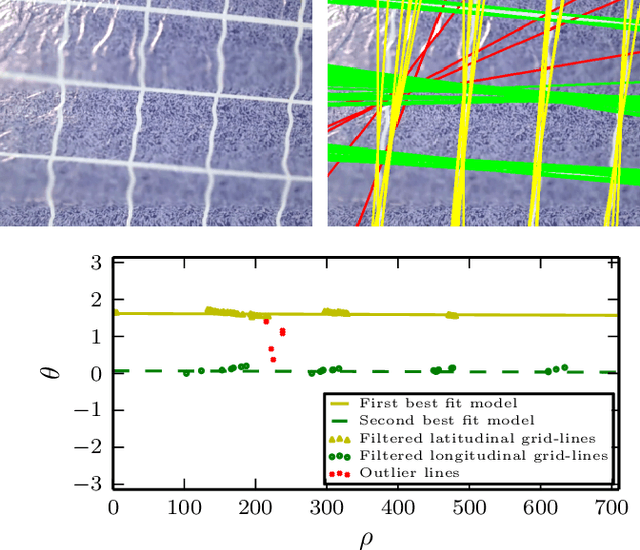

Reliable localization is one of the most important parts of an MAV system. Localization in an indoor GPS-denied environment is a relatively difficult problem. Current vision based algorithms track optical features to calculate odometry. We present a novel localization method which can be applied in an environment having orthogonal sets of equally spaced lines to form a grid. With the help of a monocular camera and using the properties of the grid-lines below, the MAV is localized inside each sub-cell of the grid and consequently over the entire grid for a relative localization over the grid. We demonstrate the effectiveness of our system onboard a customized MAV platform. The experimental results show that our method provides accurate 5-DoF localization over grid lines and it can be performed in real-time.