 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabular Structure Detection from Document Images for Resource Constrained Devices Using A Row Based Similarity Measure
Paper and Code
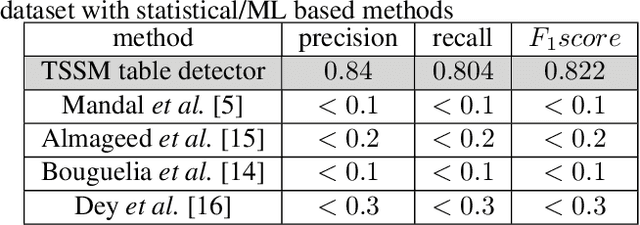

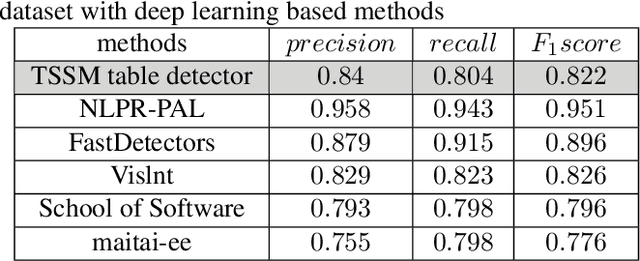
Tabular structures are used to present crucial information in a structured and crisp manner. Detection of such regions is of great importance for proper understanding of a document. Tabular structures can be of various layouts and types. Therefore, detection of these regions is a hard problem. Most of the existing techniques detect tables from a document image by using prior knowledge of the structures of the tables. However, these methods are not applicable for generalized tabular structures. In this work, we propose a similarity measure to find similarities between pairs of rows in a tabular structure. This similarity measure is utilized to identify a tabular region. Since the tabular regions are detected exploiting the similarities among all rows, the method is inherently independent of layouts of the tabular regions present in the training data. Moreover, the proposed similarity measure can be used to identify tabular regions without using large sets of parameters associated with recent deep learning based methods. Thus, the proposed method can easily be used with resource constrained devices such as mobile devices without much of an overhead.